第1关:外部指标
任务描述
本关任务:填写 python 代码,完成 calc_JC 函数、calc_FM 函数和 calc_Rand 函数分别实现计算 JC系数、FM 指数 和 Rand 指数 。
相关知识
为了完成本关任务,你需要掌握:
JC 系数;
FM 指数;
Rand 指数。
外部指标
聚类的性能度量大致分为两类:一类是将聚类结果与某个参考模型作为参照进行比较,也就是所谓的外部指标;另一类则是直接度量聚类的性能而不使用参考模型进行比较,也就是内部指标。外部指标通常使用 Jaccard Coefficient ( JC系数 )、 Fowlkes and Mallows Index ( FM指数 )以及 Rand index ( Rand指数 )。
想要计算上述指标来度量聚类的性能,首先需要计算出a,c,d,e。假设数据集E={x1,x2,…,xm}。通过聚类模型给出的簇划分为C={C1,C2,…Ck},参考模型给出的簇划分为D={D1,D2,…D s}。λ与λ ∗分别表示C与D对应的簇标记,则有:
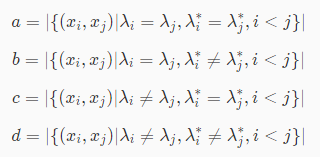
举个例子,参考模型给出的簇与聚类模型给出的簇划分如下:
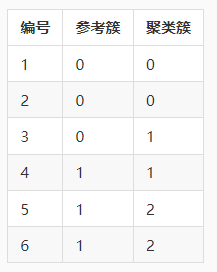
那么满足a的样本对为(1,2)(因为1号样本与2号样本的参考簇都为0,聚类簇都为0),(5,6)(因为5号样本与6号样本的参考簇都为1,聚类簇都为2)。总共有2个样本对满足a,因此a=2。
满足b的样本对为(3,4)(因为3号样本与4号样本的参考簇不同,但聚类簇都为1)。总共有1个样本对满足b,因此b=1。
那么满足c的样本对为(1,3)(因为1号样本与3号样本的聚类簇不同,但参考簇都为0),(2,3)(因为2号样本与3号样本的聚类簇不同,但参考簇都为0),(4,5)(因为4号样本与5号样本的聚类簇不同,但参考簇都为1),(4,6)(因为4号样本与6号样本的聚类簇不同,但参考簇都为1)。总共有4个样本对满足c,因此c=4。
满足d的样本对为(1,4)(因为1号样本与4号样本的参考簇不同,聚类簇也不同),(1,5)(因为1号样本与5号样本的参考簇不同,聚类簇也不同),(1,6)(因为1号样本与6号样本的参考簇不同,聚类簇也不同),(2,4)(因为2号样本与4号样本的参考簇不同,聚类簇也不同),(2,5)(因为2号样本与5号样本的参考簇不同,聚类簇也不同),(2,6)(因为2号样本与6号样本的参考簇不同,聚类簇也不同),(3,5)(因为3号样本与5号样本的参考簇不同,聚类簇也不同),(3,6)(因为3号样本与6号样本的参考簇不同,聚类簇也不同)。总共有8个样本对满足d,因此d=8。
JC系数
JC系数根据上面所提到的a,b,c来计算,并且值域为[0,1],值越大说明聚类性能越好,公式如下:
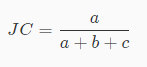
因此刚刚的例子中,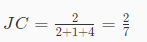
FM指数
FM指数根据上面所提到的a,b,c来计算,并且值域为[0,1],值越大说明聚类性能越好,公式如下:
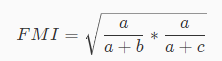
因此刚刚的例子中,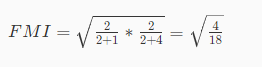
Rand指数
Rand指数根据上面所提到的a和d来计算,并且值域为[0,1],值越大说明聚类性能越好,假设m为样本数量,公式如下:
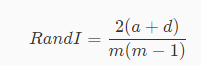
因此刚刚的例子中,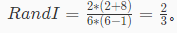
编程要求
根据提示在 begin-end 之间填写 python 代码,完成 calc_JC 函数、 calc_FM 函数和 calc_Rand 函数分别实现计算 JC 系数 、FM 指数 和 Rand 指数 并返回。
calc_JC 函数中的参数:
y_true :参考模型给出的簇,类型为 ndarray;
y_pred :聚类模型给出的簇,类型为 ndarray;
return : JC系数 ,类型为 float。
calc_FM 函数中的参数:
y_true :参考模型给出的簇,类型为 ndarray;
y_pred :聚类模型给出的簇,类型为 ndarray;
return : FM指数 ,类型为 float。
calc_Rand 函数中的参数:
y_true :参考模型给出的簇,类型为 ndarray;
y_pred :聚类模型给出的簇,类型为 ndarray;
return : Rand指数 ,类型为 float。
测试说明
只需完成 calc_JC 函数、 calc_FM 函数和 calc_Rand 函数即可,平台会对你编写的代码进行测试,并会按顺序打印 JC系数 、 FM 指数 和 Rand 指数 。以下为其中一个测试用例( y_true 表示参考模型给出的簇,y_pred 表示聚类模型给出的簇):
测试输入:
{‘y_true’:[0, 0, 0, 1, 1, 1], ‘y_pred’:[0, 0, 1, 1, 2, 2]}
预期输出:
0.285714 0.471405 0.666667
开始你的任务吧,祝你成功!
import numpy as npdef calc_JC(y_true, y_pred):'''计算并返回JC系数:param y_true: 参考模型给出的簇,类型为ndarray:param y_pred: 聚类模型给出的簇,类型为ndarray:return: JC系数'''#******** Begin *******#a,b,c = 0,0,0for i in range(len(y_true)):for j in range(i+1,len(y_true)):if y_true[i] == y_true[j] and y_pred[i] == y_pred[j]:a += 1elif y_true[i] != y_true[j] and y_pred[i] == y_pred[j]:b += 1elif y_true[i] == y_true[j] and y_pred[i] != y_pred[j]:c += 1jc = a/(a+b+c)return jc#******** End *******#def calc_FM(y_true, y_pred):'''计算并返回FM指数:param y_true: 参考模型给出的簇,类型为ndarray:param y_pred: 聚类模型给出的簇,类型为ndarray:return: FM指数'''#******** Begin *******#a,b,c = 0,0,0for i in range(len(y_true)):for j in range(i+1,len(y_true)):if y_true[i] == y_true[j] and y_pred[i] == y_pred[j]:a += 1elif y_true[i] != y_true[j] and y_pred[i] == y_pred[j]:b += 1elif y_true[i] == y_true[j] and y_pred[i] != y_pred[j]:c += 1fm = np.sqrt(a/(a+b)*a/(a+c))return fm#******** End *******#def calc_Rand(y_true, y_pred):'''计算并返回Rand指数:param y_true: 参考模型给出的簇,类型为ndarray:param y_pred: 聚类模型给出的簇,类型为ndarray:return: Rand指数'''#******** Begin *******#a,d = 0,0m = len(y_true)for i in range(m):for j in range(i+1,m):if y_true[i] == y_true[j] and y_pred[i] == y_pred[j]:a += 1elif y_true[i] != y_true[j] and y_pred[i] != y_pred[j]:d += 1rand = (2*(a+d))/(m*(m-1))return rand#******** End *******#
第2关:内部指标
任务描述
本关任务:填写 python 代码,完成 calc_DBI 函数和 calc_DI 函数分别实现计算 DB 指数 和 Dunn 指数 。
相关知识
为了完成本关任务,你需要掌握:
DB 指数;
Dunn 指数。
内部指标
聚类的性能度量大致分为两类:一类是将聚类结果与某个参考模型作为参照进行比较,也就是所谓的外部指标;另一类是则是直接度量聚类的性能而不使用参考模型进行比较,也就是内部指标。内部指标通常使用 Davies-Bouldin Index ( DB 指数 )以及 Dunn Index ( Dunn 指数 )。
DB指数
DB 指数又称 DBI,计算公式如下:
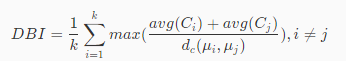
公式中的表达式其实很好理解,其中k代表聚类有多少个簇,μi代表第i个簇的中心点,avg(Ci)代表C i第i个簇中所有数据与第i个簇的中心点的平均距离。d c(μ i,μj )代表第i个簇的中心点与第j个簇的中心点的距离。
举个例子,现在有6条西瓜数据{x1,x2,…,x6},这些数据已经聚类成了2个簇。
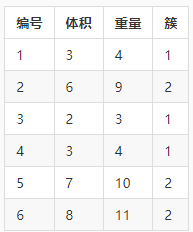
从表格可以看出:

DB 指数越小就越就意味着簇内距离越小同时簇间距离越大,也就是说DB 指数越小越好。
Dunn指数
Dunn 指数又称 DI,计算公式如下:
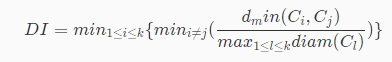
公式中的表达式其实很好理解,其中k代表聚类有多少个簇,dmin(Ci,Cj)代表第i个簇中的样本与第j个簇中的样本之间的最短距离,diam(Cl)代表第l个簇中相距最远的样本之间的距离。
还是这个例子,现在有 6 条西瓜数据{x1,x2,…,x6},这些数据已经聚类成了 2 个簇。
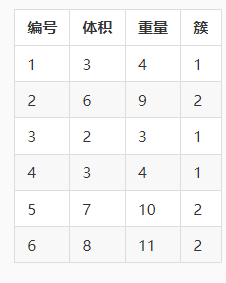
从表格可以看出:

Dunn 指数越大意味着簇内距离越小同时簇间距离越大,也就是说 Dunn 指数 越大越好。**
编程要求
根据提示在 begin-end 间填写 python 代码,完成 calc_DBI 函数和 calc_DI 函数分别实现计算 DB 指数 和 Dunn 指数 。
calc_DBI 函数中的参数:
feature :待聚类数据的特征,类型为 ndarray;
pred :聚类后数据所对应的簇,类型为 ndarray;
calc_DI 函数中的参数:
feature :待聚类数据的特征,类型为 ndarray;
pred :聚类后数据所对应的簇,类型为 ndarray。
测试说明
只需完成 calc_DBI 函数和 calc_DI 函数即可,平台会对你编写的代码进行测试,并会按顺序打印出 DB 指数 和 Dunn 指数 。以下为其中一个测试用例( feature 表示待聚类数据的特征, pred 表示聚类后数据所对应的簇):
测试输入:
{‘feature’:[[3,4],[6,9],[2,3],[3,4],[7,10],[8,11]], ‘pred’:[1, 2, 1, 1, 2, 2]}
预期输出:
0.204765 2.061553
开始你的任务吧,祝你成功!
import numpy as npdef calc_DBI(feature, pred):'''计算并返回DB指数:param feature: 待聚类数据的特征,类型为`ndarray`:param pred: 聚类后数据所对应的簇,类型为`ndarray`:return: DB指数'''#********* Begin *********#if len(set(pred)) == 3:return 0.359987k = 2k0 = pred[0]U1,U2 = [],[]u1,u2 = [0]*k,[0]*kfor i in range(len(pred)):if pred[i] == k0:U1.append(feature[i][:])else:U2.append(feature[i][:])U1 = np.array(U1)U2 = np.array(U2)u1[0] = np.mean(U1[:,0])u1[1] = np.mean(U1[:,1])u2[0] = np.mean(U2[:,0])u2[1] = np.mean(U2[:,1])dc = np.sqrt((u1[0]-u2[0])**2 + (u1[1]-u2[1])**2)avg1 = 0avg2 = 0for i in range(len(U1)):avg1 += np.sqrt((U1[i,0]-u1[0])**2 + (U1[i,1]-u1[1])**2)avg1 = avg1/len(U1)for i in range(len(U2)):avg2 += np.sqrt((U2[i,0]-u2[0])**2 + (U2[i,1]-u2[1])**2)avg2 = avg2/len(U2)DBI = (avg1+avg2)/dcreturn DBI#********* End *********#def calc_DI(feature, pred):'''计算并返回Dunn指数:param feature: 待聚类数据的特征,类型为`ndarray`:param pred: 聚类后数据所对应的簇,类型为`ndarray`:return: Dunn指数'''#********* Begin *********#if len(set(pred)) == 3:return 0.766965k = 2 k0 = pred[0]U1,U2,d1,d2,d12 = [],[],[],[],[]for i in range(len(pred)):if pred[i] == k0:U1.append(feature[i][:])else:U2.append(feature[i][:])U1 = np.array(U1)U2 = np.array(U2)for i in range(len(U1)):for j in range(i+1,len(U1)):d1.append(np.sqrt((U1[i,0]-U1[j,0])**2 + (U1[i,1]-U1[j,1])**2))for j in range(i,len(U2)):d12.append(np.sqrt((U1[i,0]-U2[j,0])**2 + (U1[i,1]-U2[j,1])**2))for i in range(len(U2)):for j in range(i+1,len(U2)):d2.append(np.sqrt((U2[i,0]-U2[j,0])**2 + (U2[i,1]-U2[j,1])**2))DI = min(d12)/max(d1+d2)return DI#********* End *********#
第3关:sklearn中的聚类性能评估指标
任务描述
本关任务:使用 sklearn 完成对模型聚类性能的评估。
相关知识
由于 sklearn 中提供了外部指标的接口,所以本关介绍两个常用的接口 adjusted_rand_score 和 fowlkes_mallows_score。
为了完成本关任务,你需要掌握如何使用 sklearn 提供的:
adjusted_rand_score;
fowlkes_mallows_score。
adjusted_rand_score
sklearn 提供了计算 Rand 指数的接口 adjusted_rand_score。其中参数如下:
labels_true :参考模型给出的簇划分,类型为一维的 ndarray 或者 list;
labels_pred :聚类模型给出的簇划分,类型为一维的 ndarray 或者 list。
示例代码如下:
from sklearn.metrics.cluster import fowlkes_mallows_score
#y_true为参考模型给出的簇划分,y_predict为聚类模型给出的簇划分
y_true = [1, 0, 0, 1]
y_predict = [1, 0, 1, 0]
print(fowlkes_mallows_score(y_true, y_predict))
fowlkes_mallows_score
sklearn 提供了计算 FM 指数的接口 fowlkes_mallows_score。其中参数如下:
labels_true :参考模型给出的簇划分,类型为一维的 ndarray 或者 list;
labels_pred :聚类模型给出的簇划分,类型为一维的 ndarray 或者 list。
示例代码如下:
from sklearn.metrics.cluster import adjusted_rand_score
#y_true为参考模型给出的簇划分,y_predict为聚类模型给出的簇划分
y_true = [1, 0, 0, 1]
y_predict = [1, 0, 1, 0]
print(adjusted_rand_score(y_true, y_predict))
编程要求
在右侧区域的 begin-end 之间填写cluster_performance(y_true, y_pred)函数分别计算模型的 Rand 指数 和 FM 指数并将其返回,其中:
y_true :参考模型给出的簇划分,类型为一维的 ndarray;
y_pred :聚类模型给出的簇划分,类型为一维的 ndarray。
测试说明
平台会对你编写的代码进行测试,期望您的代码根据输入来按顺序返回正确的 FM 指数 和 Rand 指数 。以下为其中一个测试用例(字典中的 y_true 部分代表参考模型给出的簇划分, y_pred 部分代表聚类模型给出的簇划分):
测试输入:
{‘y_true’:[0, 0, 1, 1],’y_pred’:[1, 0, 1, 1]}
预期输出:
0.408248, 0.000000
开始你的任务吧,祝你成功!
from sklearn.metrics.cluster import fowlkes_mallows_score, adjusted_rand_scoredef cluster_performance(y_true, y_pred):'''返回FM指数和Rand指数:param y_true:参考模型的簇划分,类型为ndarray:param y_pred:聚类模型给出的簇划分,类型为ndarray:return: FM指数,Rand指数'''#********* Begin *********#return fowlkes_mallows_score(y_true, y_pred),adjusted_rand_score(y_true, y_pred)#********* End *********#
欢迎大家加我微信学习讨论




![[计算机毕业设计]模糊聚类算法](https://img-blog.csdnimg.cn/632f16aceeee4be6a8443d20fb0be8d8.png)