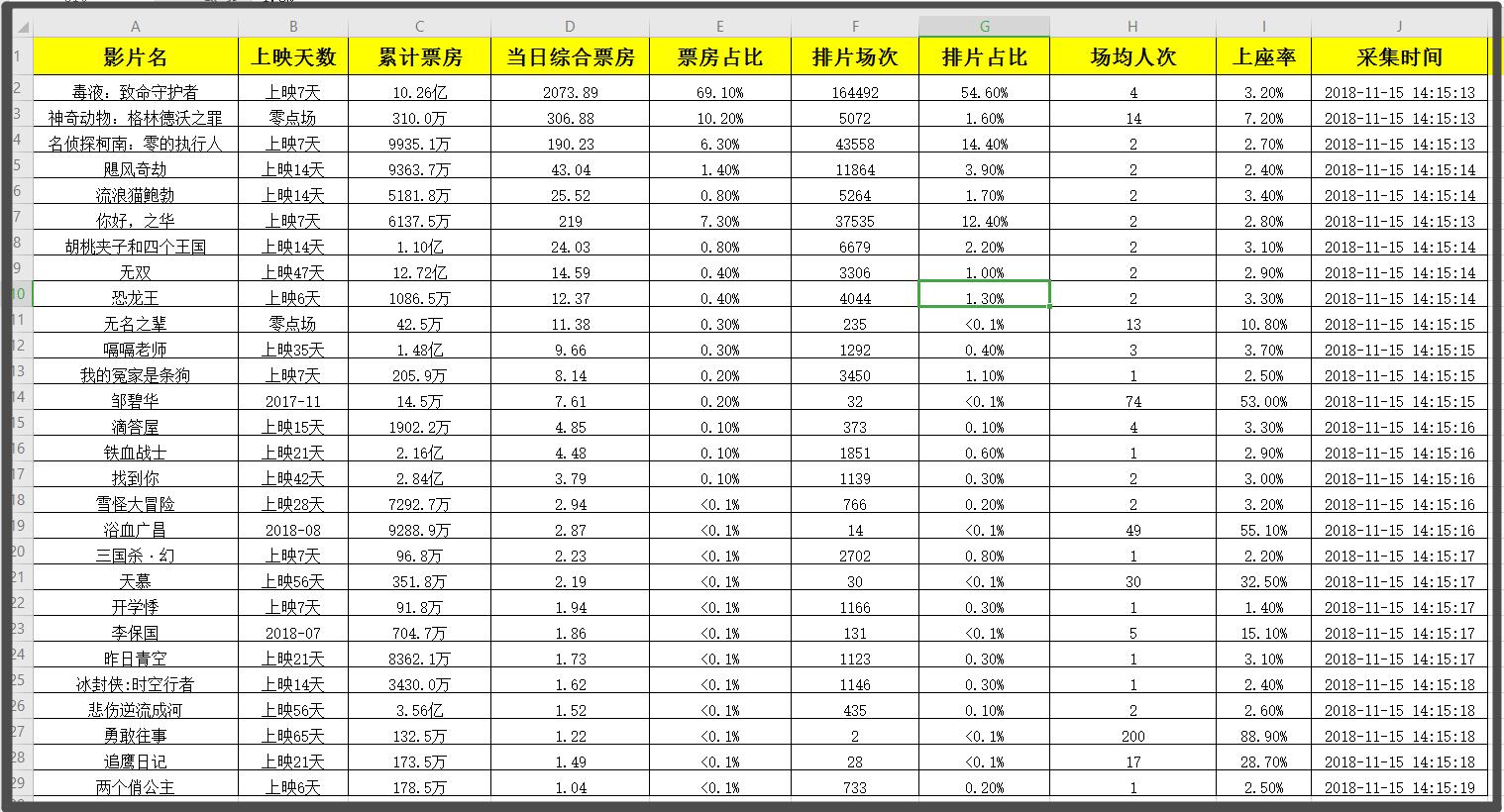
记得之前有写过如何用R做随机截距交叉滞后,有些粉丝完全是R小白,还是希望我用mplus做,今天就给大家写写如何用mplus做随机截距交叉滞后。
做之前我们需要知道一些Mplus的默认的设定:
- observed and latent exogenous variables are correlated, and
- residuals of observed and latent outcome variables (which do not predict anything) in a path model are correlated.
这些设定可以帮助我们更容易地设定结构方程模型,但是在做随机截距交叉滞后模型的时候我们需要变化一下,此时需要在语法中加上ANALYSIS: MODEL = NOCOV;
用mplus做随机截距交叉滞后需要规定4个部分:
- 因素间部分,就是随机截距,用BY来设置,写出RIx BY x1@1 x2@1 ...这样的形式,其中@1表示固定为1的意思,这个是做随机效应交叉滞后的默认操作
- 因素内部分的内在波动,也是用BY来设定,写出wx1 BY x1; wx2 BY x2; ....这样的形式,同时需要将误差方差固定为0
- 交叉滞后部分,写出wx2 ON wx1 wy1; wx3 ON wx2 wy2; ....这样的形式
- 内外共变部分,因素内写出wx1 WITH wy1; wx2 WITH wy2;....这样的形式;因素外写出RIx WITH RIy的形式。
所以一个基本的随机截距交叉滞后的代码就是如下:
MODEL: ! 随机截距RIx BY x1@1 x2@1 x3@1 x4@1 x5@1;RIy BY y1@1 y2@1 y3@1 y4@1 y5@1;! 因素内wx1 BY x1@1; wx2 BY x2@1;wx3 BY x3@1; wx4 BY x4@1; wx5 BY x5@1;wy1 BY y1@1; wy2 BY y2@1;wy3 BY y3@1; wy4 BY y4@1; wy5 BY y5@1;! 误差方差为0x1-y5@0;! 交叉滞后wx2 wy2 ON wx1 wy1;wx3 wy3 ON wx2 wy2;wx4 wy4 ON wx3 wy3;wx5 wy5 ON wx4 wy4;! 随机截距相关RIx WITH RIy;!组内相关wx1 WITH wy1;wx2 WITH wy2;wx3 WITH wy3; wx4 WITH wy4;wx5 WITH wy5; 加协变量
一般情况下我们在重复测量之前都会收集一般人口学特征等等协变量,在做分析的时候我们也会有控制协变量的需求,此处我们是有两个选择,一个是把协变量在显变量水平(左图),另外一个是将协变量控制在随机截距水平(右图):
控制在显变量水平的意思就是说我这些变量对模型的作用都是对每一波测量都有的,在协变量不变的情况下来从整体上拟合我们的模型,比如我现在有一个协变量Z我就可以写出代码如下:
MODEL: ! 随机截距RIx BY x1@1 x2@1 x3@1 x4@1 x5@1;RIy BY y1@1 y2@1 y3@1 y4@1 y5@1;RIx WITH RIy;wx1 BY x1@1; wx2 BY x2@1;wx3 BY x3@1; wx4 BY x4@1;wx5 BY x5@1;wy1 BY y1@1; wy2 BY y2@1;wy3 BY y3@1; wy4 BY y4@1;wy5 BY y5@1;x1-y5@0;! 协变量添加x1-x5 ON z1 (s1);y1-y5 ON z1 (s2);wx2 wy2 ON wx1 wy1;wx3 wy3 ON wx2 wy2;wx4 wy4 ON wx3 wy3;wx5 wy5 ON wx4 wy4;wx1 WITH wy1;wx2 WITH wy2;wx3 WITH wy3; wx4 WITH wy4; wx5 WITH wy5;控制在放在随机截距的意思就是说这个显变量是影响了个体差异进而影响整个模型,这个是在探究between-difference的影响的时候用的,此时我们的代码如下:
MODEL: RIx BY x1@1 x2@1 x3@1 x4@1 x5@1;RIy BY y1@1 y2@1 y3@1 y4@1 y5@1;RIx WITH RIy;wx1 BY x1@1; wx2 BY x2@1;wx3 BY x3@1; wx4 BY x4@1;wx5 BY x5@1;wy1 BY y1@1; wy2 BY y2@1;wy3 BY y3@1; wy4 BY y4@1;wy5 BY y5@1;x1-y5@0;! 协变量添加语法RIx RIy ON z1;wx2 wy2 ON wx1 wy1;wx3 wy3 ON wx2 wy2;wx4 wy4 ON wx3 wy3;wx5 wy5 ON wx4 wy4;wx1 WITH wy1;wx2 WITH wy2;wx3 WITH wy3; wx4 WITH wy4; wx5 WITH wy5;运行上面的代码我们的带协变量的随机截距交叉滞后就出来了,然后我们点击view diagram还可以看自动生成的路径图
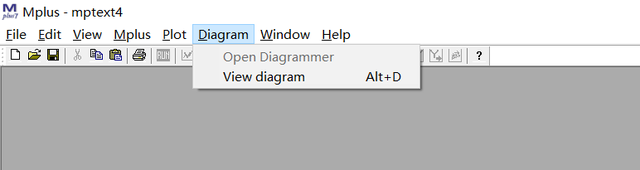
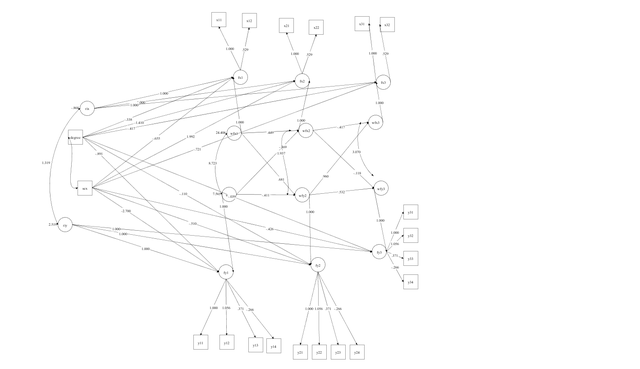
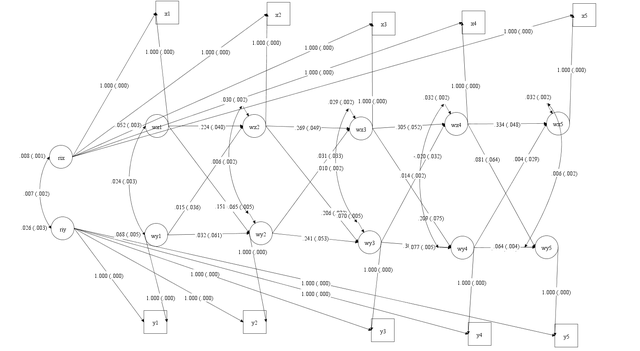
自己生成的就是乱糟糟一团,然后点击图中的各个节点都是可以调整的,下图是给一个同学做的多个显变量的随机截距交叉滞后模型,模型中控制了两个协变量sex和degree,然后下图就是mplus自动生成的模型图,调整调整还是能看的,这个模型是将协变量控制在显变量水平的:
多组比较建模
多组比较的意思就是看看路径系数或者载荷,在某个变量的组间是不是一样,内在原理是将模型分组拟合,然后比较固定两组路径相等的模型拟合优度和两组自由估计的优度之间的差异,如果路径相等的模型并没有显著差于自由估计的模型就可以认为组间无差异,常见的应用就是在量表的跨文化调试中,比如你想看看英文和中文的量表有没有差异,你就可以尝试进行多组比较建模:
Multigroup models test separate models in two or more discrete groups. Equality constraints across groups are used to conduct nested tests using likelihood ratio comparisons between a model with certain parameters constrained to be equal and a model with those same parameters freely estimated (allowed to differ) across the groups. For example, one can investigate whether means, predictive paths, or loadings differ across two nationalities.
做多组比较的时候,我们也需要修改一些mplus的默认设定,在默认设定中,显变量的截距在组间是等价的;潜变量的均值是自由估计的,我们在做多组比较模型的时候需要估计的参数其实变多了,所以我们需要将显变量的截距自由估计和将潜变量的均值固定从而释放更多的自由度。
如果我们要依照某个变量比如说group这个变量进行多组比较,我就可以在variable参数中加上grouping,写出代码如下,如果我们想直接比较某两个参数,我们可以用model test语法,然后结果中就会输出系数的组间检验,比如下面的代码就是在比较两组间随机截距的相关是不是一样:
VARIABLE: NAMES = x1-x5 y1-y5 GROUP;GROUPING = GROUP (1=G1 2=G2);MODEL: ! 随机截距部分RIx BY x1@1 x2@1 x3@1 x4@1 x5@1;RIy BY y1@1 y2@1 y3@1 y4@1 y5@1;! 测量误差wx1 BY x1@1; wx2 BY x2@1;wx3 BY x3@1; wx4 BY x4@1; wx5 BY x5@1;wy1 BY y1@1; wy2 BY y2@1;wy3 BY y3@1; wy4 BY y4@1; wy5 BY y5@1;x1-y5@0;! 交叉滞后系数wx2 wy2 ON wx1 wy1;wx3 wy3 ON wx2 wy2;wx4 wy4 ON wx3 wy3;wx5 wy5 ON wx4 wy4;! 随机截距共变RIx WITH RIy(a);! 同一波次的相关wx1 WITH wy1;wx2 WITH wy2;wx3 WITH wy3; wx4 WITH wy4;wx5 WITH wy5;MODEL G2: RIx WITH RIy(b);
model test:a = b;上面的代码的意思就是在运行上面的代码就可以出多组比较的结果了:
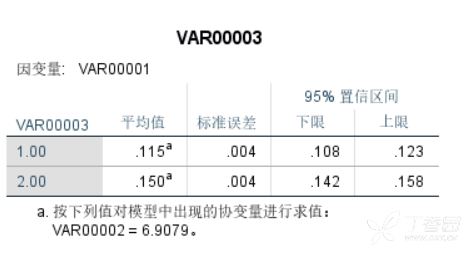
结果中会有系数比较的结果,说明两组间我们的系数(随机截距的相关)是有显著差异的:

以上就是今天给大家分享的在随机截距交叉滞后中控制协变量以及如何做组间系数比较,希望对大家有所启发。
上面的所有操作都是可以在R语言中进行的,不过有做这个模型需求的大多数同学还是用mplus多,所以出了一期mplus,希望可以帮助到大家。之后会给大家写R的操作。
小结
今天给大家写了随机截距交叉滞后的mplus做法,包括如何添加协变量,以及如何进行多组比较,希望对大家有启发,感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,另欢迎私信。