darts官方地址
- GitHub:https://github.com/unit8co/darts
- 文档:https://unit8co.github.io/darts/index.html
本笔记可作为以下内容的教程:
- 在多个时间序列上训练单个模型
- 使用预训练模型来获得训练期间看不到的任何时间序列的预测
- 训练和使用带协变量的模型
首先,一些必要的import:
import pandas as pd
import numpy as np
import torch
import matplotlib.pyplot as pltfrom darts import TimeSeries
from darts.utils.timeseries_generation import gaussian_timeseries, linear_timeseries, sine_timeseries
from darts.models import RNNModel, TCNModel, TransformerModel, NBEATSModel
from darts.metrics import mape, smape
from darts.dataprocessing.transformers import Scaler
from darts.utils.timeseries_generation import datetime_attribute_timeseries
from darts.datasets import AirPassengersDataset, MonthlyMilkDatasettorch.manual_seed(1); np.random.seed(1) # for reproducibility读取数据
让我们从两个时间序列开始——一个包含每月的航空乘客数量,另一个包含每月每头奶牛的产奶量。这些时间序列彼此之间没有太大关系,只是它们都有一个月频率,具有明显的年周期性和上升趋势,而且(完全巧合的是)它们包含一个可比数量级的值。
series_air = AirPassengersDataset().load()
series_milk = MonthlyMilkDataset().load()series_air.plot(label='Number of air passengers')
series_milk.plot(label='Pounds of milk produced per cow')
plt.legend();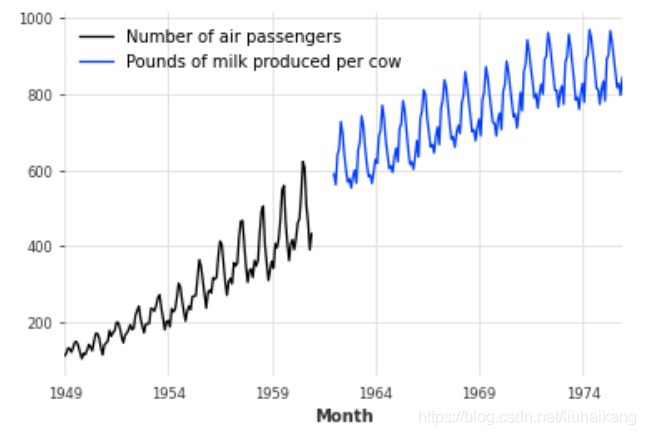
预处理
通常,神经网络对标准化数据的处理效果更好。在这里,我们将使用Scaler类对时间序列进行标准化至0和1之间:
scaler_air, scaler_milk = Scaler(), Scaler()
series_air_scaled = scaler_air.fit_transform(series_air)
series_milk_scaled = scaler_milk.fit_transform(series_milk)series_air_scaled.plot(label='air')
series_milk_scaled.plot(label='milk')
plt.legend();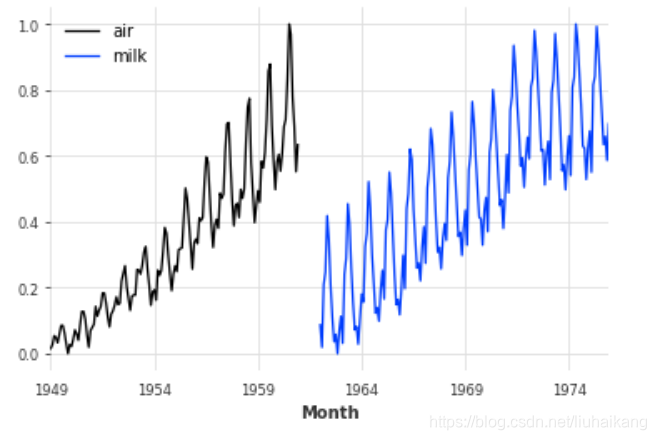
分割训练集/验证集
让我们将这两个序列的最后36个月作为验证集:
train_air, val_air = series_air_scaled[:-36], series_air_scaled[-36:]
train_milk, val_milk = series_milk_scaled[:-36], series_milk_scaled[-36:]全局预测模型
Darts包含了许多预测模型,但并不是所有的预测模型都可以在多个时间序列上进行训练。支持多序列训练的模型称为全局模型。在撰写本文时,共有4种全局模型:
- RNN
- Temporal Convolutional Networks(TCNs)
- N-Beats
- Transformer model
下面,我们将区分两种时间序列:
- 目标时间序列是我们感兴趣预测的时间序列(考虑其历史)
- 协变量时间序列是可能有助于预测目标序列的时间序列,但我们不感兴趣协变量时间序列的预测,协变量时间序列有时也称为外部数据。
上面列出的所有全局模型都支持多个序列的训练。此外,他们也都有多变量和协变量支持:
- 多元支持意味着它们可以无缝地用于多个维度的时间序列;目标序列可以包含一个维度(通常是这样)或多个维度。多维时间序列的每个时间戳的值都是向量而不是标量。
- 协变量支持意味着它们支持接收输入中的协变量序列(外部数据)。
在内部,这些模型包含一个神经网络,它在输入中获取大量时间序列,并输出大量(预测的)未来时间序列值。输入维数是目标序列的维数(分量)加上所有协变量的分量叠加在一起。输出维度只是目标系列的维度数:
好消息是,作为一个用户,我们不必担心不同的输入/输出维度;这些都是由模型根据训练数据自动推断出来的。注意,这意味着实际的内部神经网络模型只在训练时创建。
在构建模型时,我们仍需指定两个重要参数:
- input_chunk_length:这是模型的回望窗口的长度;因此,每个输出都将由模型通过读取先前的input_chunk_length个点来计算。
- output_chunk_length:这是内部模型生成的输出(预测)的长度。但是,当不使用协变量时,可以调用“外部”Darts模型的predict()方法(例如,RNNModel、TCNModel等中的方法)以获得更长的时间范围。在这些情况下,如果为比output_chunk_length更长的时间段调用predict(),则只需重复调用内部模型,以自动回归的方式输入其自身以前的输出。
单序列举例
让我们看第一个例子。我们将构建一个N-BEATS模型,它有一个24点的回望窗口(input_chunk_length=24),并预测接下来的12个点(output_chunk_length=12)。我们选择了这些值,这样我们的模型就可以一次连续预测一年,看看过去两年。
model_air = NBEATSModel(input_chunk_length=24, output_chunk_length=12, n_epochs=200)此模型可以像任何其他Darts预测模型一样使用,适用于单个时间序列:
model_air.fit(train_air, verbose=True)[2021-01-20 21:09:18,336] INFO | darts.models.torch_forecasting_model | Train dataset contains 73 samples.
[2021-01-20 21:09:18,336] INFO | darts.models.torch_forecasting_model | Train dataset contains 73 samples.HBox(children=(FloatProgress(value=0.0, max=200.0), HTML(value='')))
Training loss: 0.0002
和其他Darts预测模型一样,我们可以通过调用predict()获得预测。请注意,下面我们调用的predict()的范围是36,这比模型内部输出output_chunk_length的长度12要长。这在这里不是问题-如上所述,在这种情况下,内部模型只需根据自己的输出进行自回归调用。在这种情况下,它将被调用三次,这样三个12点的输出就构成了最终的36点预测——但所有这些都是在幕后隐形地完成的。
pred = model_air.predict(n=36)series_air_scaled.plot(label='actual')
pred.plot(label='forecast')
plt.legend();
print('MAPE = {:.2f}%'.format(mape(series_air_scaled, pred)))MAPE = 9.45%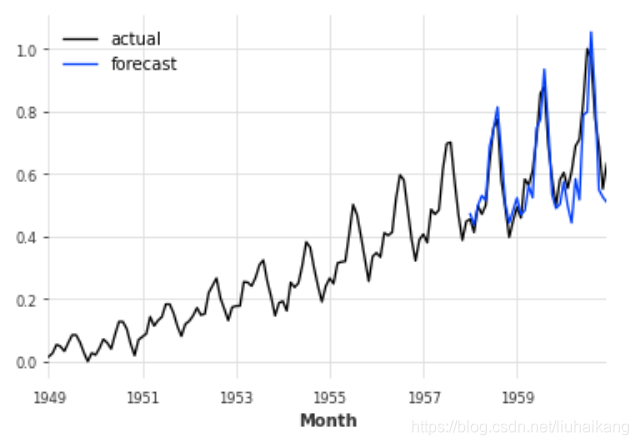
训练过程(幕后)
当我们在上面代码中调用model_air.fit()之后发生了什么呢?
为了训练内部神经网络,Darts首先从提供的时间序列(在本例中:series_air_scaled)中生成一个输入/输出示例数据集。有几种方法可以做到这一点,Darts在Darts.utils.data包中包含一些不同的数据集实现。
默认情况下,大多数模型都会实例化一个darts.utils.data.SequentialDataset,它只是构建序列中存在的所有连续的输入/输出子序列对(长度input\u chunk\u length和output\u chunk\u length)。
........(省略)
多时间序列模型的训练
所有这些机器都可以无缝地用于多个时间序列。
下面是一个input_chunk_length=4,output_chunk_length=2的连续数据集如何查找两个长度为N和M的序列:
注意以下几点:
- 不同的序列不需要具有相同的长度,甚至不需要共享相同的时间戳。
- 事实上,它们甚至不需要有相同的频率。
- 训练数据集中的样本总数将是每个序列中包含的所有训练样本的并集;所以一个训练纪元现在将覆盖所有系列的所有样本。
航空乘客和牛奶生产序列训练
让我们看另一个例子,我们在两个时间序列(航空乘客和牛奶生产)上拟合另一个模型实例。由于使用两个长度(大致)相同的序列(大致)使训练数据集的大小增加了一倍,因此我们将使用一半的epochs:
model_air_milk = NBEATSModel(input_chunk_length=24, output_chunk_length=12, n_epochs=100)然后,将模型拟合到两个(或多个)系列上,就像在fit()函数的参数中给出系列列表(而不是单个系列)一样简单:
model_air_milk.fit([train_air, train_milk], verbose=True)[2021-01-20 21:10:11,009] INFO | darts.models.torch_forecasting_model | Train dataset contains 194 samples.
[2021-01-20 21:10:11,009] INFO | darts.models.torch_forecasting_model | Train dataset contains 194 samples.HBox(children=(FloatProgress(value=0.0), HTML(value='')))
Training loss: 0.0002
在一个序列的结束后产生预测
现在,重要的是,在计算预测时,我们必须指定要预测未来的时间序列。
我们之前没有这个限制。当只在一个序列上拟合模型时,模型会在内部记住这个序列,如果调用predict()时不带series参数,则会返回(唯一)训练序列的预测。
当一个模型适合多个序列时,这种方法就不再有效了——在这种情况下,predict()的序列参数变成了必需的。
所以,假设我们想预测未来的空中交通。在本例中,我们将series=train_air 指定给predict()函数,以表示我们希望获得train_air的预测:
pred = model_air_milk.predict(n=36, series=train_air)series_air_scaled.plot(label='actual')
pred.plot(label='forecast')
plt.legend();
print('MAPE = {:.2f}%'.format(mape(series_air_scaled, pred)))
MAPE = 5.72%
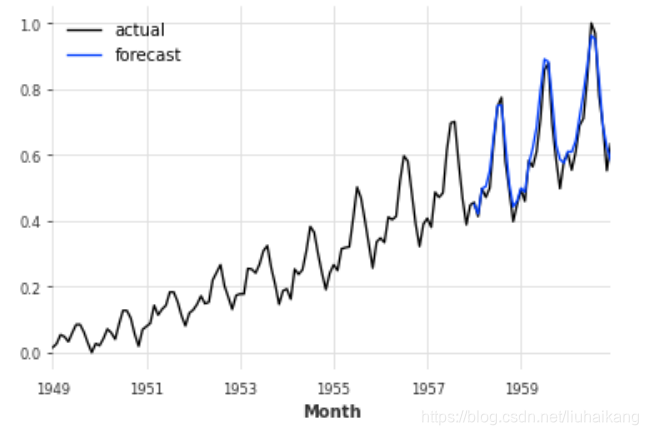
这是否意味着牛奶消费有助于预测空中交通??
好吧,在这个模型的特殊实例中,似乎是这样(至少在MAPE error
方面)。不过,仔细想想,这并不奇怪。空中交通具有明显的季节性和上升趋势。牛奶系列也展示了这两个特征,在这种情况下,它可能有助于模型捕捉它们。
注意,这一点指向了训练前预测模型的可能性;一次性训练模型,稍后使用它们来预测不在训练集中的序列。有了我们的玩具模型,我们真的可以预测任何其他系列的未来价值,即使是训练中从未见过的系列。举个例子,假设我们想预测一些任意正弦波序列的未来:
any_series = sine_timeseries(length=50, freq='M')
pred = model_air_milk.predict(n=36, series=any_series)any_series.plot(label='"any series, really"')
pred.plot(label='forecast')
plt.legend();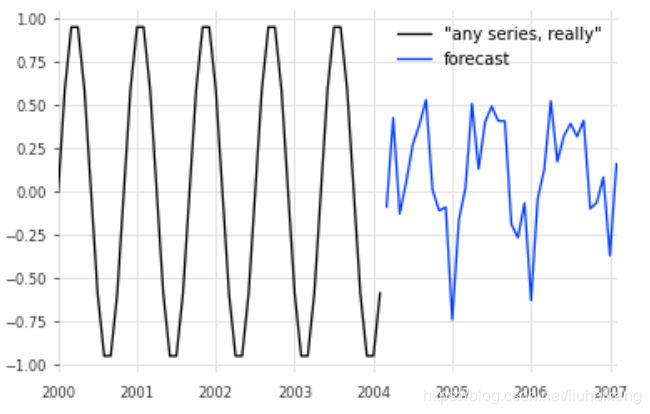
这个预测不是很好(正弦甚至没有一个年度的季节性),但你得到的想法。
与fit()函数所支持的类似,我们也可以在predict()函数的参数中给出一个序列列表,在这种情况下,它将返回一个forecast序列列表。例如,我们可以一次性得到空中交通量和牛奶系列的预测,如下所示:
pred_list = model_air_milk.predict(n=36, series=[train_air, train_milk])
for series, label in zip(pred_list, ['air passengers', 'milk production']):series.plot(label=f'forecast {label}')
plt.legend();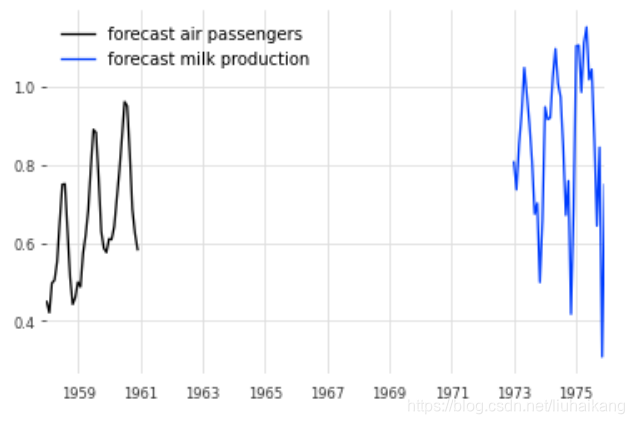
返回的两个序列分别对应于 train_air和train_milk结束后的预测。
协变量序列
到目前为止,我们一直在玩的模型,只使用历史的目标系列预测其未来。然而,如上所述,全局Darts模型也支持使用协变量时间序列。这些是“外部数据”的时间序列,我们不一定对预测感兴趣,但我们仍然希望将其作为模型的输入,因为它们可以包含有价值的信息。
构建协变量
让我们看一个简单的空气和牛奶系列的例子,我们将尝试使用一年中的年份和月份作为协变量:
# build year and month series:
air_year = datetime_attribute_timeseries(series_air_scaled, attribute='year')
air_month = datetime_attribute_timeseries(series_air_scaled, attribute='month')milk_year = datetime_attribute_timeseries(series_milk_scaled, attribute='year')
milk_month = datetime_attribute_timeseries(series_milk_scaled, attribute='month')# stack year and month to obtain series of 2 dimensions (year and month):
air_covariates = air_year.stack(air_month)
milk_covariates = milk_year.stack(milk_month)# scale them between 0 and 1:
scaler_dt_air = Scaler()
air_covariates = scaler_dt_air.fit_transform(air_covariates)scaler_dt_milk = Scaler()
milk_covariates = scaler_dt_milk.fit_transform(milk_covariates)# split in train/validation sets:
air_train_covariates, air_val_covariates = air_covariates[:-36], air_covariates[-36:]
milk_train_covariates, milk_val_covariates = milk_covariates[:-36], milk_covariates[-36:]# plot the covariates:
plt.figure();
air_covariates.plot();
plt.title('Air traffic covariates (year and month)');plt.figure();
milk_covariates.plot();
plt.title('Milk production covariates (year and month)');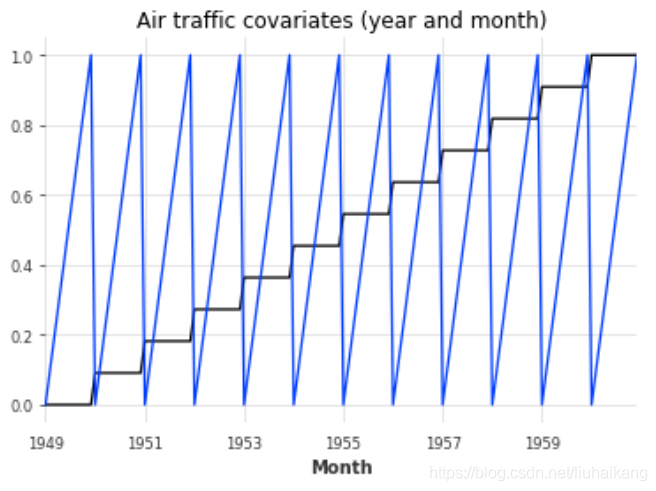
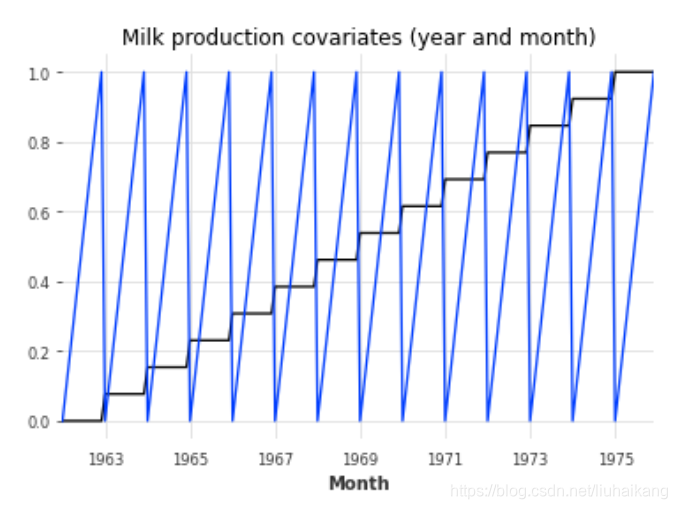
好的,所以对于每个目标系列(空气和牛奶),我们建立了一个具有相同时间轴的协变量系列,包含年份和月份。
注意,这里的协变量序列是多元时间序列:它们包含两个维度——一个维度是年份,一个是月。
协变量训练
让我们再次回顾我们的例子,这次是协变量。我们将构建一个RNNModel,因为在编写本文时,NBEATSModel还不支持协变量。
model_cov = RNNModel(input_chunk_length=24, output_chunk_length=12, n_epochs=300)现在,要使用协变量训练模型,只需将协变量(以与目标序列匹配的列表形式)作为协变量参数提供给fit()函数:
model_cov.fit(series=[train_air, train_milk], covariates=[air_train_covariates, milk_train_covariates], verbose=True)[2021-01-20 21:11:12,009] INFO | darts.models.torch_forecasting_model | Train dataset contains 194 samples.
[2021-01-20 21:11:12,009] INFO | darts.models.torch_forecasting_model | Train dataset contains 194 samples.HBox(children=(FloatProgress(value=0.0, max=300.0), HTML(value='')))
Training loss: 0.0019协变量预测
类似地,获得预测现在只需为predict()函数指定covariates参数。
pred_cov = model_cov.predict(n=12, series=train_air, covariates=air_train_covariates)series_air_scaled.plot(label='actual')
pred_cov.plot(label='forecast')
plt.legend();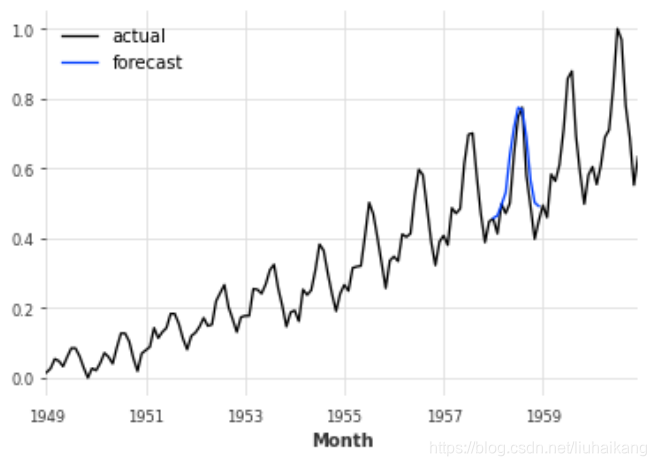
上面的主要问题是,我们不能直接调用predict(),因为horizon n大于我们训练模型时使用的输出块长度。这是因为当使用协变量时,我们不能使用自回归“技巧”,即我们对模型本身的输出进行迭代调用,因为在这种情况下,我们没有相应的协变量。
协变量回溯检验
我们仍然可以使用协变量对模型进行回溯测试。例如,我们有兴趣评估12个月的运行精度,从75%的空气系列开始:
backtest_cov = model_cov.historical_forecasts(series_air_scaled,covariates=air_covariates,start=0.6,forecast_horizon=12,stride=1,retrain=False,verbose=True)series_air_scaled.plot(label='actual')
backtest_cov.plot(label='forecast')
plt.legend();
print('MAPE (using covariates) = {:.2f}%'.format(mape(series_air_scaled, backtest_cov)))HBox(children=(FloatProgress(value=0.0, max=47.0), HTML(value='')))MAPE (using covariates) = 8.22%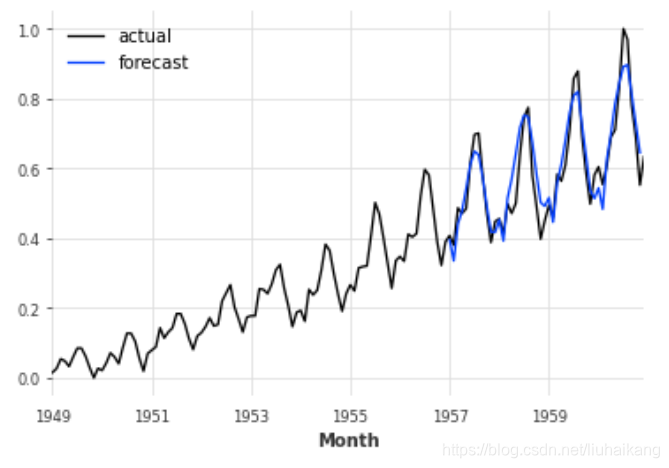
当前限制、未来协变量和其他条件
目前,Darts支持的协变量本身就是时间序列。此外,这些时间必须与目标序列共享相同的时间轴。唯一真正的区别是,这些协变量序列将只作为模型的输入,而不是作为输出。
然而,即使协变量和目标需要共享它们的时间轴,协变量仍然可以表示已知的未来值。例如,如果目标受到某些外部因素(例如,天气)的影响,并且提前7天知道天气,那么可以简单地构建协变量序列,使其在时间T的值表示T+7的“前一周”预测(这可以简单地通过移动原始序列来实现)。
在编写本文时,Darts不支持非时间序列的协变量,例如类标签信息或其他条件变量。解决这个问题的一个简单方法(尽管可能是次优的)是构建时间序列,该序列中填充了对类标签进行编码的常量值。支持更一般类型的条件反射是Darts开发路线图上的一个未来特性。