刚好最近在做一个关于中国电影市场的分析,所以这篇实例就诞生啦!!!
一、观察网页
我所爬取的网站是:中国票房——年度票房。
网址甩出来:http://www.cbooo.cn/year?year=2019
我们需要的数据是从2015年到2019年,每部电影的名称、详情页url、类型、总票房、国家及地区、上映日期
点进去的页面是介个样子滴~它总共有25条数据,就是2019年的TOP25!

左上角框出来的地方是可以选择年份的,我们可以通过它来观察不同年份间url的相似点。如下图:我们观察到他们的网址是有规律的,即:http://www.cbooo.cn/year?year= + 年份 这样我们就可以直接获取到所有的网址
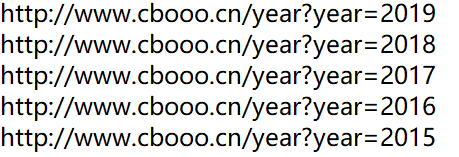
二、分步实现
1.导包
导入我们所需要的包
import os
import requests
from lxml import etree
import pandas as pd
2.定义获取数据的函数
因为每年都要请求一遍,所以为了方便,我们将它写成一个函数,直接调用,方便我们自己。
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
cookies = {'SUB':'_2A25wmfkgDeRhGeBI4lcU9irOzD2IHXVQZYdorDV6PUJbkdAKLUvAkW1NRkZNESdNnLdqXAeecDulr43bOma1k9ut'}
def get_data(url):r = requests.get(url, headers=headers, cookies=cookies, timeout=30)r.raise_for_status() #查看是否正常,正常返回200,否则返回404等r.encoding='utf-8'return r.text
此函数会返回url的网页源代码的内容,以url='http://www.cbooo.cn/year?year=2019’为例,下图为get_data后的结果,得到data后,我们就可以解析它,获取到我们想要的部分

3.提前创建csv表
local_data='D:/Learn'
local_main2=local_data+'/'+'movie.csv'#设置路径
if not os.path.exists(local_main2):data = pd.DataFrame(columns=['电影名称','电影详情页','电影类型','电影票房','国家及地区','上映时间'])data.to_csv(local_main2,index = None,encoding="utf_8_sig")
经过创建,在D盘下的learn文件夹下就会建好一个名为movie的csv空表。如下图:

4.获取近五年url
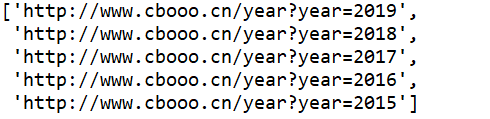
urls=[]
for year in range(5):urls.append('http://www.cbooo.cn/year?year={}'.format(2019-year))
结果如下:
5.获取我们需要的信息
这里我使用的是xpath,使用beautifulsoup也可以达到同样的效果
for url in urls:data = get_data(url)selector = etree.HTML(data)url = selector.xpath('//td[@class="one"]/a/@href') #详情页urlname = selector.xpath('//td[@class="one"]/a/@title') #电影名称movie_type = selector.xpath('//*[@id="tbContent"]//tr//td[2]/text()') #电影类型box_office = selector.xpath('//*[@id="tbContent"]//tr//td[3]/text()') #电影票房country = selector.xpath('//*[@id="tbContent"]//tr//td[6]/text()') #国家及地区time = selector.xpath('//*[@id="tbContent"]//tr//td[7]/text()') #上映时间
6.将获取的信息存入刚创建的csv
for i in range(len(url)):data = pd.DataFrame({'电影名称':name[i],'电影详情页':url[i],'电影类型':movie_type[i],'电影票房':box_office[i],'国家及地区':country[i],'上映时间':time[i]},columns=['电影名称','电影详情页','电影类型','电影票房','国家及地区','上映时间'],index=[0])data.to_csv(local_main2,index = None,mode = 'a' ,header= None,sep=',',encoding="utf_8_sig")
至此,我们的电影票房就获取完成啦!
三、汇总代码
完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 7 09:57:06 2019@author: chensiyi
"""import os
import requests
from lxml import etree
import pandas as pdheaders = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
cookies = {'SUB':'_2A25wmfkgDeRhGeBI4lcU9irOzD2IHXVQZYdorDV6PUJbkdAKLUvAkW1NRkZNESdNnLdqXAeecDulr43bOma1k9ut'}
def get_data(url):r = requests.get(url, headers=headers, cookies=cookies, timeout=30)r.raise_for_status() #查看是否正常,正常返回200,否则返回404等r.encoding='utf-8'return r.textlocal_data='D:/Learn'
local_main2=local_data+'/'+'movie.csv'#设置路径
if not os.path.exists(local_main2):data = pd.DataFrame(columns=['电影名称','电影详情页','电影类型','电影票房','国家及地区','上映时间'])data.to_csv(local_main2,index = None,encoding="utf_8_sig")urls=[]
for year in range(5):urls.append('http://www.cbooo.cn/year?year={}'.format(2019-year))for url in urls:data = get_data(url)selector = etree.HTML(data)url = selector.xpath('//td[@class="one"]/a/@href') #详情页urlname = selector.xpath('//td[@class="one"]/a/@title') #电影名称movie_type = selector.xpath('//*[@id="tbContent"]//tr//td[2]/text()') #电影类型box_office = selector.xpath('//*[@id="tbContent"]//tr//td[3]/text()') #电影票房country = selector.xpath('//*[@id="tbContent"]//tr//td[6]/text()') #国家及地区time = selector.xpath('//*[@id="tbContent"]//tr//td[7]/text()') #上映时间for i in range(len(url)):data = pd.DataFrame({'电影名称':name[i],'电影详情页':url[i],'电影类型':movie_type[i],'电影票房':box_office[i],'国家及地区':country[i],'上映时间':time[i]},columns=['电影名称','电影详情页','电影类型','电影票房','国家及地区','上映时间'],index=[0])data.to_csv(local_main2,index = None,mode = 'a' ,header= None,sep=',',encoding="utf_8_sig")
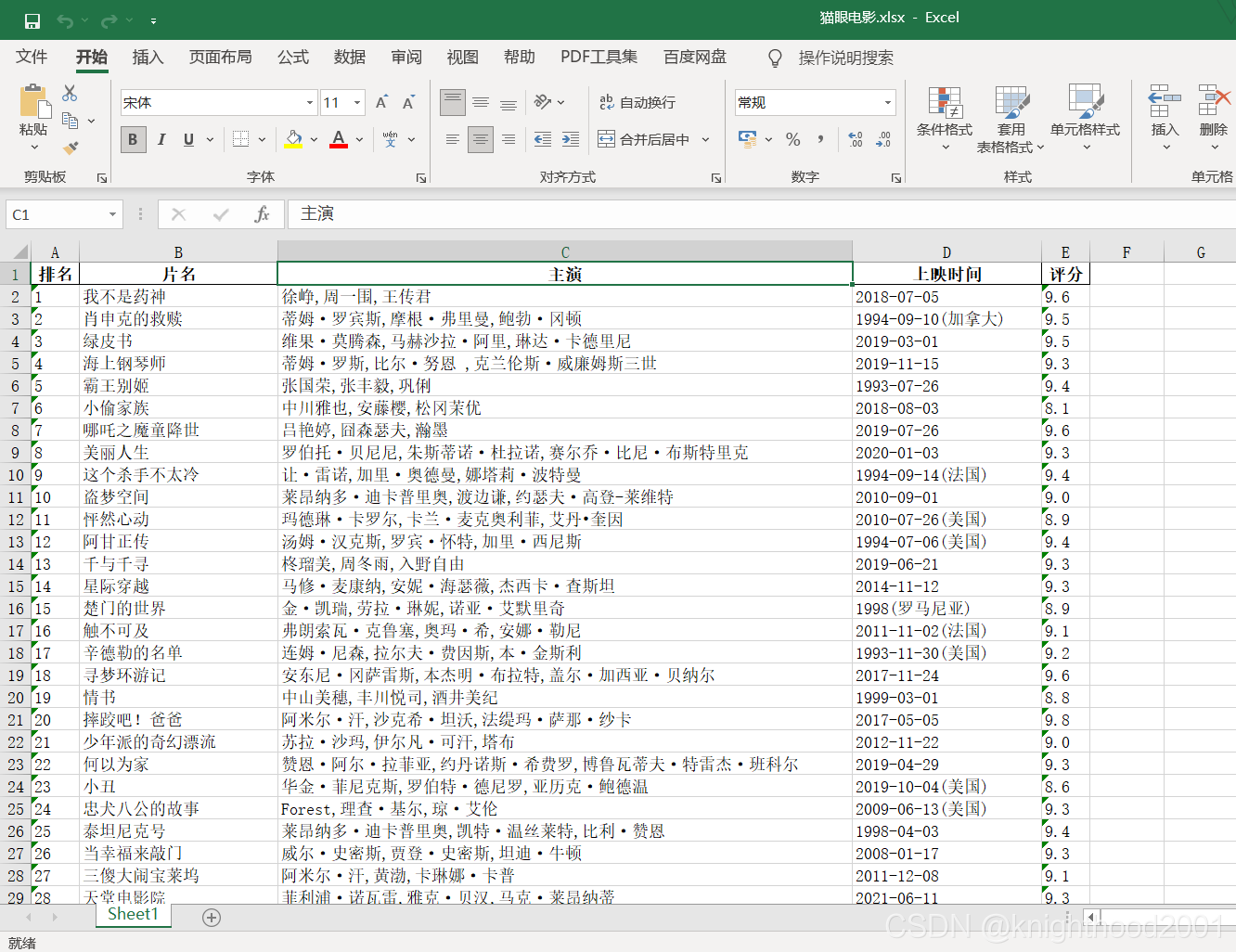
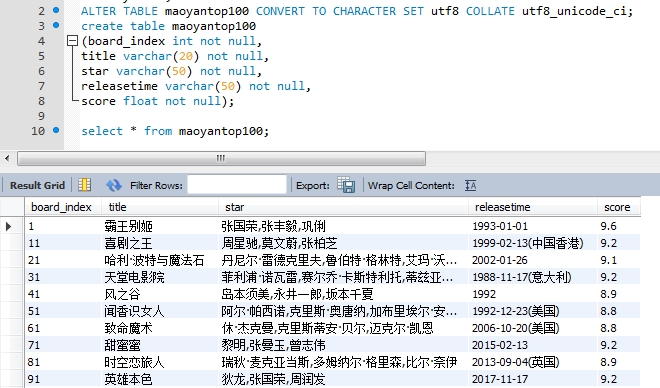
爬取的数据如下(部分):