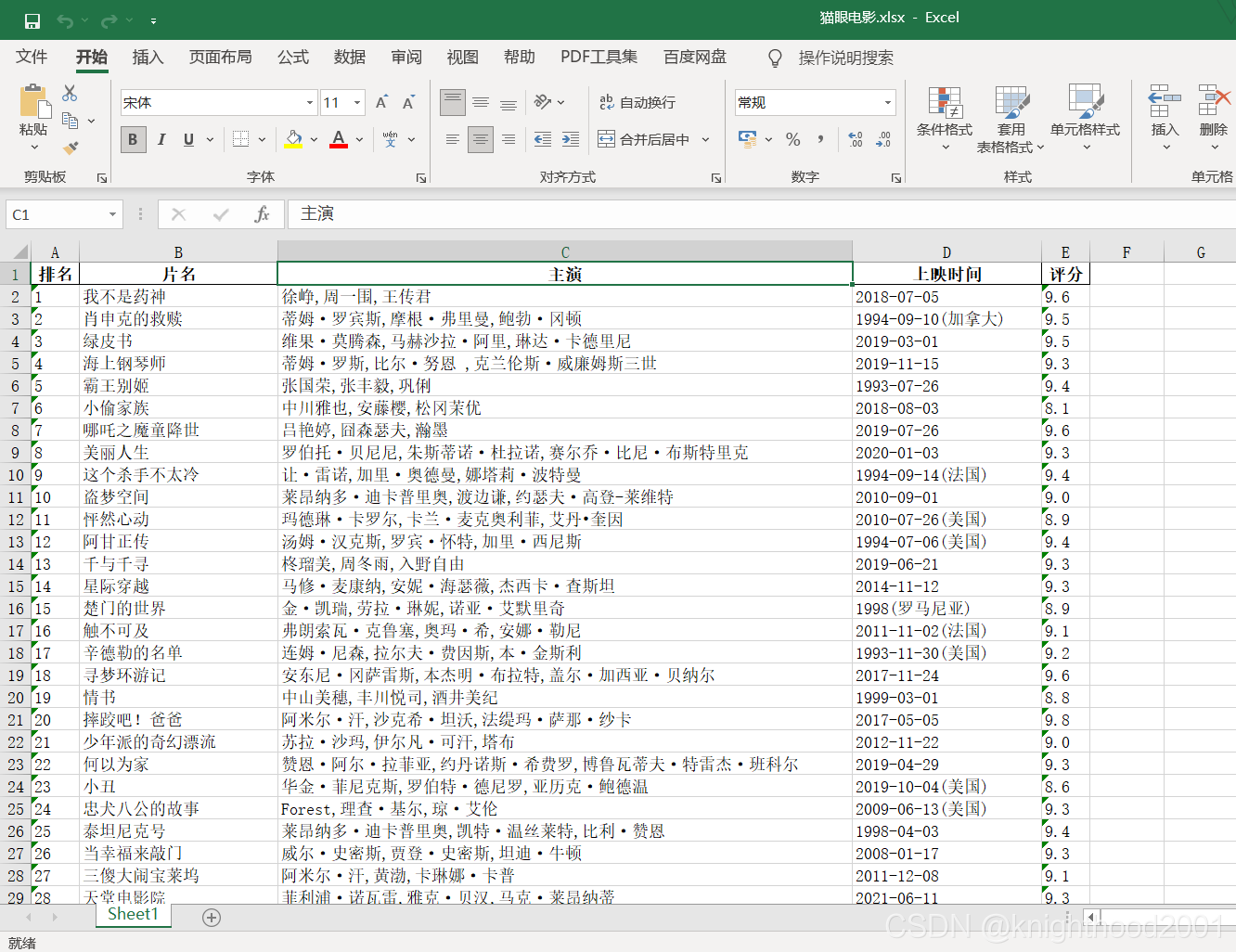
ROC曲线也叫受试者工作曲线,原来用在军事雷达中,后面广泛应用于医学统计中。ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线。
ROC曲线主要应用于二分类结局,比如是否死亡,疾病诊断,肿瘤复发等等,可以用于自变量为连续变量的截点判定。
目前有部分SCI文章中使用了校正协变量的ROC曲线,后台有粉丝问校正协变量的ROC曲线怎么做,今天我们来演示一下,使用的是一个肾移植的数据(公众号回复:肾移植数据,可以获得该数据),我们先导入数据和R包看一下看
library(RISCA)
dataDIVAT3<-read.csv("E:/r/test/shenyizhi.csv",sep=',',header=TRUE)
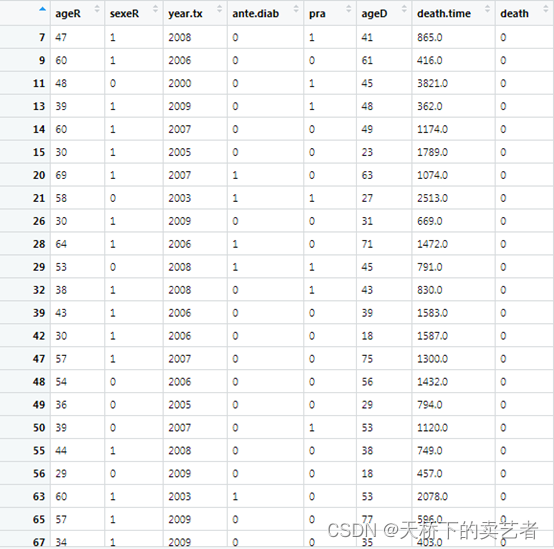
这是一个4267 名法国肾移植受者的数据,ageR:接受肾移植患者年龄,sexeR:患者性别,year.tx:肾移植的时间,ante.diab:是否有糖尿病,pra:患者移植前的免疫反应(1 = 可检测,0 = 不可检测),ageD:捐献肾脏的捐献者的年龄,death.time;生存时间,death:死亡,结局变量
我们取一部分数据来分析,这样数据没有这么大,好分析一点
dataDIVAT3 <- dataDIVAT3[1:400,]
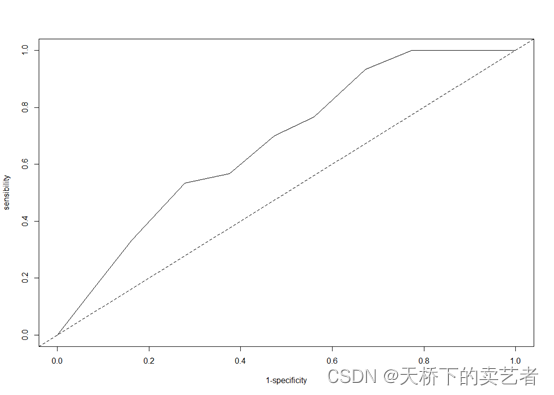
假设我们想知道患者年龄和死亡的ROC关系,我们先来个没有进行校正的ROC,confounders是混杂因素的意思,没有校正的时候这里填入1,precision是ROC曲线的步长,一般都是固定的
roc1 <- roc.binary(status="death", variable="ageR", confounders=~1,data=dataDIVAT3, precision=seq(0.1,0.9, by=0.1) )
绘图
plot(roc1, xlab="1-specificity", ylab="sensibility")
假设我们想对患者性别和捐献者年龄这两个指标进行校正,校正的思想主要是通过逆概率加权,生一个加权后的标准化年龄指标进行校准,先建立模型
lm1 <- lm(ageR ~ ageD + sexeR, data=dataDIVAT3[dataDIVAT3$death == 0,])
生成校正后的标准化年龄指标
dataDIVAT3$ageR_std <- (dataDIVAT3$ageR - (lm1$coef[1] + lm1$coef[2] *dataDIVAT3$ageD + lm1$coef[3] * dataDIVAT3$sexeR)) / sd(lm1$residuals)
生成ROC数据
roc2 <- roc.binary(status="death", variable="ageR_std",confounders=~bs(ageD, df=3) + sexeR, data=dataDIVAT3, precision=seq(0.1,0.9, by=0.1))
最后绘图
plot(roc2, col=2, pch=2, lty=2, type="b", xlab="1-specificity", ylab="sensibility")
lines(roc1, col=1, pch=1, type="b")
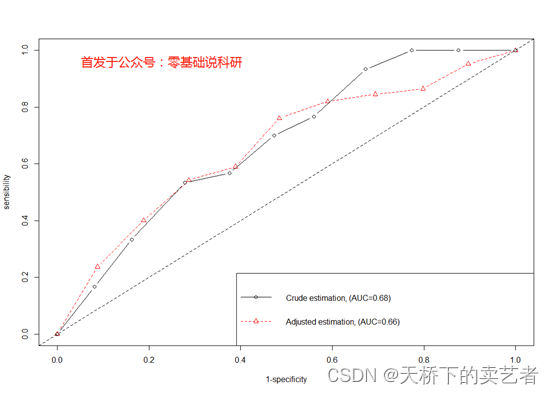
legend("bottomright", lty=1:2, lwd=1, pch=1:2, col=1:2,c(paste("Crude estimation, (AUC=", round(roc1$auc, 2), ")", sep=""),paste("Adjusted estimation, (AUC=", round(roc2$auc, 2), ")", sep="") ) )
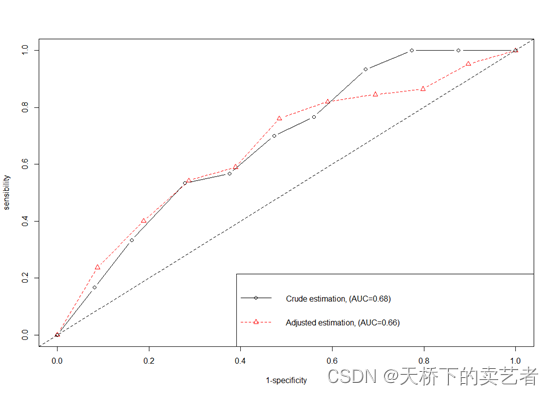
可以看出,经过校正后,AUC面积和曲线变化并不大,说明说明校准因素影响很小,支持了原结论。