转载于:https://blog.csdn.net/moyeshuier/article/details/103943355 这之前,我必须先讲一下cpu cache 内存三个组件在运行程序时候的关联,有了这个基础我后面才能讲锁。
那今天讲的是缓存一致性,首先要理解我说的缓存是什么意思,大家可以看下下面的图,这个很常见的图就是说现在我们买电脑的时候经常听说的参数cpu L1 L2 L3三级缓存,然后一般是CPU的每个核都有自己的L1级缓存,然后共享L2 L3缓存(当然也有的是只有L3是共享的),然后CPU和内存条的通信其实是经过bus总线来进行通信的。

这个和后面我们讲的锁会有什么关系呢,别急,关系真的非常大。
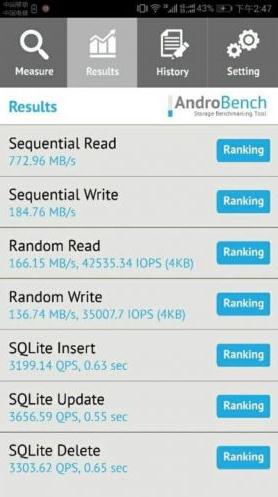
我们先探讨下为什么要出缓存这个东西,这个和组件发展的进度有关。其实直到现在,内存的速度发展依然很缓慢,2020年DDR4已经普及了,我看到的主流的内存频率也就3200MHZ,绝大部分都还只是2400MHZ,我手上的E3 1231V3的电脑用的是DDR3 1600,貌似提高了一倍,但是你要看下存取数据的速度和缓存比,依然不是一个档次,下面我们先看下我用AIDA软件测试的对比。

篇幅有限,本人不喜欢啰嗦,就比较L1和主存的速度吧,别的读者自己掂量下,我们运算的时候每个变量都是存在内存里的(一般书上是这么说的,为了不展开讲cpu缓存),那我们每执行一条语句的时候,都要拿很多次数据,那么如果从内存拿数据来同步执行,就是执行一个简单的语句也要60ns,而我直接从L1缓存拿数据的话,就是1ns,差距就有60倍。
以前100MHZ的cpu主频的时代,这个还是能接受的,后来CPU的频率太快了,快到主存跟不上,这样在处理器时钟周期内,CPU常常需要等待主存,这样就会浪费资源。所以cache的出现,是为了缓解CPU和内存之间速度的不匹配问题(结构:CPU -> cache -> memory)
下面我在goland上写个最简单的性能测试,看下ops结果,每次执行耗时只有不到1ns,这个就是cpu走的是缓存和乱序执行优化的结果。如果是走内存同步,这个性能差距根本不可接受。

那么,既然如此,我们全部用缓存不好吗,为什么还要内存?
回答其实很简单,cpu内部集成不了这么大的缓存,而且也买不起,平常的L1缓存 也就几十k而已,为了性能和价格的平衡,用了三级缓存来提高命中率。
既然有命中率一说,就必然存在的一个问题是,缓存不能包含CPU所需要的所有数据,那么缓存的存在真的有意义吗?
CPU cache是肯定有它存在的意义的,至于CPU cache有什么意义,那就要看一下它的局部性原理了:
1.时间局部性:如果某个数据被访问,那么在不久的将来它很可能再次被访问
2.空间局部性:如果某个数据被访问,那么与它相邻的数据很快也可能被访问
那么我们只要提高缓存命中率就能够在经济的条件下提升程序的性能。
我大概说下缓存间传递数据的流程:
当CPU内核读到内存加载指令时,它将地址传递给L1高速缓存。L1检查它是否包含相应的缓存行。如果不是则从下一个更深的缓存级,继续检查,如果还没;则从内存中引入整个缓存行(假设内存访问是本地化的)
因此,如果我们查看内存中的某个字节,我们可能很快就会访问其邻居。一旦高速缓存行出现在L1D中,装入指令就可以继续执行并执行其内存读取。
只要我们处理的是只读访问,它就非常简单,因为所有缓存级别都遵循的基本不变式
即任何时候,任何高速缓存级别中存在的所有高速缓存行的内容始终与相应地址的内存中的值相同。
- 1
所以读相对是比较好理解的。
一旦我们允许存储,即内存写入,事情就会变得更加复杂。这里有两种基本方法:直写和回写。直写是比较容易的一种:我们只是将存储传递到下一级缓存(或内存)。如果我们有相应的行被缓存,我们将更新副本(甚至可能只是丢弃它),仅此而已。这保留了与以前相同的不变性:如果高速缓存中存在高速缓存行,则其内容始终与内存匹配。
回写有点棘手。缓存不会立即传递写入。取而代之的是,将这种修改本地地应用于高速缓存的数据,并且将相应的高速缓存行标记为“脏”。肮脏的高速缓存行可能触发写回,这时它们的内容将写回到内存或下一个高速缓存级别。回写后,脏的缓存行再次“干净”。当脏的缓存行被驱逐时(通常为缓存中的其他内容腾出空间),它总是需要先执行回写操作。回写高速缓存的不变性略有不同。
回写不变量:写回所有脏缓存行之后,任何缓存级别中存在的所有缓存行的内容与内存中相应地址处的值相同。
- 1
- 缓存一致性协议
只要在系统中单独使用一个CPU内核,一切就可以正常工作。添加更多的内核,每个内核都有自己的缓存,我们就会遇到一个问题:如果其他某个内核修改了其中一个缓存中的数据,会发生什么呢?
好吧,答案很简单:什么也没发生。那样不好,因为当其他人修改我们拥有缓存副本的内存时,我们希望某些事情发生。一旦有了多个缓存,我们确实需要使它们保持同步,或者我们实际上没有一个“共享内存”系统,更像是“共享内存中的通用概念”系统。
请注意,问题实际上是我们有多个缓存,而不是我们有多个内核。我们可以通过在所有内核之间共享所有缓存来解决整个问题:只有一个L1 ,并且所有处理器都必须共享它。在每个周期中,L1 都会选择一个幸运的内核,该内核将在此周期中执行内存操作并运行它。
这样很好。唯一的问题是它的运行速度也很慢,因为内核现在大部分时间都花在等待L1 请求的下一个回合上(而处理器要处理很多,每条加载/存储指令至少要执行一个)。
我指出这一点是因为它表明问题实际上并不是多核问题,而是多缓存问题。我们知道一组缓存可以工作,但是当它太慢时,下一个最好的事情就是拥有多个缓存,然后让它们表现得好像只有一个缓存一样。这就是缓存一致性协议的用途:顾名思义,它们确保多个缓存的内容保持一致性。
是不是感觉和redis的缓存同步开始有点像了,计算机的很多云计算的组件其实都不是新发明,而是以前的技术上浮了而已,这就是为什么要学好计算机基础。
缓存一致性(MESI),MESI是一个协议,这协议用于保证多个CPU cache之间缓存共享数据的一致性。它定义了CacheLine的四种数据状态,而CPU对cache的四种操作可能会产生不一致的状态。因此缓存控制器监听到本地操作与远程操作的时候需要对地址一致的CacheLine状态做出一定的修改,从而保证数据在多个cache之间流转的一致性。
MESI协议是一种适当的状态机,它既可以响应来自本地核心的请求,也可以响应总线上的消息。我不会详细介绍完整状态图以及不同的过渡类型。如果您愿意的话,您可以在有关硬件体系结构的书中找到更深入的信息,但是就我们的目的而言,这太过分了。以我个人经验作为软件开发,您将仅了解两件事:
- 首先,在多核系统中,获得对高速缓存行的读取访问权涉及与其他核通信,并可能导致它们执行内存事务。
- 写入高速缓存行是一个多步骤的过程:在编写任何内容之前,您首先需要获得高速缓存行的排他所有权和其现有内容的副本(所谓的“读取所有权”请求)。
- 不同体系架构的内存模型
不同的体系结构提供不同的内存模型。至少在我撰写本文时,ARM和POWER体系结构机器具有相对“弱”的内存模型:CPU内核在重载和存储操作的重新排序方面有相当大的回旋余地,这些方式可能会改变多核上下文中程序的语义以及“内存”。程序可以使用的“ barrier”指令来指定约束条件:“请勿跨此行对内存操作重新排序”。相比之下,x86具有相当强大的内存模型。
在这里,我将不讨论内存模型的详细信息。我相信它很快就会真正具有技术性,超出了本文的范围。但是,我确实想谈一谈“它们是如何发生的” –即弱保证(与我们从MESI等获得的完全顺序一致性相比)的来源以及原因。和往常一样,所有这些都归结为性能。
因此,这就是问题所在:
如果C1高速缓存在接收到总线事件的那一刻立即对总线事件做出响应,并且C2内核按程序顺序将每个内存操作诚实地发送到高速缓存,然后等待,您的确将获得完全的顺序一致性。在发送下一个之前完成。当然,实际上,现代CPU通常不执行以下任何操作:
- 缓存不会立即响应总线事件。如果在高速缓存忙于执行其他操作(例如,将数据发送到内核)时触发总线高速缓存行无效的总线消息到达,则该循环可能不会得到处理。取而代之的是,它将进入一个所谓的“无效队列”,在那里等待一段时间,直到缓存有时间对其进行处理。
- 通常,内核不按照严格的程序顺序将内存操作发送到高速缓存。乱序执行的内核肯定是这种情况,但即使如此,顺序内核也可能对内存操作的排序保证较弱(例如,确保单个高速缓存未命中不会立即使整个内核停下来)
特别地,存储是特殊的,因为它们是一个两阶段的操作:在存储可以通过之前,我们首先需要获得缓存行的排他所有权。而且,如果我们还没有独占所有权,则需要与其他内核交谈,这需要一段时间。同样,在发生这种情况时让内核处于闲置状态,这并不是很好地利用执行资源。相反,发生的事情是开始获取独占所有权的过程,然后进入所谓的“缓冲区”队列(有些人将整个队列称为“缓冲区)。它们会在此队列中停留一会儿,直到缓存准备好实际执行存储操作为止,此时相应的存储缓冲区将被“清空”,并且可以回收以容纳新的暂挂存储。
所有这些事情的含义是,默认情况下,加载可以获取过时的数据(如果相应的失效请求位于失效队列中),存储实际完成的时间比它们在代码中所建议的位置晚,并且一切变得更加模糊当涉及到无序执行时。因此,回到内存模型,基本上有两个阵营:
具有弱内存模型的体系结构在内核中完成了最少的工作量,使软件开发人员可以编写正确的代码。正式允许指令重新排序和各个缓冲阶段;没有任何保证。如果需要保证,则需要插入适当的内存屏障,这将防止重新排序并在需要时避免挂起操作的队列。
具有更强内存模型的体系结构在内部进行了大量记账工作。例如,x86处理器在称为MOB(“内存排序缓冲区”)的芯片内部数据结构中跟踪所有尚未完全完成(“退回”)的未决内存操作。作为乱序基础架构的一部分,x86内核可以在出现问题(例如页面错误或分支预测错误)之类的问题时回退未退休的操作。在我之前的文章“ 推测性地讲 ”中,我介绍了一些细节以及与内存子系统的一些交互。”。要点是,x86处理器会主动注意外部事件(例如缓存失效),这些事件将追溯使已经执行但尚未淘汰的某些操作的结果无效。也就是说,x86处理器知道它们的内存模型是什么,并且当发生在该模型中不一致的事件时,机器状态会回滚到上一次仍与内存模型规则一致的状态。最终结果是x86处理器为所有内存操作提供了非常有力的保证–尽管不是很连续。
因此,较弱的内存模型会导致内核更简单(并且可能功耗更低)。强大的内存模型使内核(及其内存子系统)的设计更加复杂,但更易于编写代码。从理论上讲,较弱的模型允许更多的调度自由,并且可能更快。
实际上,至少在目前,x86在内存操作的性能上似乎表现良好。但是,到目前为止,我很难称得上是绝对的赢家。当然了,这是题外话,arm的低功耗的原因是多方面的,也不止这一个。
今天就先讲这么多,有点多,但是我已经尽量精简了表述,确实表达缓存一致性的进行过程比较难。但是我相信大家应该懂了为什么我讲锁之前为什么要讲缓存一致性,因为锁解决的就是写内存屏障的问题,同时原子锁的原理就是用的多级缓存和缓存同步来实现无锁锁。