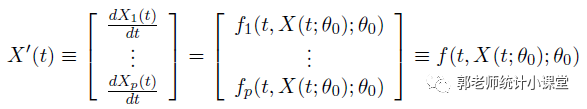文章目录
- 微分方程的符号解法
- 微分方程数值解法
- 一些常用的微分方程模型(学习中,持续更新)
- Logistics模型
- 传染病模型
本文介绍微分方程的求解,不介绍微分方程的建立方法
微分方程的符号解法
求解微分方程的符号解主要是依赖于Python的sympy包的函数,常用的函数如下:
Symbol:
语法: var = sym.Symbol('var_name')
描述: 定义符号变量,var_name为变量名,可以为任意字符串。Function:
语法: func = sym.Function('func_name')(var)
描述: 定义函数变量,func_name为函数名,var为自变量。Eq:
语法: eq = sym.Eq(lhs, rhs)
描述: 构建方程对象,lhs和rhs分别为方程左右两边的表达式。diff:
语法: sym.diff(f, x, n=1)
描述: 求导数,f为被求导函数,x为自变量,n为求导的阶数。integrate:
语法: sym.integrate(f, (x, a, b))
描述: 求不定积分或定积分,f为被积函数,x为积分变量,a和b分别为积分下限和积分上限。dsolve:
语法: sym.dsolve(equation, func)
描述: 求解微分方程的符号解,equation为微分方程对象,func为未知函数。symbols:
语法: x, y, z = sym.symbols('x y z')
描述: 一次性定义多个符号变量。lambdify:
语法: f = sym.lambdify(var, expr, 'numpy')
描述: 将符号表达式转换为可计算的数值函数,var为自变量,expr为符号表达式,'numpy'表示使用numpy库进行数值计算。simplify:
语法: sym.simplify(expr)
描述: 化简符号表达式,expr为待化简的符号表达式。expand:
语法: sym.expand(expr)
描述: 展开符号表达式,expr为待展开的符号表达式。factor:
语法: sym.factor(expr)
描述: 因式分解符号表达式,expr为待因式分解的符号表达式。solve:
语法: sym.solve(equations, vars)
描述: 求解方程的根,equations为方程组,vars为未知数。subs:
语法:Function.subs(var,value),将值带入符号函数
示例:单个微分方程的符号解

import sympy as sym
# 定义函数变量
y=sym.Function('y')(x)
# 定义单个符号变量
x=sym.Symbol('x')
# 定义微分方程
eq=sym.Eq(sym.diff(y,x,2)+2*sym.diff(y,x,1)+2*y,sym.sin(x))
# 使用一个字典定义初值条件
condition={y.subs(x,0):0,sym.diff(y,x,1).subs(x,0):1}
# 求解
sol=sym.dsolve(eq,ics=condition)
sol
示例:微分方程组的符号解

这里有必要先说下怎么一次性创建多个函数变量。在sympy中,可以使用symbols函数一次性创建多个符号变量:
import sympy as sym
# 一次性创建三个函数变量
f, g, h = sym.symbols('f g h', cls=sym.Function)
# 这里使用了symbols函数和Function函数的cls参数,cls参数指定变量的类型
还有必要说要下如何表示一个方程组。在sympy中,可以使用符号变量和函数变量来表示微分方程组。假设我们需要求解如下的二阶线性常微分方程组:
{ y 1 ′ ′ ( t ) + 2 y 1 ′ ( t ) + 3 y 1 ( t ) − 4 y 2 ( t ) = 0 y 2 ′ ′ ( t ) + 5 y 2 ( t ) − 6 y 1 ( t ) = 0 \begin{cases} y_1''(t) + 2y_1'(t) + 3y_1(t) - 4y_2(t) = 0 \\ y_2''(t) + 5y_2(t) - 6y_1(t) = 0 \end{cases} {y1′′(t)+2y1′(t)+3y1(t)−4y2(t)=0y2′′(t)+5y2(t)−6y1(t)=0
我们可以用sympy中的符号变量和函数变量来表示:
import sympy as sym
# 定义符号变量和函数变量
t = sym.Symbol('t')
y1, y2 = sym.symbols('y1 y2', cls=sym.Function)
# 定义微分方程组
eq1 = sym.diff(y1(t), t, 2) + 2*sym.diff(y1(t), t) + 3*y1(t) - 4*y2(t)
eq2 = sym.diff(y2(t), t, 2) + 5*y2(t) - 6*y1(t)
# 求解微分方程组
sol = sym.dsolve([eq1, eq2])
在这个例子中,我们用sym.Symbol(‘t’)定义了一个符号变量t,用sym.symbols(‘y1 y2’, cls=sym.Function)一次性定义了两个函数变量y1(t)和y2(t)。
然后,我们用sym.diff(y1(t), t, 2)表示了y1(t)的二阶导数,用sym.diff(y2(t), t)表示了y2(t)的一阶导数。最后,我们将这两个方程组成一个列表,传递给sym.dsolve函数求解微分方程组。
示例求解:
import sympy as sym
# 创建符号变量t
t= sym.Symbol('t')
# 创建函数变量
x1,x2,x3=sym.symbols('x1,x2,x3',cls=sym.Function)
# 表示微分方程组
eq=[sym.diff(x1(t),t,1)-2*x1(t)+3*x2(t)-3*x3(t),sym.diff(x2(t),t,1)-4*x1(t)+5*x2(t)-3*x3(t),sym.diff(x3(t),t,1)-4*x1(t)+4*x2(t)-2*x3(t)]
# 表示附加条件
con={x1(0):1,x2(0):2,x3(0):3}
# 求解
sol=sym.dsolve(eq,ics=con)
微分方程数值解法
部分特殊类型的微分方程具有符号解/解析解,而实际应用中可能遇到各种各样无法求解析解的微分方程,这时我们只能去求未知函数的数值解/近似解。
在python中我们主要是利用odeint(ordinary differential equation integrate)函数来求微分方程的数值解。下面介绍该函数:
scipy.integrate.odeint(func, y0, t, args=(), rtol=None, atol=None, mxstep=None, **kwargs)
- 干嘛的?什么原理:odeint函数的功能是求解常微分方程组的数值解(藐视不能求边界问题,智只可以求初值问题),即在给定时间点上计算ODE的数值解。具体来说,odeint函数使用数值算法来逼近ODE的解,将ODE转换为时间步长上的差分方程,并使用数值方法求解该方程。
- 详解核心参数:
- func:ODE的数学表达式,可以是一个函数或可调用对象。如果ODE是多元函数,需要将其转换为一元函数,例如使用向量表达式。函数的参数有两个:y表示ODE未知函数在t时刻的取值,t表示ODE的求解时间点。
- y0:ODE的初值条件,是一个一维数组,长度必须与ODE的方程数目相等。
- t:ODE的求解时间点,可以使用linspace或arange函数生成,也可以手动指定。
- 详解返回值:返回值是一个数组,数组的每一行表示对应时刻ODE的数值解。具体来说,如果ODE的方程数目为n,则返回值为一个二维数组,大小为(len(t), n),其中:len(t)表示求解时间点的数量,即返回数组的行数。n表示ODE的方程数目,即返回数组的列数。返回数组的第i行表示ODE在t[i]时刻的数值解,每一行由n个元素组成,分别对应ODE的各个未知函数在t[i]时刻的取值。
- 使用该函数的注意事项:输入的ODE必须是一个一阶方程组,但可以使用向量表达式将多个方程组合并为一个方程组。也就是说如果你的微分方程是一个高阶微分方程,那么你必须采用引入变量的方式(变量替换)为一阶微分方程组!
示例

通过引入变量的方法我们可以将这二阶常微分方程转换为一个一阶微分方程组:

使用odeint函数求解该微分方程组的数值解
from scipy.integrate import odeint
import numpy as np
import matplotlib.pyplot as plt
# 定义ODE的数学表达式
def func(y,t):# 未知函数有两个y1,y2=y# 按文档要求返回一个向量,这个向量的每一个元素表示的是微分方程中位置函数在t时刻的取值return np.array([y2,-2*y1-2*y2])
# 定义初值条件
y0=np.array([0,1])
# 定义求解时刻t,第一个时刻必须是初值对应的时刻
t=np.linspace(0,10,100)
# 求解
sol=odeint(func,y0,t)
# 返回值的第一列是y1在各时刻取值,第二列是y1导数即y2在个时刻取值,我们需要的是y在各个时刻的取值
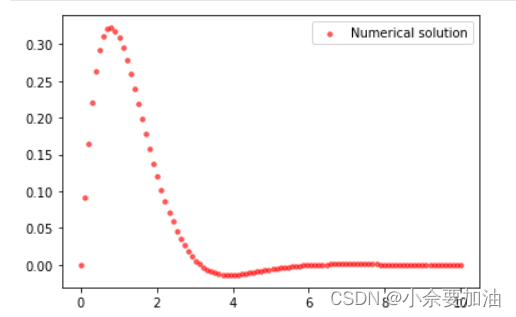
# 绘制一下该微分方程对应的函数在区间[0,10]的数值解
fig,ax=plt.subplots(1,1)
ax.scatter(t,sol[:,0],alpha=0.6,s=12,c='r',label='Numerical solution')
plt.legend(loc='best')
plt.show()
一些常用的微分方程模型(学习中,持续更新)
Logistics模型
- Logistics 模型是描述生物种群增长的一种模型,它是一种特殊的自治常微分方程模型。它是以比例增长模型为基础,考虑了种群增长的饱和性,因此比比例增长模型更为实际。
Logistics 模型的一般形式如下:
d N d t = r N ( 1 − N K ) \frac{dN}{dt} = rN\left(1-\frac{N}{K}\right) dtdN=rN(1−KN)
其中 N N N 表示种群数量, r r r 表示种群的增长率, K K K 表示种群的饱和容量。该模型的物理意义是,种群的增长率 d N d t \frac{dN}{dt} dtdN 与种群数量 N N N 成正比例,但同时又受到种群数量与饱和容量 K K K 的差异的限制。
该模型的解析解可以求得,具体为:
N ( t ) = K N 0 N 0 + ( K − N 0 ) e − r t N(t) = \frac{KN_0}{N_0+(K-N_0)e^{-rt}} N(t)=N0+(K−N0)e−rtKN0
其中 N 0 N_0 N0 表示种群数量的初始值, t t t 表示时间。这个解析解表明了种群的数量会随着时间的增加而增加,并趋向于饱和容量 K K K。
在实际应用中,Logistics 模型可以用来描述种群数量的增长或下降,例如,可以用该模型来预测某一种群在未来的数量变化趋势。 - 模型应用领域
- 生态学:Logistics 模型可以用来描述物种在一个特定环境下的生长规律,包括数量的增长和饱和。这个模型对于生态学研究和野生动物管理有很大的帮助。
- 经济学:Logistics 模型可以用来描述市场的增长和饱和。例如,可以用该模型来预测某种商品的市场需求和销售趋势。
- 流行病学:Logistics 模型可以用来描述疾病在人群中传播的方式。例如,可以用该模型来预测某种疾病的传播速度和范围,以便采取相应的措施来控制疫情。
- 人口统计学:Logistics 模型可以用来描述人口数量的增长和饱和。例如,可以用该模型来预测某个城市或国家的人口增长趋势,从而制定相应的发展政策。
- 生产管理:Logistics 模型可以用来描述生产过程中的物料储备和消耗过程。例如,可以用该模型来预测某种原料的消耗量和生产周期,从而制定相应的生产计划。
示例:根据往期美国人口数据预测美国到2025年的人口
数据给出:
years = np.array([1790,1800,1810,1820,1830,1840,1850,1860,1870,1880,1890,1900,1910,1920,1930,1940,1950,1960,1970,1980,1990,2000])
population = np.array([3929214,5308483,7239881,9638453,12866020,17069458,23191876,31443321,38558371,50155783,62979766,76212168,92228531,106021537,123202624,132164569,150697361,179323175,203302031,226545805,248709873,281421906])
这个模型的解析解已经给你了,所以实际上不必把他看做一个微分方程求解的问题,本质是一个参数估计的问题。在实际问题中我们对 N ( t ) = K N 0 N 0 + ( K − N 0 ) e − r t N(t) = \frac{KN_0}{N_0+(K-N_0)e^{-rt}} N(t)=N0+(K−N0)e−rtKN0的形式做了一些修改使用 N ( X ) = c 1 + e − b × ( X − a ) N(X)=\frac{c}{1+e^{-b\times{(X-a)}}} N(X)=1+e−b×(X−a)c的形式,做如下解释:
其中, c c c表示logistics函数的最大值,它是一个常数; b b b表示曲线的斜率,它是一个控制曲线陡峭程度的参数; a a a表示logistics函数的中心点,它是曲线的拐点。分母中的 ( 1 + exp ( − b ∗ ( X − a ) ) ) (1+\exp(-b*(X-a))) (1+exp(−b∗(X−a)))是logistics函数的形式,它的值域在(0,1)之间。分子前的系数为1,是因为我们需要将logistics函数的值放缩到和历史数据的数量级相同。如果分子前的系数不为1,就需要对历史数据进行放缩,这样会使得拟合参数更加复杂,也会影响拟合的精度。因此,我们通常将分子前的系数设置为1,这样可以更方便地拟合历史数据,也可以更准确地预测未来数据。其中, X X X表示年份, X − a X-a X−a的作用是将年份 X X X与中心点 a a a之间的差值作为logistics函数的自变量,从而控制logistics函数的形状和拟合历史数据的精度。当自变量为正时,logistics函数的值趋近于 c c c,而当自变量为负时,logistics函数的值趋近于0。在拐点 a a a处,自变量为0,logistics函数的值为 c / 2 c/2 c/2,这是预测曲线的最高点。因此, X − a X-a X−a的作用是将logistics函数的自变量平移,从而控制预测曲线的拐点位置。
好了回归整体,来求解示例,前面讲了这就是一个参数估计的问题,也就是拟合问题,我们使用curve_fit(执行非线性最小二乘法来估计)求得模型参数,然后拿这个模型应用即可:
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
years = np.array([1790,1800,1810,1820,1830,1840,1850,1860,1870,1880,1890,1900,1910,1920,1930,1940,1950,1960,1970,1980,1990,2000])
population = np.array([3929214,5308483,7239881,9638453,12866020,17069458,23191876,31443321,38558371,50155783,62979766,76212168,92228531,106021537,123202624,132164569,150697361,179323175,203302031,226545805,248709873,281421906])
# 定义logistics函数,注意必须把独立变量作为第一个参数,其他参数随后
def logistics(X,a,b,c):return c / (1 + np.exp(-b * (X - a)))
# 思考各个参数a,b,c的取值范围。
# a是模型的转折点,一定是在我们要预测的时间范围内的,取[1790,2050]就比较合适
# b是模型斜率,查阅资料,范围设置在[0,0.2]比较合理
# c是最大容量,设置一个足够大的数作为上界就好了.查阅资料知道美国2023年大约是3亿多人,不妨假设它的人口上限是4个亿
bounds=([1790,0,0],[2050,0.02,400000000])
# 拟合数据得到参数估计值
params,cov=curve_fit(logistics,years,population,bounds=bounds)
# 利用模型估计人口
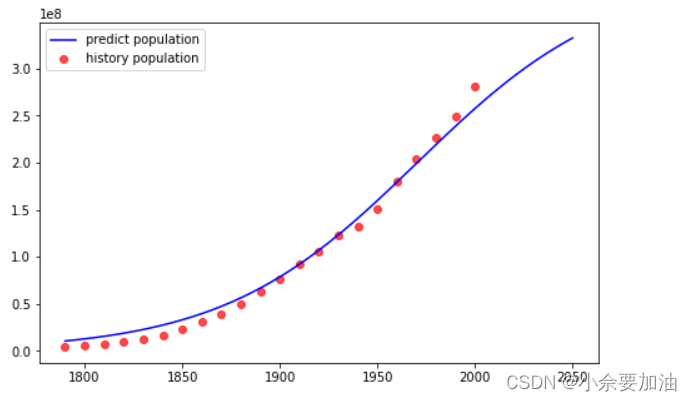
predict_population=logistics(np.arange(1790,2051,1),*params)
# 绘制图形查看预测效果和预测结果
fig,ax=plt.subplots(1,1,figsize=(8,5))
ax.plot(np.arange(1790,2051,1),predict_population,c='b',label='predict population')
ax.scatter(years,population,c='r',alpha=0.7,label='history population')
plt.legend(loc='best')
plt.show()