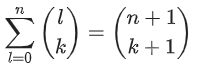前言
组合数计算
公式法
逐个相除法(错误)
逐个相除法修正版
素数幂乘法
基本公式法
平方差连乘法
组合恒等法
简单递归法
杨辉三角法
杨辉三角优化法
二进制法
组合数计算小结
获取数组的组合排列
二进制法
基本迭代法
从后向前迭代法(Matlab版本)
从后向前优化法
组合排列小结
后记
前言
最近学习了一下排列组合的相关知识,组合数的计算虽然比较简单,但是在实现它的过程中,我获得了很多新的理解。与此同时,网上关于计算组合数的博文比较多,却对数组的组合排列的描述较少。因此写这篇博文,一是记录下自己关于全组合的理解,二是实现一些数组的组合排列算法,我主要考虑全组合的算法实现,并不涉及溢出后的大数处理。
组合数计算
组合数的公式大家都可能比较熟悉,计算公式是,
。它还有两个性质,一个是互补性质,即
,一个是组合恒等性质,即
,具体细节可以参考高中数学书,或者百度百科了解下。因为组合数存在计算公式和性质,我们的算法也由此着手,主要分两个部分展开,一个是直接使用计算公式计算,二个是使用组合恒等性质进行操作。为了后续书写方便,将
记作 C(n, k),将
记作 A(n, k)。
因为这些方法必定会对参数n和k进行检验,为避免代码重复,我就将检验代码封装为一个检验方法,供后续使用,具体如下:
public static void checknk(int n, int k){if(k < 0 || k > n){ // N must be a positive integer.throw new IllegalArgumentException("K must be an integer between 0 and N.");}
}公式法
这一部分主要通过这个公式来实现,并对乘法和除法操作进行优化。
逐个相除法(错误)
因为C(n, k) = A(n, k) / A(k, k),其中A(n, k)和A(k,k)的乘数数量一样,因此我就想着直接一个一个相除后再相乘,虽然考虑可能会有精度损失,但还是抱着侥幸心理,最终就写出了如下代码:
public static int nchoosek(int n, int k){checknk(n, k);k = (k > (n - k)) ? n - k : k; // C(n, k) = C(n, n - k)if(k <= 1){ // C(n, 0) = 1, C(n, 1) = nreturn 1;}int divisor = n - k + 1;int dividend = 1;double cnk = 1.0;for(int i = 0; i < k; i++){cnk *= (double) (divisor + i) / (dividend + i);}return (int) cnk;
}因为double转换为int时,存在精度问题,所以上面的算法在计算C(13, 6)时就开始出现错误,如果将double改为float,将会在计算C(25, 9)时出现错误。我写这个方法的原因,是希望自己注意精度问题,不能对其存在侥幸心理,以为double精度较高就没事了。
逐个相除法修正版
前面那个算法,因浮点型转换为整型造成了精度问题,被我认定为错误的算法,但是如果我非要用除法来实现呢,可不可以呢?我们知道C(n, k)一定是整数,所以 A(n, k) 一定能整除 A(k, k),这给了我信心。A(n, k)等于n - k + 1 :k的数据累积,把这些数据存于数组a中,而A(k, k)等于1:k的数据累积,把这些数据存于数组b中。所以我就把数组b的数据逐个取出来,在数组a中找到能整除它的数,再进行除法操作,如果因为进行了除法操作,使得a中没有任何数能整除b中的某个数值,那么我们就将该数值分解为质因数,再用a对它的每个质因数分别进行除法操作。最终的结果就是数组a全部是大于等于1的整数,再对a中数据进行累积,就是最终结果C(n, k),这样也避免了精度转换造成的问题。具体代码如下:
public static long nchoosek(int n, int k){if(n > 70 || (n == 70 && k > 25 && k < 45)){throw new IllegalArgumentException("N(" + n + ") and k(" + k + ") don't meet the requirements.");}checknk(n, k);k = k > (n - k) ? n - k : k;if(k <= 1){ // C(n, 0) = 1, C(n, 1) = nreturn k == 0 ? 1 : n;}int[] divisors = new int[k]; // n - k + 1 : nint firstDivisor = n - k + 1;for(int i = 0; i < k; i++){divisors[i] = firstDivisor + i;}outer:for(int dividend = 2; dividend <= k; dividend++){for(int i = k - 1; i >= 0; i--){int divisor = divisors[i];if(divisor % dividend == 0){divisors[i] = divisor / dividend;continue outer;}}int[] perms = factor(dividend);for(int perm : perms){for(int j = 0; j < k; j++){int divisor = divisors[j];if(divisor % perm == 0){divisors[j] = divisor / perm;break;}}}}long cnk = 1L;for(int i = 0; i < k; i++){cnk *= divisors[i];}return cnk;
}C(70, 26)的结果超出了long范围,限定范围即可保证正确。其中的分解质因数函数factor,请参考分解质因数。
素数幂乘法
我们知道A(n, k)等于n + 1 - k :n的数值累积,A(k, k)等于1 : k的数值累加,因为所有整数不是素数就是合数,而合数是由素数乘积组成,因此这两个的排列结果都可以转换为素数幂的乘积。因此我们只需将n + 1 - k :n转换为素数的值以及其对应的幂数量即可,然后减去1 : k所对应的素数及其幂数量,最终计算剩余素数幂之积即可。我才用HashMap来映射素数和素数的幂。具体代码如下:
public static long nchoosek(int n, int k){if(n > 70 || (n == 70 && k > 25 && k < 45)){throw new IllegalArgumentException("N(" + n + ") and k(" + k + ") don't meet the requirements.");}checknk(n, k);k = k > (n - k) ? n - k : k;if(k <= 1){ // C(n, 0) = 1, C(n, 1) = nreturn k == 0 ? 1 : n;}HashMap<Integer, Integer> primeMap = new HashMap<>();for(int i = n - k + 1; i <= n; i++){for(int prime : factor(i)){Integer primeCount = primeMap.get(prime);primeMap.put(prime, primeCount == null ? 1 : primeCount + 1);}}for(int i = 2; i <= k; i++){for(int prime : factor(i)){primeMap.put(prime, primeMap.get(prime) - 1);}}long cnk = 1L;for(Map.Entry<Integer, Integer> entry : primeMap.entrySet()){int coef = entry.getKey();int exp = entry.getValue();if(exp > 0){cnk *= (long) Math.pow(coef, exp);}}return cnk;
}将累积除法转换为素数的加减法,效率得到了极大提升,求幂操作直接调用Math.pow即可,无需自己写个快速求幂算法。其中的分解质因数函数factor,请参考分解质因数。
基本公式法
根据公式,先计算A(n, k),再计算A(k, k),最后两者相除即可。具体代码如下:
public static int nchoosek(int n, int k){if(n > 16 || (n == 16 && k == 8)){throw new IllegalArgumentException("N(" + n + ") and k(" + k + ") don't meet the requirements.");}checknk(n, k);k = (k > (n - k)) ? n - k : k; // C(n, k) = C(n, n - k)if(k <= 1){ // C(n, 0) = 1, C(n, 1) = nreturn k == 0 ? 1 : n;}int divisor = 1;for(int i = n - k + 1; i <= n; i++){divisor *= i;}int dividend = 1;for(int i = 2; i <= k; i++){dividend *= i;}return (int) ((double) divisor / dividend);
} A(16, 8) = 4151347200 > 2147483647,会发生溢出情况,造成结果错误。虽然可以利用Long来提升它的适用范围,但是该方法效率过低,此举意义不大。
平方差连乘法
乘法相比于加减法,效率比较低,因此我们可以减少A(n, k)中乘法次数,来达到优化目的,其实质也就是阶乘的优化。关于阶乘算法的优化有很多,一部分是递归优化,一部分是阶乘结果大数的优化,这里我们并不涉及这两点,只是单纯就数学层面来优化乘法数量,这部分主要参考这篇博文:计算阶乘的另一些有趣的算法。
1 × 2 × 3 × 4 × 5 × 6 × 7 = (4 - 3) × (4 - 2) × (4 - 1) × 4 × (4 + 1) × (4 + 2) × (4 + 3)
=
1 × 2 × 3 × 4 × 5 × 6 =
因此对于偶数长度的n阶乘的结果为:, 其中m = n / 2。
对于奇数长度的n阶乘的结果为:, 其中m = n / 2。
与此同时,我们高中学过,奇数的前n项和为,所以上面连乘式子中的
就可以优化成对奇数的减法。因此我们就可以使阶乘中乘法的操作数量下降一倍。先简要写一个factorial函数练练手,代码如下:
public static long factorial(int n){if(n < 0 || n > 20){throw new IllegalArgumentException("N must be an integer between 0 and 20.");}if(n <= 1){return 1L;}int mid = (n & 1) == 1 ? (n >> 1) + 1 : (n >> 1);int midSquare = mid * mid;long fac = (n & 1) == 1 ? mid : midSquare << 1;for(int i = 1, limit = 2 * mid - 1; midSquare > limit; i += 2){fac *= midSquare -= i;}return fac;
}因此我们可以用它来优化我们的A(n, k),具体代码如下所示:
public static long nchoosek(int n, int k){if(n > 30 || (n == 30 && k > 13 && k < 17)){throw new IllegalArgumentException("N(" + n + ") and k(" + k + ") don't meet the requirements.");}checknk(n, k);k = (k > (n - k)) ? n - k : k; // C(n, k) = C(n, n - k)if(k <= 1){ // C(n, 0) = 1, C(n, 1) = nreturn k == 0 ? 1 : n;}return prod(n - k + 1, n) / prod(2, k);
}private static long prod(int begin, int end){int len = end - begin + 1;int mid = 0;long prodVal = 1L;int accumNum = 0;if((len & 1) == 1){mid = (len >> 1) + begin;prodVal = mid;accumNum = end - mid;}else{mid = (len >> 1) + begin - 1;prodVal = mid * end;accumNum = end - mid - 1;}long midSquare = (long) mid * mid;for(int i = 1; --accumNum >= 0; i += 2){prodVal *= midSquare -= i;}return prodVal;
}因为A(30, 14)的值超出了long范围,发生了溢出情况,造成结果错误,需要规避操作。
组合恒等法
这一部分主要通过这个递推公式来实现,并对该递推公式进行优化。
简单递归法
直接按照递推公式来实现算法,具体操作如下:
public static int nchoosek(int n, int k){if(n > 34 || (n == 34 && k >= 16 && k <= 18)){throw new IllegalArgumentException("N(" + n + ") and k(" + k + ") don't meet the requirements.");}checknk(n, k);if(k <= 1){ // C(n, 0) = 1, C(n, 1) = nreturn k == 0 ? 1 : n;}if(k > (n >>> 1)){return nchoosek(n, n - k);}return nchoosek(n - 1, k - 1) + nchoosek(n - 1, k);
}该方法是最容易实现的,效率也是差强人意。
杨辉三角法
我们仔细观察这个递推公式,发现它和杨辉三角的递推公式一样,其实以前高中学习排列组合老师就讲到过这玩意。因此我们也可以使用杨辉三角来实现它。具体代码如下:
public static int nchoosek(int n, int k){if(n > 34 || (n == 34 && k >= 16 && k <= 18)){throw new IllegalArgumentException("N(" + n + ") and k(" + k + ") don't meet the requirements.");}checknk(n, k);k = (k > (n - k)) ? n - k : k;if(k <= 1){ // C(n, 0) = 1, C(n, 1) = nreturn k == 0 ? 1 : n;}int[][] yhTriangle = new int[n + 1][n + 1];for(int i = 0; i <= n; i++){yhTriangle[i][0] = 1;yhTriangle[i][i] = 1;}for(int i = 1; i <= n; i++){for(int j = 1; j <= i; j++){yhTriangle[i][j] = yhTriangle[i - 1][j - 1] + yhTriangle[i - 1][j];}}return yhTriangle[n][k];
}其实可以将二维数组转换为一维数组进行操作,效率会高点,并且和上面的代码几乎一样,实现起来也比较简单。这里本来可以用long数组来追求更大的适用范围,不过这样也比较耗内存。因此就放弃了此想法。
杨辉三角优化法
上面操作中,开辟的杨辉三角二维数组利用率很低,并且我们处理的数据都是在两行数组中进行操作,与此同时,C(n, k)值的计算并不需要大于K部分的数值,因此我们可以选用两个K + 1长度的缓存数组来实现杨辉三角的操作。具体如下:
public static int nchoosek(int n, int k){if(n > 70 || (n == 70 && k > 25 && k < 45)){throw new IllegalArgumentException("N(" + n + ") and k(" + k + ") don't meet the requirements.");}checknk(n, k);k = (k > (n - k)) ? n - k : k;if(k <= 1){ // C(n, 0) = 1, C(n, 1) = nreturn k == 0 ? 1 : n;}int cacheLen = k + 1;long[] befores = new long[cacheLen];befores[0] = 1;long[] afters = new long[cacheLen];afters[0] = 1;for(int i = 1; i <= n; i++){for(int j = 1; j <= k; j++){afters[j] = befores[j - 1] + befores[j];}System.arraycopy(afters, 1, befores, 1, k);}return befores[k];
}使用极小的缓存来保存所需的信息,能极大提升空间利用率和程序执行效率。
二进制法
打个比方,0b0000到0b1111,即从0到15,包含了4位中1的所有组合情况,如果我们想知道C(4, 2)的结果,只需要判断这十六个数的二进制值含2个1的数量。具体代码如下:
public static int nchoosek(int n, int k){if(n > 31){throw new IllegalArgumentException("N must be less than or equal to 31");}checknk(n, k);k = (k > (n - k)) ? n - k : k;if(k <= 1){ // C(n, 0) = 1, C(n, 1) = nreturn k == 0 ? 1 : n;}int limit = Integer.MAX_VALUE >> (31 - n);int cnk = 0;for(int i = 3; i < limit; i++){if(Integer.bitCount(i) == k){cnk++;}}return cnk;
}该方法的局限性就是判断的长度严格受整型长度限制,只能判断31以内的组合数,并且随着n越来越大,需要遍历的情况也是逐级递增。一般而言,用它获取17以内的组合数。 这句话主要依据来自于Matlab的代码,它使用该方法的判断条件就是17。
组合数计算小结
上面的这些算法都只是单纯为了解决组合数计算的问题,至于n和k过大,所产生的大数的问题,并不在这篇博文的讨论范畴,大数比较复杂,三言两语说不清楚,详细说起来可以另写一篇博文,下次有机会再说(又挖了个坑)。Java里面处理大数一般使用BigInteger和BigDecimal。
其实通过上面的相关算法我们可以看出,对于数学问题,数学公式和性质是提升算法性能的超级法宝。很多时候我们在语法层面的优化还敌不过一个简单的数学变换,因此对于数学方面的算法编写,最好是先了解数学方面的知识,再开始转为相应的算法,这样代码质量会更高点。
通过上面的两种实现方式,可以得到三点启示:一是,以后遇到累积和累除问题,或者说遇到大量乘法和除法操作,一定要注意精度和溢出问题。二是,累积时要想到数字的相关性质,对于整数,素数有时会极大简化问题。三是,对于缓存或者说打表问题,一定要注意是否存在减小开辟空间的情况,并注意操作的特性,是否能简化操作,并不是一成不变,什么操作都执行,什么都信息都保存,一定要提升内存利用率。
获取数组的组合排列
前面我们计算了全组合数,接下来我们来聊聊,如何获取数组指定数量的元素的排列组合。
二进制法
前面我们使用二进制法来获取组合数,我们知道0b0000到0b1111这16个数中,二进制中含两个1的数都互不相同,因此我们可以根据二进制中1的排列位置,来间接获取元素的排列情况。具体代码如下:
public static List<int[]> nchoosek(int[] array, int k){int n = array.length;if(n > 31){throw new IllegalArgumentException("N must be less than or equal to 31");}checknk(n, k);if(k == 0){return new ArrayList<int[]>();}if(n == k){List<int[]> combList = new ArrayList<int[]>(1);combList.add(java.util.Arrays.copyOf(array, k));return combList;}int combNum = nchoosek(n, (k > (n - k)) ? n - k : k);int bits = Integer.MAX_VALUE >> (31 - n);List<int[]> combList = new ArrayList<int[]>(combNum);for(int i = 0; i < bits; i++){if(Integer.bitCount(i) != k){continue;}int[] comb = new int[k];int index = 0;int iTemp = i;while(iTemp != 0){int lowest = iTemp & -iTemp;comb[index++] = array[(int)(Math.log(lowest) / Math.log(2))];iTemp &= iTemp - 1;}combList.add(comb);}return combList;
} 当n=31时,其所有全组合数之和为2147483647,刚好等于Integer.MAX_VALUE,如果我们直接遍历:0:2147483647,将会形成死循环。为了兼顾n = 31的特殊情况,我们就把所有n = k的情况单独拿出考虑,遍历范围变为0:。
这里面取二进制中1的具体位置思路为:先取二进制的最低位,该算法参见Integer.lowestOneBit,然后利用计算最低位的位置,最后利用x & (x - 1)将最低位及以后的位全部置零,这部分可以参考我的博文:Java计算二进制数中1的个数。
其实这部分还可以使用逐位判1来进行操作,具体实现如下:
/******** 第一种 ********/
for(int j = 0; j < n; j++){if((i & (1 << j)) >= 1){comb[index++] = array[j];}
}
/******** 第二种 ********/
for(int j = 0; j < n; j++){if(i << (31 - j)) >>> 31 == 1){comb[index++] = array[j];}
}
基本迭代法
下面是C(5, 3)的树状结构图,待排列的数组array = [1,2,3,4,5],数组长度n = 5,排列数组comb,它的长度k = 3。

在开始操作前,我们记数组array的索引值为aIndex,数组comb的索引值为cIndex,第一个数(即cIndex = 0时)只能取1、2、3,因为当我们取4时,数组array不能提供足够的数值存放在comb中,因此它的限制值limit = n - (k - cIndex),k - cIndex表示填满数组comb所需的数据量。然后迭代,从第一层取到第三层,comb满了就保存在List<int[]>列表中。具体代码如下:
public static List<int[]> nchoosek(int[] array, int k){int n = array.length;checknk(n, k);List<int[]> combList = new ArrayList<>(nchoosek(n, k > (n - k) ? n - k : k));nchoosek0(array, n, new int[k], k, 0, 0, combList);return combList;
}private static void nchoosek0(int[] array, int n, int[] comb, int k,int aIndex, int cIndex, List<int[]> combList){if(cIndex == k){combList.add(Arrays.copyOf(comb, k));return;}for(int i = aIndex, limit = n - (k - cIndex); i <= limit; i++){comb[cIndex++] = array[i];nchoosek0(array, n, comb, k, i + 1, cIndex, combList);cIndex--;}
}其实上面中的cIndex == k的情况,可以直接放在for循环里面进行处理,经测试,两者并无效率差距。上面代码量比较小,只是迭代遍历取值罢了,它的思想和整数划分比较像,下次有机会写篇整数划分的文章(又挖了个坑)。
从后向前迭代法(Matlab版本)
前面那个方法是从上向下进行迭代,其实我们也可以从下向上迭代。这里我以1的那个树状结构作为例子进行说明。

后面的2和3都是采用这样的方式进行操作。具体代码如下:
public static int[][] nchoosek(int[] array, int k){int n = array.length;checknk(n, k);if(k == 0){return new int[1][0];}return nchoosek0(array, n, k);
}private static int[][] nchoosek0(int[] array, int n, int k){int[][] comb = null;if(n == k){comb = new int[1][n];for(int i = 0; i < n; i++){comb[0][i] = array[i];}return comb;}if(k == 1){comb = new int[n][1];for(int i = 0; i < n; i++){comb[i][0] = array[i];}return comb;} for(int i = 0, limit = n - k + 1; i < limit; i++){int[][] next = nchoosek0(Arrays.copyOfRange(array, i + 1, n), n - i - 1, k - 1); // Get all possible values for the next oneint combRowLen = comb == null ? 0 : comb.length;int totalRowLen = next.length + combRowLen;int totalColLen = next[0].length + 1;int[][] tempComb = new int[totalRowLen][totalColLen];if(comb != null){ // TempComb capacity expansion combfor(int j = 0; j < combRowLen; j++){tempComb[j] = Arrays.copyOf(comb[j], totalColLen);}}int value = array[i];for(int row = combRowLen; row < totalRowLen; row++){ tempComb[row][0] = value; // The value completes the current onefor(int col = 1; col < totalColLen; col++){ // Copy the next one.tempComb[row][col] = next[row - combRowLen][col - 1];}}comb = tempComb;}return comb;
}结合前面的图示来看这个代码,思路还是比较清晰的。这个代码网上并没有任何博文或者资料介绍过,这个算法纯粹是来自于Matlab(我的是2014a版本)的nchoosek函数下的combs函数,函数上注释了这么一句话:This function is only practical for situations where M is less than about 15。也就是说该函数最好是处理K<15的情况,因为K越大,迭代的次数越多,效率也就越低。
从后向前优化法
我们把所有C(5, 3)的所以情况打印如下:

在图上我们可以看出,红色框框部分,以2为首的矩阵,它的二三列数据都在1为首的矩阵中。对于紫色框框,3为首的数据,同样也包含在2为首的矩阵中。因此我们只需要把1为首的所有情况求出来,其余的都可以复制矩阵块即可,这大大提高了原先从后向前迭代法的效率。具体代码如下:
public static int[][] nchoosek(int[] array, int k){int n = array.length;checknk(n, k);if(k == 0){return new int[1][0];}int combNum = nchoosek(n, k > (n - k) ? n - k : k);int[][] comb = new int[combNum][k];int rowEndIndex = n - k + 1;for(int i = 0, k1 = k - 1; i < rowEndIndex; i++){ // Fill the right-most side.comb[i][k1] = array[k1 + i];}for(int begin = k - 2; begin >= 0; begin--){int rowLen = rowEndIndex;int previousRowEndIndex = rowEndIndex;for(int i = 0; i < rowEndIndex; i++){comb[i][begin] = array[begin];}for(int next = begin + 1, limit = begin + n - k; next <= limit; next++){ int selectionNum = n - k + 1 + begin - next;int allPossibleNum = n - next;rowLen = rowLen * selectionNum / allPossibleNum;int rowBeginIndex = rowEndIndex;rowEndIndex = rowBeginIndex + rowLen;int nextVal = array[next];for(int i = rowBeginIndex; i < rowEndIndex; i++){comb[i][begin] = nextVal;for(int j = begin + 1; j < k; j++){comb[i][j] = comb[previousRowEndIndex - rowLen + i - rowBeginIndex][j];}}}}return comb;
}这方法相比于原先迭代方法,不仅不需要扩容comb矩阵,而且无需迭代,并且没有重复运算,将第一个计算完了,后面都可以通过复制矩阵块来完成。这方法在Matlab上面运行效率比Matlab自带的库函数高,随着K值增大,两者差距越来越大。这个算法主要参见这篇文章:[代码提速实战] nchoosek的提速(28X)。因为Matlab对矩阵的下标操作和Java不同,因此修改将Matlab代码转换为Java代码时,一定要格外注意下标问题。
组合排列小结
组合排列其实和整数划分和全排列一般,都是通过迭代进行操作,但是迭代就有缓存的可能,因此以后遇到迭代问题,一定要考虑缓存问题,以此来优化算法。
后记
总算写完,哎,手的敲疼了,其实也不知道能有多少人坚持看到这里。算法的学习毕竟是枯燥,希望自己能坚持到底。又是十二点多了,下次要注意了。不知道有没有时间把整数划分和全排列补上,看心情吧,哈哈哈!
![[组合] 组合数计算四大算法模板(模板+卢卡斯定理)](https://img-blog.csdnimg.cn/20201102165926335.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lsX3B1eXU=,size_16,color_FFFFFF,t_70#pic_center)