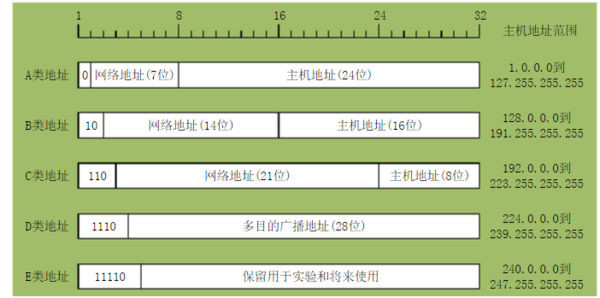
一、注释
=pod
这里的是注释
=cut
二、chomp
去掉换行符(\n)
去掉$/
chomp($text=<STDIN>); #读入,但不含换行符
三、<STDIN>
$line = <STDIN>; #一次读一行,性能好。
<STDIN>会带有换行符,通常都会加上chomp()操作符去掉换行符,
四、钻石尖括号<>
使用两个尖括号表示读取来自文件的输入,可以从命令行中传递文件到<>。
$ ./test.plx test.log


当不注释掉 chomp($line)的时候,运行结果如下。可以发现,显示出来的例子去掉了换行符。

五、文件读取
(1) 打开文件常用 open()函数,open() or die ().
open(FILEVAR,"file1") or die ("can not oen input .FILEVAR \n");
(2) 读文件
$line=<FILEVAR>;从文件中读取一行数据存储到简单变量 $line 中,并把文件指针向后移动一行。
@array= <FILEVAR>;把文件的全部内容读入数组@array,文件的每一行为@array的一个元素。很多时候用chomp(@array=<FILEVAR>);去掉行末换行符。
(3)写文件
open(OUTFILE,">outfile");>大于号为写入文件,后跟文件名。
六、split函数
把字符串进行分割并把分割后的结果放入数组中。
split(/\s+/,$line)表示把字符串$line,按空格为界分开。七、正则匹配
(1)删除以数字开头的行
%s/^\d.*$//g(2)删除以abc开头的行
%s/^[a|b|c].*$//g
或者
%s/^abc.*$//g(3)删除以a或者b或者c开头的行
%s/^[abc].*$//g(4)删除重复行
1、将两行重复行压缩成一行%s/^\(.*\)\n\1$/\1/g\( \)有保存功能,将括号内的内容保存。后面的\1表示此内容复现。
2、将连续多次重复行压缩成一行%s/^\(.*\)\(\n\1\)\+$/\1/g出现的\( \)内容,\(.*\)用\1来表示,\(\n\1\)可以用\2来表示八、函数式
s/替换内容/\=函数式
%s/\<id\>/\=line(".")<>表示词首或词尾,line(".")表示行号