Dense Passage Retrieval for Open-Domain Question Answering
https://github.com/facebookresearch/DPR
摘要
开放域问题回答依赖于有效的段落检索来选择候选上下文,其中传统的稀疏向量空间模型,如TF-IDF或BM25,是事实上的方法。作者表明检索实际上可以单独使用密集表示来实现,其中embedding是通过简单的dual-encoder framework从少量的questions 和 passages 中学习的。评估时,前20个段落检索准确性方面优于BM25系统9%-19%。
介绍
将open-domain QA 转换为机器阅读(一个retriever和一个reader)是一个非常合理的策略,但是这么做往往会导致性能下降,所以需要改进retriever。
以往的open-domain QA使用TF-IDF和BM25检索相关passages,这些方法无法匹配具有相同语义的上下文信息。dense(潜在语义编码)可以解决这个问题。
但是,人们普遍认为,学习一个好的dense向量表示需要大量的问题和上下文的标记对。因此,在ORQA 出现之前,dense检索方法在open-domain QA方面从未表现出优于TF-IDF/BM25,ORQA提出了一个复杂的逆完形填空任务(ICT)目标,预测包含Mask句子的block,用于额外的预处理。然后使用成对的问题和答案对问题编码器和阅读器模型进行微调。尽管ORQA成功地证明了密集检索的性能优于BM25,在多个开放域上设置了新的最先进的结果,但是也有一些弱点:
- 首先,ICT的预训练需要大量的计算复杂度,并且尚不清楚完全一致的句子是否是目标函数中question的良好替代品。
- 其次,因为上下文编码器没有使用成对的问题和答案进行微调,所以相应的表示可能不是最佳的。
在这篇文章中,作者提出了这样一个问题:**是否只使用成对的问题和段落(或答案)来训练一个更好的密集嵌入模型,而不需要额外的预处理?**通过利用现在标准的BERT预训练模型和dual-encoder framework,使用相对少量的问题和段落对开发正确的训练方案。
DPR
DPR使用一个dense encode : E E E P _P P ( ( ( ⋅ · ⋅ ) ) ),它将任何文本passages映射到一个实值向量,并为将用于检索的所有 M M M个passages建立一个索引。
run-time,另一个encoder : E E E Q _Q Q ( ( ( ⋅ · ⋅ ) ) )映射输入question为一个 d d d维的向量,然后根据相似度(doc 乘)检索前 K K K个passages.
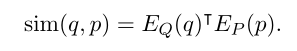
Encoder
encoder使用两个独立的BERT,取[CLS] token 作为输出( d d d=768)
Inference
在推理过程中,将passages encoder E E E P _P P应用于所有passages,并使用FAISS (Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2017.Billion-scale similarity search with GPUs. ArXiv,abs/1702.08734.)离线对它们进行索引。FAISS是一个非常高效的开源库,用于密集向量的相似性搜索和聚类,可以轻松应用于数十亿个向量。在运行时给定一个问题 q q q,导出它的嵌入 v q v_q vq= E E E Q _Q Q ( ( ( q q q ) ) ),并检索嵌入最接近 v q v_q vq的前 k k k个passages。
Training
训练encoder,使点积相似度成为一个好的检索排序函数本质上是一个度量学习问题。目标是通过学习一个更好的嵌入函数来创建一个向量空间,使得相关的成对问题和段落比不相关的问题和段落具有更小的距离(即,更高的相似性)。
训练数据( m m m个例子):
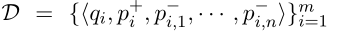
包含一个正例子, n n n个负例,Loss Function(negative log likelihood of the positive passage):
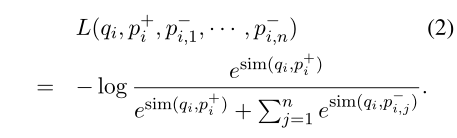
Positive and negative passages
对于检索问题,通常情况下正面例子是显式可用的,而负面例子需要从一个非常大的库中选择。例如,与问题相关的段落可以在QA数据集中给出,或者可以使用Answer找到。集合中的所有其他段落,虽然没有明确指定,但默认情况下可以被视为负例。在实践中,如何选择负面的例子往往被忽视,但可能是学习高质量编码器的决定性因素,本文考虑三种采样方式
- Random:随机在corpus取样作为负例
- BM25:取不包含最佳匹配question的BM25检索的passages作为负例。
- Gold:取其他question的精确匹配passages作为当前question的负例。
In-batch negatives
假设在一个mini-batch中有 B B B个questions,每个question都与一个相关的passage相关联。设 Q Q Q和 P P P为一批总量为 B B B的questions和passages嵌入的( B B B× d d d)矩阵( d d d是BERT [CLS] 位置的token向量,维度为 d d d), S S S = Q Q Q P P P T ^T T是( B B B × B B B)的相似度得分矩阵,其中每一行对应一个question,与 B B B个passages配对。这样,在每个batch中有效地训练 B 2 B^2 B2( q i q_i qi, p j p_j pj)个questions/passages对。当 i i i = j j j时,任何( q i q_i qi, p j p_j pj)对都是正例,否则为负例。这将在每一batch中创建 B B B个训练实例,其中每个问题都有 B B B − - − 1 1 1个负例。这样可以大大增加训练样本的数量。
Experimental Setup
Wikipedia Data Pre-processing
使用2018年12月20日的英文维基百科转储作为回答问题的源文档。首先应用DrQA代码处理数据。这一步将删除半结构化数据,如表格、信息框、列表以及歧义消除页面。然后,将每篇文章分成多个不相交的100个单词的文本block(passsage)作为基本检索单元,最终得到21,015,324篇文章。每篇文章还附有文章来源的维基百科文章的标题以及[ S S S E E E P P P]标记。
Question Answering Datasets
Natural Questions (NQ)
TriviaQA
WebQuestions (WQ)
CuratedTREC (TREC)
SQuAD v1.1
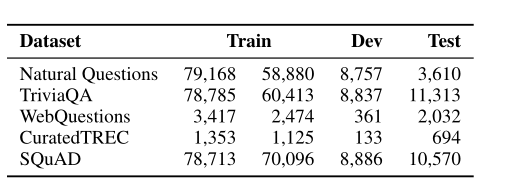
Train中的两列表示数据集中的原始训练示例和过滤后用于训练DPR的实际question。
Selection of positive passages
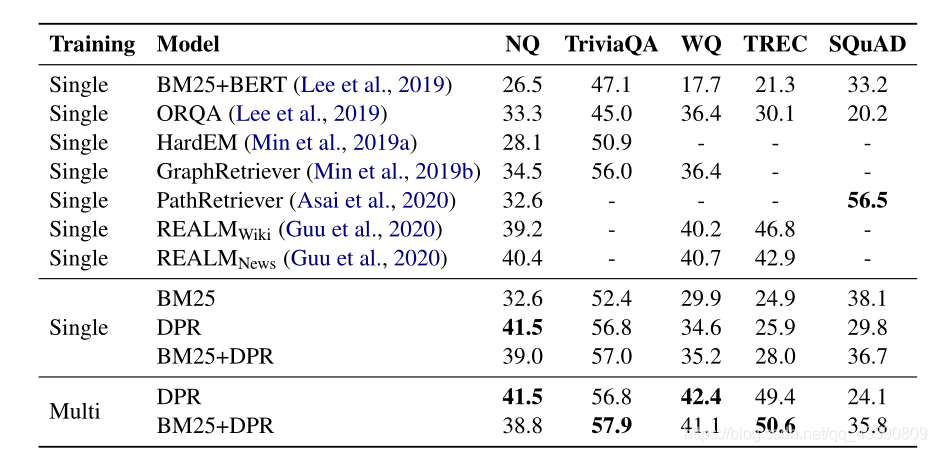
因为在TREC、WQ和TriviaQA中只提供成对的问题和答案,所以作者使用BM25中包含答案的最高等级的段落作为psoitive段落。如果检索到的前100篇文章都没有答案,则该问题将被丢弃。对于SQuAD v1.1和NQ,由于原始段落的分割和处理不同于我们的候选段落池,我们将每个黄金段落与候选段落池中的相应段落进行匹配和替换。当匹配因维基百科版本或预处理不同而失败时,我们会丢弃这些问题。上表显示了所有数据集的训练/开发/测试集中的问题数量以及用于训练检索器的实际问题。
Experiments: Passage Retrieval
实验中使用的DPR模型是使用in-batch negative setting训练的,批大小为128,每个question增加一个BM25的negative通道。为大数据集(NQ、TriviaQA、SQuAD v1.1)训练了40个epochs的questions和passages encoder ,为小数据集(TREC、WQ)训练了100个纪元的questions和passages encoder,使用Adam的学习率为10 − ^- − 5 ^5 5,linear scheduling with warm-up和dropout为0.1。

虽然让检索器适应每个数据集是很好的,但也希望获得一个在所有情况下都能很好工作的检索器。为此,作者通过组合来自所有数据集(不包括SQuAD v1.1)的训练数据来训练多数据集encoder。除了DPR还展示了BM25(参数b = 0.4和k1= 0.9)、BM25+DPR的结果,使用它们的分数的线性组合作为新的排序函数。具体来说,分别获得基于BM25和DPR检索的前2000篇文章,并使用BM25 ( ( ( q q q , , , p p p ) ) ) + λ λ λ sim ( ( ( q q q , , , p p p)作为排序函数对它们的并集进行了rerank。其中λ = 1.1。Multi表示数据集融合后的结果
Ablation Study on Model Training
实验用1000个例子训练的DPR已经超过了BM25:
In-batch negative training

N:负例的数量
IB:in-batch training.
Experiments: Question Answering
bert(base, uncased)
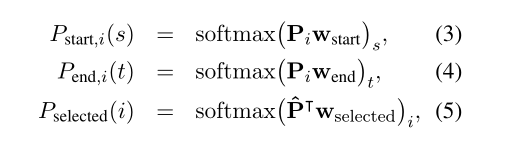
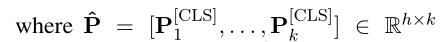
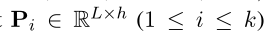
表示第 i i i个passage,L是passage的最大长度。
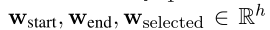
是可学习的参数。
在training期间,从检索系统(BM25或DPR)返回的前100篇文章中为每个问题抽取一篇正面文章和 m m m − - − 1 1 1篇负面文章。m是查参数为24,目标函数为最大化所有passages中正确答案跨度的对数似然
结果