最近接到任务说要使用jstorm处理业务,之前没接触过,只能硬着头皮来,接下来谈谈我这两天的收获
1,怎么了解jstorm,这个答案没什么固定的,但是我个人比较喜欢去看官方的文档,如果官方的文档实在找不到了,再去baidu,baidu不到那就只能翻墙google了,如果还是找不到。。没办法,看源代码吧;
对于官方文档,我现在能找到的只有:
https://github.com/alibaba/jstorm/wiki/JStorm-Chinese-Documentation
该地址是jstorm的中文文档,上面对jstorm做了简要的概述,内容并不是很多,看完了, 至少能对jstorm有个大体的了解
因为我看博客的时候,喜欢在博客上直接找到答案,所以我在这里赘述一下
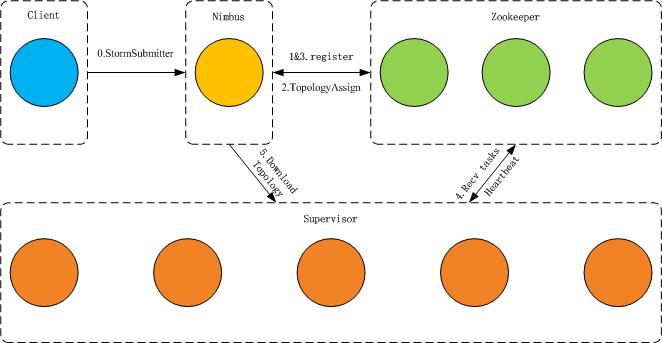
根据ali的文档得知,jStorm是一个分布式实时计算引擎,jstorm是 从storm发展而来,由ali爸爸开源的,是一个类似Hadoop MapReduce的系统,用户创建任务后,提交给jstorm系统,JStorm系统会将这个任务跑起来,7*24不间断,如果一个worker发生一碗,立即分配一个worker来替换失效的worker(这段文字摘自 alibaba的github),从系统的角度来说,jstorm是类似Mapreduce的调度系统,从数据的角度来说,Jstorm是一套基于流水线的消息处理机制;
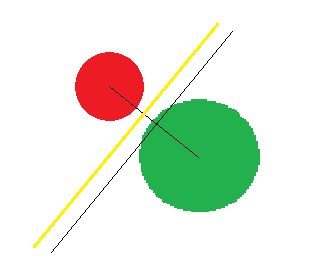
说到流水线,你能想到什么?至少从流水两个字,我想到了管道,其实个人理解jstorm的流水线很像是管道,想象一下,一个主管道可以分出多个支流管道,也可以接一个弯管或者其他什么不一样的管,来看张图

这个图完全是偷ali的,在看另一张

也是偷的,从这两张图就可以形象的看出jstorm的思想了
接下来解释几个重要的概念:
1,topology
我的英文差,只能音译了。。拓扑结构图,其实也差不多是这个意思
jstorm所执行的任务,其实就是一个topology,一个topology可以包含多个spout,多个bolt,多级bolt
2,spout
流的来源
3,bolt
可以说是流的去处(这里可以进行业务处理)
简单来说:在jstorm运行环境正常的情况下,开发人员要做的就是
建立一个topology,建立若干spout,建立若干bolt,然后将spout加入到topology,将bolt也加入到topology,这时组成了一个相对完整的拓扑结构图,然后提交给jtorm,齐活!
说起来比较简单,那么实际写起来呢,来看下面的代码
注意⚠️:有个前提是jstorm运行环境正常,
首先是配置文件:看过其他博客的人知道有*.ynml的文件,主要是内容是对拓扑结构的配置,这个建议新手可以直接忽略,先不做修改,仔细研读官方的文档之后再尝试
经过上面的解释,我们知道一个拓扑结构包涵哪些东西了。其实代码也是差不多的
首先:一个TestSpout.java
import java.util.Map;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class TestSpout extends BaseRichSpout {
private static final long serialVersionUID = 4924189748702648696L;
private static final Logger LOG = LoggerFactory.getLogger(TestSpout.class);
SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
this.collector.emit(new Values("test123"));
// this.collector.emit("VEHICLEINFO", new Values("test123"));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("VEHICLE"));
// declarer.declareStream("VEHICLEINFO", new Fields("VEHICLE"));
}
}
继承自BaseRichSpout,需要覆盖三个方法,分别来说下:
open:这个应该是在创建拓扑结构,提交的时候会调用一次,具体我没细研究,基本都是这么写
nextTuple:发送数据的源头,发送的方式是调用SpoutOutputCollector.emit方法,数据的方式就是用Values做封装,这里注意下:jstorm的流支持任何可序列化的数据类型,包括bean,只要是可序列化的就可以,数据的来源,看你的应用场景,可以来自数据库,也可以来自mq,或者是Kafka等等,我们做测试,直接写死就好了
declareOutputFields: 这里一开始一直没搞明白是干嘛的,通过无数次失败,发现,其实他是emit对应的,采用未注视的方式提交的时候,在此方法中 new Fields的值启示就是对应Values的值,是一个建值对,在bolt里面可以通过input.getValueByFiled()的方式获取 (get方法名我写了个大概,可能写错,各位亲自己 点 一下就出来了)
那么注视的掉的是什么情况呢,首先注视掉的emit第一个参数是streamId,就相当于我指定要发给谁,本方法中注视掉的是和emit对应的
2,来一个TestBolt
import java.util.Map;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple;
public class TestBolt extends BaseRichBolt {
private static final long serialVersionUID = 1804939402092249890L;
private static final Logger LOG = LoggerFactory.getLogger(TestBolt.class);
OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String s = input.getString(0);
String sf = input.getStringByField("VEHICLE");
LOG.error("receive MSG----------------------" + s + " ---- " + sf);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
这个只有方法execute可以说一说,就是获取数据,tuple就是一个数据流,里面有你的数据,你可以通过get参数序号的方式,也可以用Field方式,而这个getValueByField的值就是上面spout中定义的,有兴趣的自己回顾一下
3,来一个TestTopology
import java.util.HashMap;
import java.util.Map;
import com.zuche.jstom.example.topology.spout.TestSpout;
import com.zuche.jstom.example.topology.spout.bolt.TestBolt;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TestTopology {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("testspout", new TestSpout(), 1);
builder.setBolt("testbolt", new TestBolt(), 1).shuffleGrouping("testspout");
// builder.setBolt("testbolt", new TestBolt(), 1).shuffleGrouping("testspout", "VEHICLEINFO");
Map<Object,Object> conf = new HashMap<Object, Object>();
conf.put(Config.TOPOLOGY_WORKERS, 3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("testTopology", conf, builder.createTopology());
}
}
这个就是拼装topology的过程,仔细看的发现有个注视的,这个注视的就是上面说的,我指定这个bolt处理哪个streamId的数据,和前面的spout对应起来,仔细看看
接下里就是直接跑就行了
这里说下:如果本地搭建了环境,跑的时候发现有个slf4j的版本不支持的错误信息,是因为jstorm使用了1.4的版本slf4j,你把她们exclude掉,然后自己引入一个高版本的就行了
那么来说说多个bolt的情况
其实就是在上面的代码再加一行代码:
builder.setBolt("testbolt2", new TestBolt2(), 1).shuffleGrouping("testbolt");
记得自己写个TestBolt2,这是数据流就是 testspout > testbolt > testbolt2
这里要说下shuffleGrouping,jstorm中有几个类似后缀的方法,具体的含义大家看文档,我就不多说了,他们的功能并不相同
可以说为了实现同一个目的,可以有好几种写法,但是具体哪个好,还是大家自己体会,我也是新手,不懂。。
举个例子:
builder.setSpout(LocalSpout.LOCAL_SPOUT_NAME, new LocalSpout(), 1);
builder.setBolt(FenceBolt.FENCE_BOLT_NAME, new FenceBolt(), 1).shuffleGrouping(LocalSpout.LOCAL_SPOUT_NAME);
// builder.setBolt(AlarmBolt.ALARM_BOLT_NAME, new AlarmBolt(), 1).shuffleGrouping(FenceBolt.FENCE_BOLT_NAME);
// builder.setBolt(AlarmBolt.ALARM_BOLT_NAME, new AlarmBolt(), 1).fieldsGrouping(FenceBolt.FENCE_BOLT_NAME , new Fields("FENCEVEHICLE"));
builder.setBolt(AlarmBolt.ALARM_BOLT_NAME, new AlarmBolt(), 1).shuffleGrouping(FenceBolt.FENCE_BOLT_NAME, FenceBolt.FENCE_STREAM_ID);
一个spout,两个连续的bolt,第二个bolt的配置方式,三种写法都可以
深层次的区别我还没体会出来,等我体会出来了,再和大家交流
到此,本文结束,有时间话,我会再写一篇介绍概念的