1、What——JStorm是什么?
概述:
JStorm 是一个分布式实时计算引擎,类似Hadoop MapReduce的系统, 用户按照规定的编程规范实现一个任务,然后将这个任务递交给JStorm系统,Jstorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个worker 发生意外故障, 调度器立即分配一个新的worker替换这个失效的worker。因此,从应用的角度,JStorm 应用是一种遵守某种编程规范的分布式应用。从系统角度,JStorm一套类似MapReduce的调度系统。从数据的角度,是一套基于流水线的消息处理机制。实时计算现在是大数据领域中最火爆的一个方向,因为人们对数据的要求越来越高,实时性要求也越来越快,传统的 Hadoop Map Reduce,逐渐满足不了需求,因此在这个领域需求不断。
在Storm和JStorm出现以前,市面上出现很多实时计算引擎,但自storm和JStorm出现后,基本上可以说一统江湖,
其优点:
- 开发非常迅速: 接口简单,容易上手,只要遵守Topology,Spout, Bolt的编程规范即可开发出一个扩展性极好的应用,底层rpc,worker之间冗余,数据分流之类的动作完全不用考虑。
- 扩展性极好:当一级处理单元速度,直接配置一下并发数,即可线性扩展性能
- 健壮:当worker失效或机器出现故障时, 自动分配新的worker替换失效worker;调度器Nimbus采用主从备份,支持热切。
- 数据准确性: 可以采用Acker机制,保证数据不丢失。 如果对精度有更多一步要求,采用事务机制,保证数据准确。
应用场景:
JStorm处理数据的方式是基于消息的流水线处理, 因此特别适合无状态计算,也就是计算单元的依赖的数据全部在接受的消息中可以找到, 并且最好一个数据流不依赖另外一个数据流。
- 日志分析:从日志中分析出特定的数据,并将分析的结果存入外部存储器如数据库。目前,主流日志分析技术就使用JStorm或Storm
- 管道系统: 将一个数据从一个系统传输到另外一个系统, 比如将数据库同步到Hadoop
- 消息转化器: 将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件
- 统计分析器: 从日志或消息中,提炼出某个字段,然后做count或sum计算,最后将统计值存入外部存储器。中间处理过程可能更复杂。
- ......
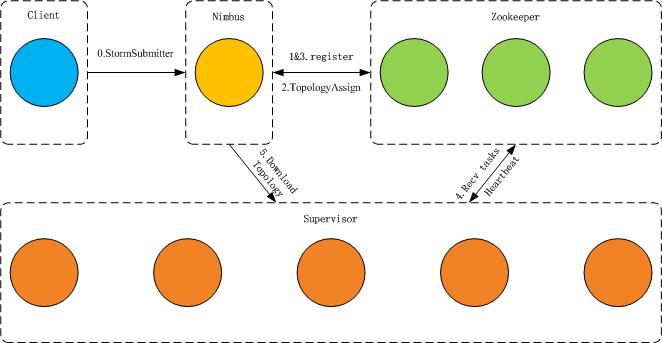
JStorm架构:
JStorm 从设计的角度,就是一个典型的调度系统。
在这个系统中,
-
- Nimbus是作为调度器角色
- Supervisor 作为worker的代理角色,负责杀死worker和运行worker
- Worker是task的容器
- Task是真正任务的执行者
- ZK 是整个系统中的协调者
具体参考下图:
来自阿里的流处理框架:JStorm
关于流处理框架,在先前的文章汇总已经介绍过Strom,今天学习的是来自阿里的的流处理框架JStorm。简单的概述JStorm就是:JStorm 比Storm更稳定,更强大,更快,Storm上跑的程序,一行代码不变可以运行在JStorm上。直白的讲JStorm是阿里巴巴的团队基于Storm的二次开发产物,相当于他们的Tengine是基于Nginx开发的一样。以下为阿里巴巴团队放弃直接使用Storm选择自行开发JStorm的原因:
2、Why——为什么启动JStorm项目?___与storm的区别
阿里拥有自己的实时计算引擎
- 类似于hadoop 中的MR
- 开源storm响应太慢
- 开源社区的速度完全跟不上Ali的需求
- 降低未来运维成本
- 提供更多技术支持,加快内部业务响应速度
现有Storm无法满足一些需求
- 现有storm调度太简单粗暴,无法定制化
- Storm 任务分配不平衡
- RPC OOM(OOM - Out of Memory,内存溢出 ——俗称雪崩问题)一直没有解决
- 监控太简单
- 对ZK 访问频繁
现状
在整个阿里巴巴集团,1000+的物理机上运行着Storm,一淘(200+),CDO(200+),支付宝(150+),B2B(50+),阿里妈妈(50+),共享事业群(50+),其他等。
WHY之一句话概述:JStorm比Storm更稳定,功能更强大,更快!(Storm上跑的程序可以一行代码不变运行在JStorm上)
JStorm相比Storm更稳定
- Nimbus 实现HA:当一台nimbus挂了,自动热切到备份nimbus ——Nimbus HA
- 原生Storm RPC:Zeromq 使用堆外内存,导致OS 内存不够,Netty 导致OOM;JStorm底层RPC 采用netty + disruptor,保证发送速度和接受速度是匹配的,彻底解决雪崩问题
- 现有Strom,在添加supervisor或者supervisor shutdown时,会触发任务rebalance;提交新任务时,当worker数不够时,触发其他任务做rebalance。——在JStorm中不会发生,使得数据流更稳定
- 新上线的任务不会冲击老的任务:新调度从cpu,memory,disk,net 四个角度对任务进行分配;已经分配好的新任务,无需去抢占老任务的cpu,memory,disk和net ——任务之间影响小
- Supervisor主线 ——more catch
- Spout/Bolt 的open/prepare ——more catch
- 所有IO, 序列化,反序列化 ——more catch
- 减少对ZK的访问量:去掉大量无用的watch;task的心跳时间延长一倍;Task心跳检测无需全ZK扫描。
JStorm相比Storm调度更强大
- 彻底解决了storm 任务分配不均衡问题
- 从4个维度进行任务分配:CPU、Memory、Disk、Net
- 默认一个task,一个cpu slot。当task消耗更多的cpu时,可以申请更多cpu slot
- 解决新上线的任务去抢占老任务的cpu
- 一淘有些task内部起很多线程,单task消耗太多cpu
- 默认一个task,一个memory slot。当task需要更多内存时,可以申请更多内存slot
- 先海狗项目中,slot task 需要8G内存,而且其他任务2G内存就够了
- 默认task,不申请disk slot。当task 磁盘IO较重时,可以申请disk slot
- 海狗/实时同步项目中,task有较重的本地磁盘读写操作
- 可以强制某个component的task 运行在不同的节点上
- 聚石塔,海狗项目,某些task提供web Service服务,为了端口不冲突,因此必须强制这些task运行在不同节点上
- 可以强制topology运行在单独一个节点上
- 节省网络带宽
- Tlog中大量小topology,为了减少网络开销,强制任务分配到一个节点上
- 可以自定义任务分配:提前预约任务分配到哪台机器上,哪个端口,多少个cpu slot,多少内存,是否申请磁盘
- 海狗项目中,部分task期望分配到某些节点上
- 可以预约上一次成功运行时的任务分配:上次task分配了什么资源,这次还是使用这些资源
- CDO很多任务期待重启后,仍使用老的节点,端口
Task内部异步化
- Worker内部全流水线模式
- Spout nextTuple和ack/fail运行在不同线程
-
- EagleEye中,在nextTuple做sleep和wait操作不会block ack/fail动作
JStorm相比Storm性能更好
JStorm 0.9.0 性能非常的好,使用netty时单worker 发送最大速度为11万QPS,使用zeromq时,最大速度为12万QPS。
- JStorm 0.9.0 在使用Netty的情况下,比Storm 0.9.0 使用netty情况下,快10%, 并且JStorm netty是稳定的而Storm 的Netty是不稳定的
- 在使用ZeroMQ的情况下, JStorm 0.9.0 比Storm 0.9.0 快30%
为什么更快、性能提升的原因:
- Zeromq 减少一次内存拷贝
- 增加反序列化线程
- 重写采样代码,大幅减少采样影响
- 优化ack代码
- 优化缓冲map性能
- Java 比clojure更底层
附注:和storm编程方式的改变:
编程接口改变:当topology.max.spout.pending 设置不为1时(包括topology.max.spout.pending设置为null),spout内部将额外启动一个线程单独执行ack或fail操作, 从而nextTuple在单独一个线程中执行,因此允许在nextTuple中执行block动作,而原生的storm,nextTuple/ack/fail 都在一个线程中执行,当数据量不大时,nextTuple立即返回,而ack、fail同样也容易没有数据,进而导致CPU 大量空转,白白浪费CPU, 而在JStorm中, nextTuple可以以block方式获取数据,比如从disruptor中或BlockingQueue中获取数据,当没有数据时,直接block住,节省了大量CPU。
但因此带来一个问题, 处理ack/fail 和nextTuple时,必须小心线程安全性。
附属: 当topology.max.spout.pending为1时, 恢复为spout一个线程,即nextTuple/ack/fail 运行在一个线程中。
JStorm的其他优化点
- 资源隔离。不同部门,使用不同的组名,每个组有自己的Quato;不同组的资源隔离;采用cgroups 硬隔离
- Classloader。解决应用的类和Jstorm的类发生冲突,应用的类在自己的类空间中
- Task 内部异步化。Worker 内部全流水线模式,Spout nextTuple和ack/fail运行在不同线程
JStorm与其它产品的比较:
Flume 是一个成熟的系统,主要focus在管道上,将数据从一个数据源传输到另外一个数据源, 系统提供大量现成的插件做管道作用。当然也可以做一些计算和分析,但插件的开发没有Jstorm便捷和迅速。
S4 就是一个半成品,健壮性还可以,但数据准确性较糟糕,无法保证数据不丢失,这个特性让S4 大受限制,也导致了S4开源很多年,但发展一直不是很迅速。
AKKA 是一个actor模型,也是一个不错的系统,在这个actor模型基本上,你想做任何事情都没有问题,但问题是你需要做更多的工作,topology怎么生成,怎么序列化。数据怎么流(随机,还是group by)等等。
Spark 是一个轻量的内存MR, 更偏重批量数据处理。
3、JStorm性能优化:
- 选型:
按照性能来说, trident < transaction < 使用ack机制普通接口 < 关掉ack机制的普通接口, 因此,首先要权衡一下应该选用什么方式来完成任务。
如果“使用ack机制普通接口”时, 可以尝试关掉ack机制,查看性能如何,如果性能有大幅提升,则预示着瓶颈不在spout, 有可能是Acker的并发少了,或者业务处理逻辑慢了。
- 增加并发:可以简单增加并发,查看是否能够增加处理能力
- 让task分配更加均匀:当使用fieldGrouping方式时,有可能造成有的task任务重,有的task任务轻,因此让整个数据流变慢, 尽量让task之间压力均匀。
- 使用MetaQ或Kafka时:对于MetaQ和Kafka, 一个分区只能一个线程消费,因此有可能简单的增加并发无法解决问题, 可以尝试增加MetaQ和Kafka的分区数。
4、常见问题:
- 开发经验总结
- 运维经验总结
4.1 性能问题
参考上面3中JStorm性能优化
4.2 资源不够
当报告 ”No supervisor resource is enough for component “, 则意味着资源不够 如果是仅仅是测试环境,可以将supervisor的cpu 和memory slot设置大,
在jstorm中, 一个task默认会消耗一个cpu slot和一个memory slot, 而一台机器上默认的cpu slot是(cpu 核数 -1), memory slot数(物理内存大小 * 75%/1g), 如果一个worker上运行task比较多时,需要将memory slot size设小(默认是1G), 比如512M, memory.slot.per.size: 535298048

1 #if it is null, then it will be detect by system 2 supervisor.cpu.slot.num: null 3 4 #if it is null, then it will be detect by system 5 supervisor.mem.slot.num: null 6 7 # support disk slot 8 # if it is null, it will use $(storm.local.dir)/worker_shared_data 9 supervisor.disk.slot: null
4.3 序列化问题
所有spout,bolt,configuration, 发送的消息(Tuple)都必须实现Serializable, 否则就会出现序列化错误.
如果是spout或bolt的成员变量没有实现Serializable时,但又必须使用时, 可以对该变量申明时,增加transient 修饰符, 然后在open或prepare时,进行实例化
4.4 Log4j 冲突
0.9.0 开始,JStorm依旧使用Log4J,但storm使用Logbak,因此应用程序如果有依赖log4j-over-slf4j.jar, 则需要exclude 所有log4j-over-slf4j.jar依赖,下个版本将自定义classloader,就不用担心这个问题。
1 SLF4J: Detected both log4j-over-slf4j.jar AND slf4j-log4j12.jar on the class path, preempting StackOverflowError. 2 SLF4J: See also 3 http://www.slf4j.org/codes.html#log4jDelegationLoop for more details. 4 Exception in thread "main" java.lang.ExceptionInInitializerError 5 at org.apache.log4j.Logger.getLogger(Logger.java:39) 6 at org.apache.log4j.Logger.getLogger(Logger.java:43) 7 at com.alibaba.jstorm.daemon.worker.Worker.<clinit>(Worker.java:32) 8 Caused by: java.lang.IllegalStateException: Detected both log4j-over-slf4j.jar AND slf4j-log4j12.jar on the class path, preempting StackOverflowError. See also 9 http://www.slf4j.org/codes.html#log4jDelegationLoop for more details. 10 at org.apache.log4j.Log4jLoggerFactory.<clinit>(Log4jLoggerFactory.java:49) 11 ... 3 more 12 Could not find the main class: com.alibaba.jstorm.daemon.worker.Worker. Program will exit.
4.5 类冲突
如果应用程序使用和JStorm相同的jar 但版本不一样时,建议打开classloader, 修改配置文件
1 topology.enable.classloader: true
或者
1 ConfigExtension.setEnableTopologyClassLoader(conf, true);
JStorm默认是关掉classloader,因此JStorm会强制使用JStorm依赖的jar
4.6 提交任务后,等待几分钟后,web ui始终没有显示对应的task
有3种情况:
4.6.1用户程序初始化太慢
如果有用户程序的日志输出,则表明是用户的初始化太慢或者出错,查看日志即可。 另外对于MetaQ 1.x的应用程序,Spout会recover ~/.meta_recover/目录下文件,可以直接删除这些消费失败的问题,加速启动。
4.6.2通常是用户jar冲突或初始化发生问题
打开supervisor 日志,找出启动worker命令,单独执行,然后检查是否有问题。类似下图:
4.6.3检查是不是storm和jstorm使用相同的本地目录
检查配置项 ”storm.local.dir“, 是不是storm和jstorm使用相同的本地目录,如果相同,则将二者分开
4.7 提示端口被绑定
有2种情况:
4.7.1多个worker抢占一个端口
假设是6800 端口被占, 可以执行命令 “ps -ef|grep 6800” 检查是否有多个进程, 如果有多个进程,则手动杀死他们
4.7.2系统打开太多的connection
Linux对外连接端口数限制,TCP client对外发起连接数达到28000左右时,就开始大量抛异常,需要
1 # echo "10000 65535" > /proc/sys/net/ipv4/ip_local_port_range
5、TODO list
- Quato,每个group配额
- Storm on yarn
- 应用自定义Hook
- 权限管理
- logview
- classloader
- upgrade Netty to netty4
参考链接:
Github源码:https://github.com/alibaba/jstorm/
中文文档:https://github.com/alibaba/jstorm/wiki/JStorm-Chinese-Documentation