https://blog.csdn.net/hustqb/article/details/78144384
t-sne数学原理https://zhuanlan.zhihu.com/p/57937096
什么是t-SNE?
t-SNE的主要用途是可视化和探索高维数据。 它由Laurens van der Maatens和Geoffrey Hinton在JMLR第九卷(2008年)中开发并出版。 t-SNE的主要目标是将多维数据集转换为低维数据集。 相对于其他的降维算法,对于数据可视化而言t-SNE的效果最好。 如果我们将t-SNE应用于n维数据,它将智能地将n维数据映射到3d甚至2d数据,并且原始数据的相对相似性非常好。与PCA一样,t-SNE不是线性降维技术,它遵循非线性,这是它可以捕获高维数据的复杂流形结构的主要原因。
t-SNE工作原理
首先,它将通过选择一个随机数据点并计算与其他数据点(|xᵢ—xⱼ|)的欧几里得距离来创建概率分布。 从所选数据点附近的数据点将获得更多的相似度值,而距离与所选数据点较远的数据点将获得较少的相似度值。 使用相似度值,它将为每个数据点创建相似度矩阵(S1)。
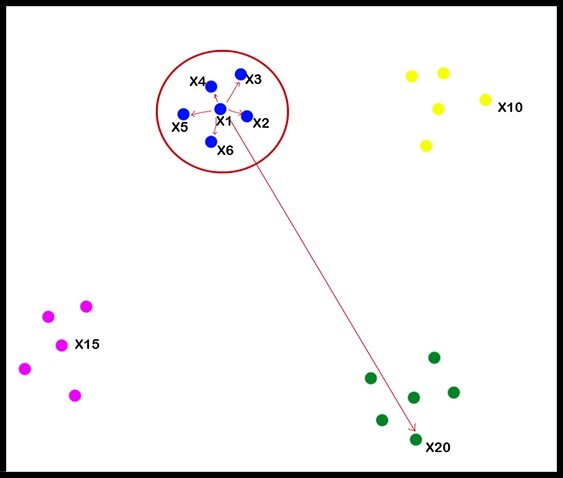
因为不可能将超过3维的数据集可视化,所以为了举例的目的,我们假设上面的图是多维数据的可视化表示。
这里需要说明的是:相邻指的是与每个点最接近的点的集合。
由上图可知,我们可以说X1的邻域 N(X1)= {X2, X3, X4, X5, X6},这意味着X2,X3,X4,X5和X6是X1的邻居。 它将在相似度矩阵“ S1”中获得更高的价值。 这是通过计算与其他数据点的欧几里得距离来计算的。
另一方面,X20远离X1。 这样它将在S1中获得较低的值。
其次,它将根据正态分布将计算出的相似距离转换为联合概率。
通过以上的计算,t-SNE将所有数据点随机排列在所需的较低维度上。

t-SNE将再次对高维数据点和随机排列的低维数据点进行所有相同的计算。 但是在这一步中,它根据t分布分配概率。 这就是名称t-SNE的原因。
t-SNE中使用t分布的目的是减少拥挤问题(后面与PCA对比可见)。
但是请记住,对于高维数据,该算法根据正态分布分配概率。
t分布→视觉上t分布看起来很像正态分布,但尾部通常更胖,这意味着数据的可变性更高。
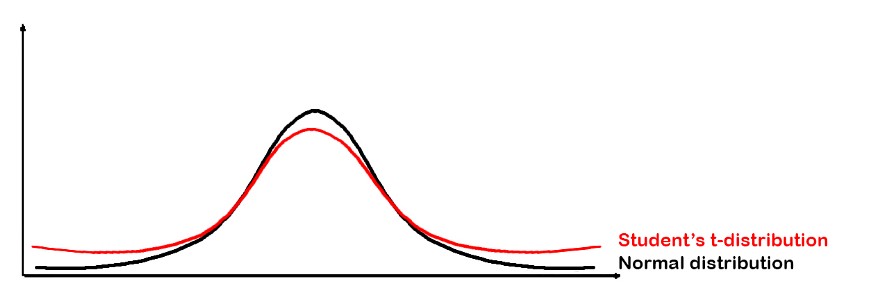
对于较低维的数据点,还将创建一个相似度矩阵(S2)。然后该算法将S1与S2进行比较,并通过处理一些复杂的数学运算来使S1与S2之间有所不同。包括使用两个分布之间的Kullback Leibler散度(KL散度)作为损失函数运行梯度下降算法。使用KL散度通过将两个分布之间相对于数据点位置的值最小化,帮助t-SNE保留数据的局部结构。
在统计学中,Kullback-Leibler散度是对一个概率分布与另一个概率分布如何不同的度量。梯度下降算法是各种机器学习算法中用于最小化损失函数的一种优化算法。
最后,该算法能够得到与原始高维数据相对相似度较好的低维数据点。我们可以使用sklearn.manifold.TSNE()实现t-SNE算法
要点
- t-SNE算法具有扩展密集簇并缩小稀疏簇的特点。
- t-SNE不会保留群集之间的距离。
- t-SNE是一种不确定性算法或随机算法,这就是为什么每次运行结果都会略有变化的原因。
- 即使它不能在每次运行中保留方差,也可以使用超参数调整来保留每个类之间的距离。
- 该算法涉及许多计算和计算。 因此,该算法需要大量时间和空间来计算。
- 困惑度(perplexity)是控制数据点是否适合算法的主要参数。 推荐范围是(5–50)。
- 困惑度应始终小于数据点的数量。
- 低困惑度→关心本地结构,并关注最接近的数据点。
- 高度困惑→关心全局结构。
- t-SNE可以巧妙地处理异常值。
TSNE的参数
函数参数表:
| parameters | 描述 |
|---|---|
| n_components | 嵌入空间的维度 |
| perpexity | 混乱度,表示t-SNE优化过程中考虑邻近点的多少,默认为30,建议取值在5到50之间 |
| early_exaggeration | 表示嵌入空间簇间距的大小,默认为12,该值越大,可视化后的簇间距越大 |
| learning_rate | 学习率,表示梯度下降的快慢,默认为200,建议取值在10到1000之间 |
| n_iter | 迭代次数,默认为1000,自定义设置时应保证大于250 |
| min_grad_norm | 如果梯度小于该值,则停止优化。默认为1e-7 |
| metric | 表示向量间距离度量的方式,默认是欧氏距离。如果是precomputed,则输入X是计算好的距离矩阵。也可以是自定义的距离度量函数。 |
| init | 初始化,默认为random。取值为random为随机初始化,取值为pca为利用PCA进行初始化(常用),取值为numpy数组时必须shape=(n_samples, n_components) |
| verbose | 是否打印优化信息,取值0或1,默认为0=>不打印信息。打印的信息为:近邻点数量、耗时、σσ、KL散度、误差等 |
| random_state | 随机数种子,整数或RandomState对象 |
| method | 两种优化方法:barnets_hut和exact。第一种耗时O(NlogN),第二种耗时O(N^2)但是误差小,同时第二种方法不能用于百万级样本 |
| angle | 当method=barnets_hut时,该参数有用,用于均衡效率与误差,默认值为0.5,该值越大,效率越高&误差越大,否则反之。当该值在0.2-0.8之间时,无变化。 |
返回对象的属性表:
| Atrtributes | 描述 |
|---|---|
| embedding_ | 嵌入后的向量 |
| kl_divergence_ | KL散度 |
| n_iter_ | 迭代的轮数 |
t-distributed Stochastic Neighbor Embedding(t-SNE)
t-SNE可降样本点间的相似度关系转化为概率:在原空间(高维空间)中转化为基于高斯分布的概率;在嵌入空间(二维空间)中转化为基于t分布的概率。这使得t-SNE不仅可以关注局部(SNE只关注相邻点之间的相似度映射而忽略了全局之间的相似度映射,使得可视化后的边界不明显),还关注全局,使可视化效果更好(簇内不会过于集中,簇间边界明显)。
目标函数:原空间与嵌入空间样本分布之间的KL散度。
优化算法:梯度下降。
注意问题:KL散度作目标函数是非凸的,故可能需要多次初始化以防止陷入局部次优解。
t-SNE的缺点:
- 计算量大,耗时间是PCA的百倍,内存占用大。
- 专用于可视化,即嵌入空间只能是2维或3维。
- 需要尝试不同的初始化点,以防止局部次优解的影响。
t-SNE的优化
在优化t-SNE方面,有很多技巧。下面5个参数会影响t-SNE的可视化效果:
- perplexity 混乱度。混乱度越高,t-SNE将考虑越多的邻近点,更关注全局。因此,对于大数据应该使用较高混乱度,较高混乱度也可以帮助t-SNE拜托噪声的影响。相对而言,该参数对可视化效果影响不大。
- early exaggeration factor 该值表示你期望的簇间距大小,如果太大的话(大于实际簇的间距),将导致目标函数无法收敛。相对而言,该参数对可视化效果影响较小,默认就行。
- learning rate 学习率。关键参数,根据具体问题调节。
- maximum number of iterations 迭代次数。迭代次数不能太低,建议1000以上。
- angle (not used in exact method) 角度。相对而言,该参数对效果影响不大。
PS:一个形象展示t-SNE优化技巧的网站How to Use t-SNE Effectively.
简单实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn import manifold, datasetsdigits = datasets.load_digits(n_class=6)
X, y = digits.data, digits.target
n_samples, n_features = X.shape'''显示原始数据'''
n = 20 # 每行20个数字,每列20个数字
img = np.zeros((10 * n, 10 * n))
for i in range(n):ix = 10 * i + 1for j in range(n):iy = 10 * j + 1img[ix:ix + 8, iy:iy + 8] = X[i * n + j].reshape((8, 8))
plt.figure(figsize=(8, 8))
plt.imshow(img, cmap=plt.cm.binary)
plt.xticks([])
plt.yticks([])
plt.show()
'''t-SNE'''
tsne = manifold.TSNE(n_components=2, init='pca', random_state=501)
X_tsne = tsne.fit_transform(X)print("Org data dimension is {}. Embedded data dimension is {}".format(X.shape[-1], X_tsne.shape[-1]))'''嵌入空间可视化'''
x_min, x_max = X_tsne.min(0), X_tsne.max(0)
X_norm = (X_tsne - x_min) / (x_max - x_min) # 归一化
plt.figure(figsize=(8, 8))
for i in range(X_norm.shape[0]):plt.text(X_norm[i, 0], X_norm[i, 1], str(y[i]), color=plt.cm.Set1(y[i]), fontdict={'weight': 'bold', 'size': 9})
plt.xticks([])
plt.yticks([])
plt.show()