前言
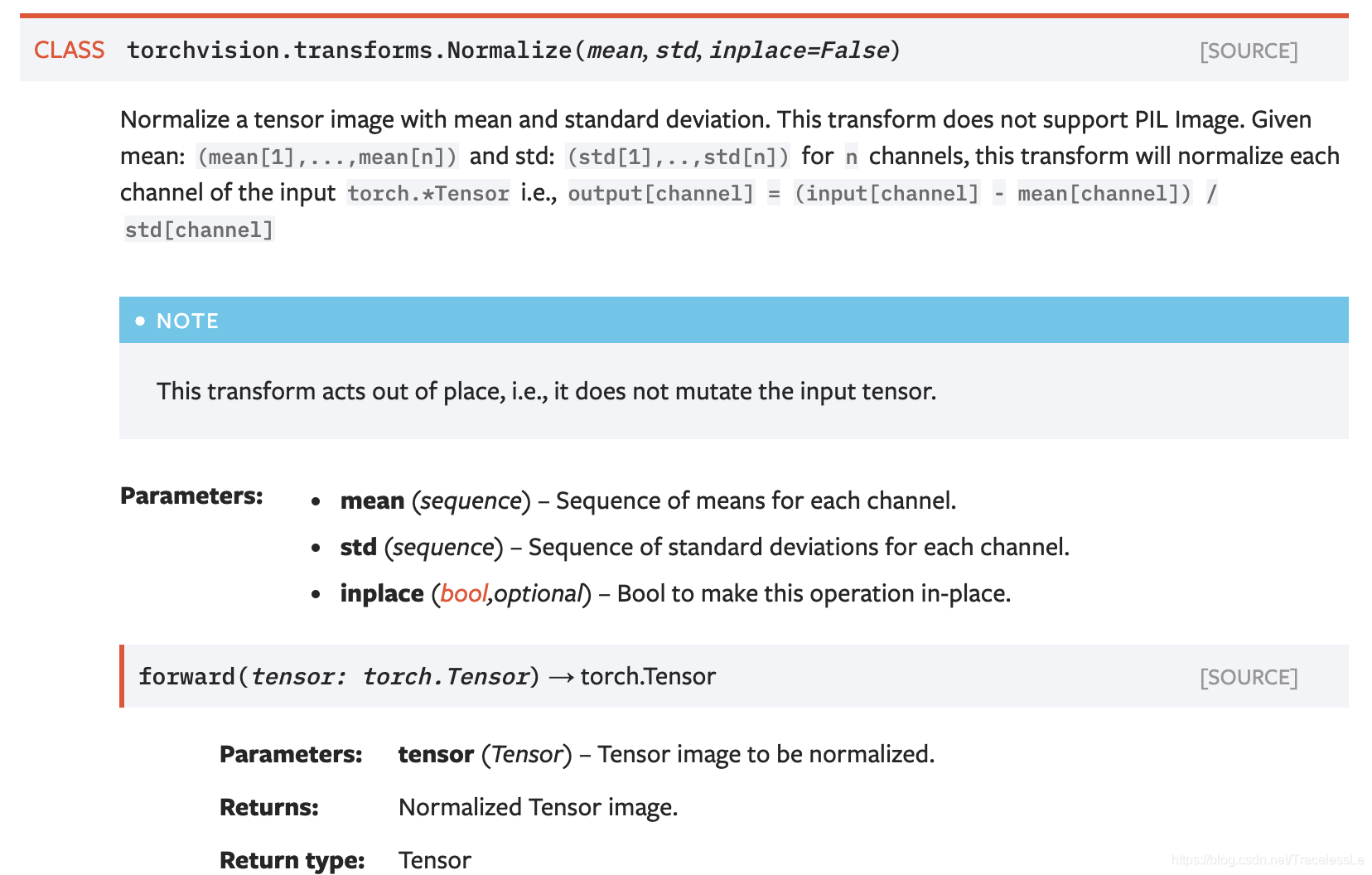
在使用深度学习框架构建训练数据时,通常需要数据归一化(Normalize),以利于网络的训练。而在训练过程可视化中,通常需要反归一化。以PyTorch框架而言,提供了torchvision.transforms.Normalize(mean, std, inplace=False)方法用于归一化。
归一化
归一化的实质是将数据的分布根据均值和标准差进行调整。
#torchvision.transforms.Normalize(mean, std, inplace=False)
output[channel] = (input[channel] - mean[channel]) / std[channel]
在实际应用过程中通常有三种方式:
(1)普通归一化
将经过ToTensor()方法(能够把范围从[0,255]变换到[0,1]之间)后的数据缩放到[-1, 1]之间。
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
(2)ImageNet先验归一化
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
该均值和标准差来源于ImageNet数据集统计得到,如果建立的数据集分布和ImageNet数据集数据分布类似(来自生活真实场景,例如人像、风景、交通工具等),或者使用PyTorch提供的预训练模型,推荐使用该参数归一化。如果建立的数据集并非是生活真实场景(如生物医学图像),则不推荐使用该参数。

(3)计算数据集的均值和标准差
对于特定的数据集,可以直接通过对训练集进行统计计算其均值和标准差。
反归一化
针对普通归一化方法的反归一化:
def denorm(x):out = (x + 1) / 2return out.clamp_(0, 1)
针对ImageNet先验归一化方法的反归一化:
class UnNormalize(object):def __init__(self, mean, std):self.mean = meanself.std = stddef __call__(self, tensor):"""Args:tensor (Tensor): Tensor image of size (C, H, W) to be normalized.Returns:Tensor: Normalized image."""for t, m, s in zip(tensor, self.mean, self.std):t.mul_(s).add_(m)# The normalize code -> t.sub_(m).div_(s)return tensorunorm = UnNormalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
unorm(tensor)

参考资料
[1] image processing[数据归一化]均值和方差设置
[2] torchvision.transforms.Normalize(mean, std, inplace=False)
[3] How to get these data(means = [0.485, 0.456, 0.406] stds = [0.229, 0.224, 0.225]) in your code? #6
[4] Why Pytorch officially use mean=[0.485, 0.456, 0.406] and std=[0.229, 0.224, 0.225] to normalize images?
[5] Simple way to inverse transform ? Normalization
[6] PyTorch函数之torchvision.transforms.ToTensor()和Normalize()
[7] pytorch 归一化与反归一化