问:特征衍生上千、万的变量,是怎么做的?
问:大家是如何衍生出成千上万个变量的?衍生变量是怎么生成的?
研习社-上海-桂浩:
请教一个问题,大家是如何衍生出成千上万个变量的?衍生变量是怎么生成的
云何-simple:
这是特征工程阶段所要做的事情
研习社-上海-桂浩:
基于时间的维度细分,组合一些基础变量等等
研习社-杭州-小五:
可以用sql,也可以用python,自己熟悉的就行啊
研习社-杭州-小五:
先自己写一个大概的衍生框架,然后根据框架写代码就好了
云何-simple:
需要衍生哪些特征 这个是重点
关键词
特征衍生、特征构建、合成特征、特征组合、自动化特征衍生
特征衍生
在实际业务中,通常我们只拥有几个到几十个不等的基础变量,而多数变量没有实际含义,不适合直接建模,如用户地址(多种属性值的分类变量)、用户日消费金额(弱数值变量)。而此类变量在做一定的变换或者组合后,往往具有较强的信息价值,对数据敏感性和机器学习实战经验能起到一定的帮助作用。所以我们需要对基础特征做一些衍生类的工作,也就是业内常说的如何生成万维数据。
特征衍生也叫特征构建,是指从原始数据中构建新的特征,也属于特征选择的一种手段。特征构建工作并不完全依赖于技术,它要求我们具备相关领域丰富的知识或者实践经验,基于业务,花时间去观察和分析原始数据,思考问题的潜在形式和数据结构,从原始数据中找出一些具有物理意义的特征。
找到可以拓展的基础特征后,便可用如下几种方式衍生特征:
- 特征扩展
- 合成特征
- 特征组合
- 特征交叉
乍一听,挺难懂,这都什么东西,有什么区别?其实这些概念基本都一个意思,就一些小细节会有不同。有笔者说:合成特征 (synthetic feature)和特征组合(Feature Crosses)不太一样,特征交叉是特征组合的一个子集。
我们今天,简单讲3个概念:
1.特征扩展
基于一个特征,使用特征值打平(扩展)的方式衍生多个标注类型的特征,也可以理解为离散化。对于分类变量,直接one-hot编码;对于数值型特征,离散化到几个固定的区间段,然后用one-hot编码。比如信贷场景逾期天数:
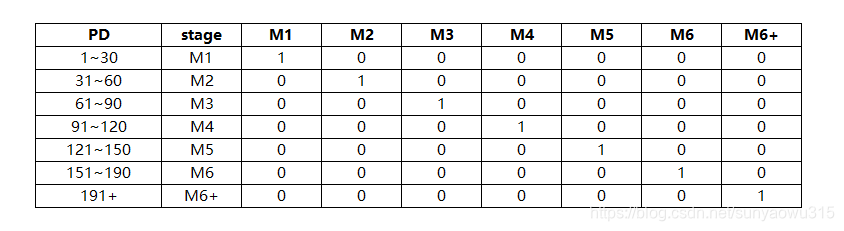
这里可以起到两个作用:①把线性函数转换成分段阶跃函数,减少过拟合。 ②标注 ,方便后续特征交叉组合
2.特征组合
指将两个或多个输入特征通过数学运算进行组合。分为如下几种情况:
- 数值运算
- 如对特征进行加,减,乘,除
- 特征交叉
- 对多个特征进行交叉组合,或做交,并,补,笛卡尔集等运算。(可参考后面案例)
- 暴力交叉,暴力交叉可能产生稀疏问题。
在实践中,扩展线性模型时辅以特征组合一直都是训练大规模数据集的有效方法,机器学习模型很少会组合连续特征。不过,机器学习模型却经常组合独热特征矢量,将独热特征矢量的特征组合视为逻辑连接。
3.合成特征
合成特征的思想很简单,通过将单独的特征进行组合(相乘或求笛卡尔积)而形成的合成特征。是一种让线性模型学习到非线性特征的方式:包括以下类型:
- 将一个特征与其本身或其他特征相乘(称为特征组合)。比如属性A有三个特征,属性B有两个特征,笛卡尔积后就有六个组合特征。
- 两个特征相除。
- 对连续特征进行分桶,以分为多个区间分箱。
说明: 通过标准化或缩放单独创建的特征不属于合成特征。
说明: 合成特征与组合特征关系在于:特征组合广义上包含合成特征,合成特征则改变了特征的线性关系,属于无中生有。
自动衍生
包括自动衍生和深度衍生的方法,可以缩减时间成本,构建维度更广更全面的新生特征。具体可以参考:Featuretools
实操案例
下面,我们基于用户特征扩展、特征组合等方法,对单个用户常见的运营商数据中的通话日志信息account_info,做一个特征衍生的案例。
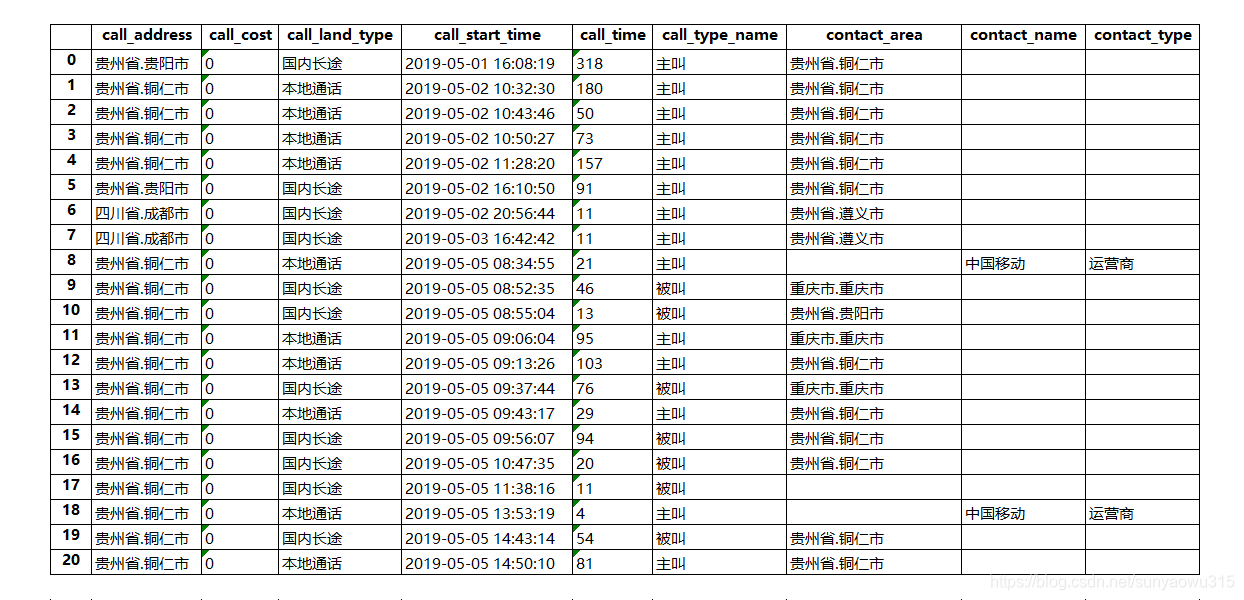
我们可以看到,用户通话信息宽表中的基础特征只有9个,而且在没做变换之前,多数特征不能直接使用。因此,我们用上述几种方法展开这个宽表。
#特征衍生1,更改字段含义,离散化特征,去除边缘数据的影响
tmp1['cutoff_date'] = self.cutoff_date
tmp1['call_time'] = tmp1['call_time'].map(lambda x : int(x))
tmp1['call_type_name'] = np.where(tmp1['call_type_name'] =='主叫','callout','callin')
tmp1['call_land_type'] = tmp1[['call_address','contact_area']].apply(lambda x : 'local' if x['call_address'] == x['contact_area'] else 'inland',axis = 1)
tmp1['call_time_type'] = tmp1['call_time'].map(lambda x : 'short' if int(x) <60 else 'midle' if int(x)<300 else 'long')
tmp1['contact_type'] = tmp1['contact_type'].fillna('')
tmp1['call_special'] = np.where(tmp1['contact_type'].str.contains('借贷'),'special','normal')
tmp1['call_period'] = tmp1['call_start_time'].apply(lambda x: 'night' if 0<int(pd.to_datetime(x).strftime("%H")) <5 else 'day')
可以看到,新增了call_land、call_type、call_time、call_period等字段(主被叫、本外地、时长、日夜间、特殊,行为习惯等判别依据 )
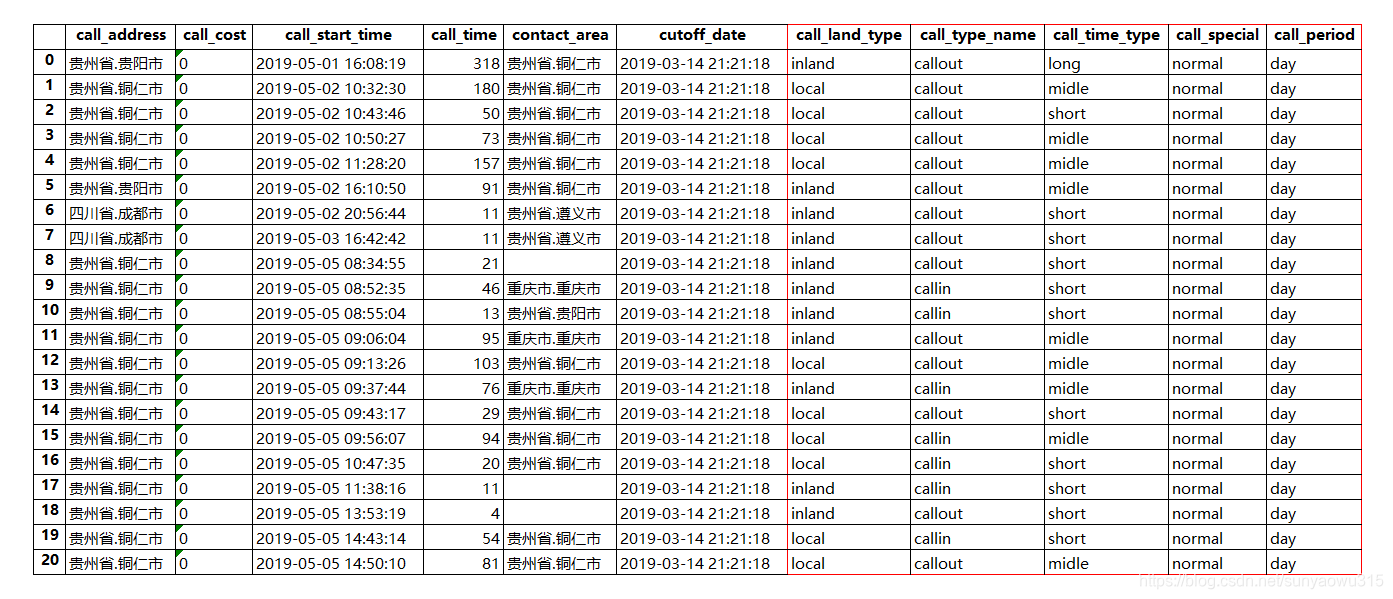
之后,基于时间序列,做稀疏编码
#特征衍生2,基于时间序列,做与cutofftime的稀疏编码,分别为:①距cutofftime的月份 ②距cutofftime 30,60,90,120,150,180 天内
tmp1['freq'],tmp1['dtot']=1,1
tmp1['diff_time'] =DT.calu_datediff2(indata=tmp1,date_1='cutoff_date',date_2='call_start_time')
tmp1 = DT.bin_date(indata=tmp1,binlist=[30*v for v in [1,3,6,12] ],var='diff_time',varname='d')
tmp1 = DT.bin_date2(indata=tmp1,binlist=[30,60,90,120,150,180],var='diff_time',varname='dt')
此时宽表的特征已经扩增到30+
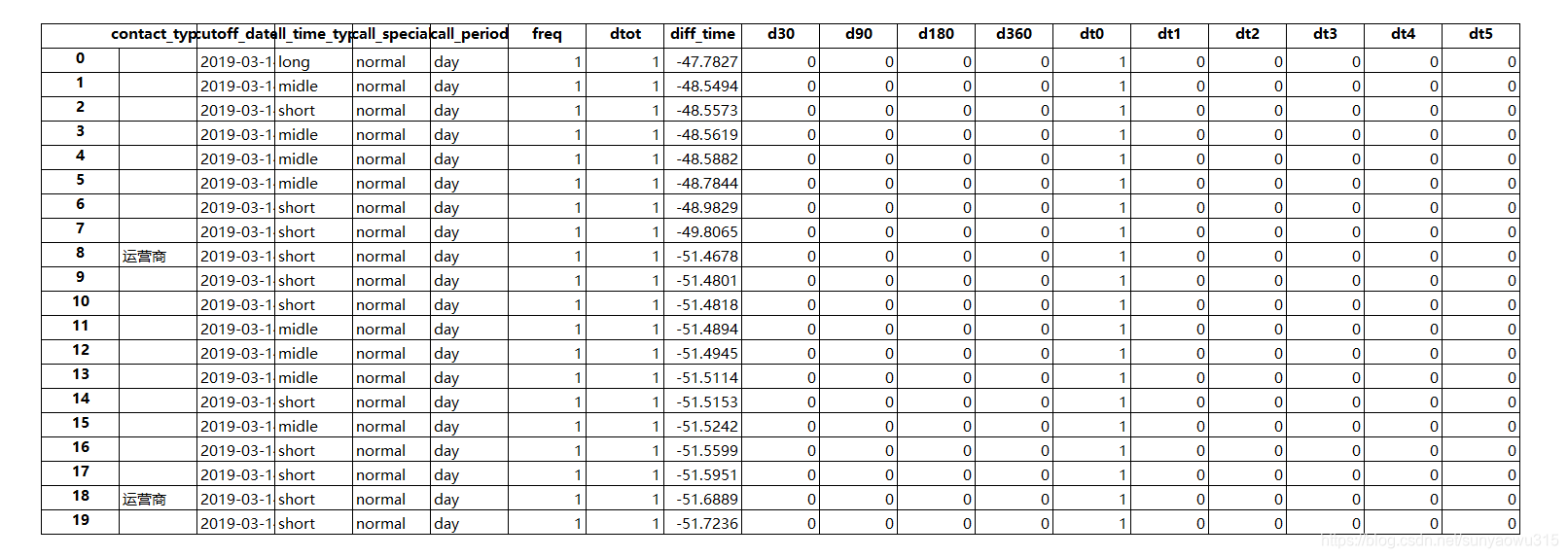
假设宽表的构建已基本完成,接下来就对该用户做基于时间序列和属性特征的交叉组合
def call_info_feature1(self,indata):#主叫、本地、时长、夜间、特殊情况变量衍生tmp1=indata.copy()prefix = 'CALL'grp_var1,grp_var21,grp_var22,grp_var23,grp_var24 = ['call_type_name'],['call_land_type'],['call_time_type'],['call_special'],['call_period']var_name_list = ['freq']func_list = [pd.Series.count]grp_dict_all = ['total']grp_dict1 = [list({'callout':'callout','callin':'callin'})]for i in grp_dict1:grp_dict1_all = grp_dict_all + i grp_dict21 = [list({'local':'local','inland':'inland','other':'other'})]for i in grp_dict21:grp_dict21_all = grp_dict_all + i grp_dict22 = [list({'short':'short','midle':'midle','long':'long'})]for i in grp_dict22:grp_dict22_all = grp_dict_all + i grp_dict23 = [list({'special':'special','normal':'normal'})]for i in grp_dict23:grp_dict23_all = grp_dict_all + i grp_dict24 = [list({'night':'night','day':'day'})]for i in grp_dict24:grp_dict24_all = grp_dict_all + i tmp_ds = pd.DataFrame()for i,j in zip([grp_var21,grp_var22,grp_var23,grp_var24],[grp_dict21_all,grp_dict22_all,grp_dict23_all,grp_dict24_all]):tmp_1 = DT.feature_derived1(indata = tmp1,prefix =prefix,grp_var1 = grp_var1,grp_var2 = i,var_name_list = var_name_list,func_list = func_list,grp_dict1_all = grp_dict1_all,grp_dict2_all = j).T # 主被叫、本地外地、长短时长tmp_ds = tmp_ds.append(tmp_1)tmp_ds = tmp_ds.T tmp_ds['idvar'] = self.idvarreturn tmp_ds# 特征衍生函数
def feature_derived1(self,indata,prefix,grp_var1,grp_var2,var_name_list,func_list,grp_dict1_all,grp_dict2_all):tmp_ds = indata.copy() flag_list = ['d30', 'd90','d180','d360','dtot']flag_series = ['dt0','dt1','dt2','dt3','dt4','dt5']col1=[f for f in flag_list+flag_series] if flag_series != []:col2 = ["b{num}_{fun}".format(num=num,fun=fun)for num in [3,6] for fun in ['max', 'avg','sum']]col3 = ['bm13_rate'] else:col2,col3 = [],[]for n,input_var in enumerate(var_name_list): for dt in flag_list+flag_series:tmp_ds[dt] = np.where(tmp_ds[dt]==1,tmp_ds[input_var],np.nan)tmp_ds['_total1_'] = 'total'tmp_1 = pd.DataFrame() for gv in grp_var1 + ['_total1_']:tmp_1 = tmp_1.append(tmp_ds.rename(columns={gv:'grp_var1'}),ignore_index=True)tmp_1['_total2_']='total'tmp_2=pd.DataFrame() for gv in grp_var2 + ['_total2_']:tmp_2=tmp_2.append(tmp_1.rename(columns={gv:'grp_var2'}),ignore_index=True)tmp_2=tmp_2.groupby(['grp_var1','grp_var2'])[[f for f in flag_list+flag_series]].agg(func_list).reset_index()for name in ['grp_var2','grp_var1']:if name not in tmp_2.columns:tmp_2[name]=np.nantmp_2=tmp_2[['grp_var2','grp_var1'] +[f for f in flag_list+flag_series]] tmp_2.columns=['grp_var2','grp_var1']+[f for f in flag_list+flag_series]if flag_series != []:for num in [3,6]:tmp_2['b{num}_max'.format(num=num)] =tmp_2[[f for f in flag_series][:num]].max(axis=1)tmp_2['b{num}_avg'.format(num=num)] =tmp_2[[f for f in flag_series][:num]].mean(axis=1)tmp_2['b{num}_sum'.format(num=num)] =tmp_2[[f for f in flag_series][:num]].sum(axis=1)tmp_2['bm13_rate'] =np.where( ((tmp_2[flag_series[1]] +tmp_2[flag_series[2]]).isnull()) | ((tmp_2[flag_series[1]] +tmp_2[flag_series[2]])==0),0,100*2*tmp_2[flag_series[0]] /(tmp_2[flag_series[1]] +tmp_2[flag_series[2]]))tmp_2=tmp_2[['grp_var2','grp_var1'] + col1+col2+col3]tmp_3=pd.DataFrame(pd.pivot_table(tmp_2,values=col1+col2+col3,columns=['grp_var1','grp_var2'])).Tcolumns_list = [(v1,v2,v3) for v3 in grp_dict2_all for v2 in grp_dict1_all for v1 in col1+col2+col3]for var_missing in [name for name in columns_list if name not in tmp_3.columns]:tmp_3[var_missing]=np.nantmp_3=tmp_3[columns_list]tmp_3.columns=[prefix+"_"+name[2]+"_"+name[1]+"_"+ name[0] for name in tmp_3.columns] return tmp_3运行,可以看到,衍生后,生成总计757个字段

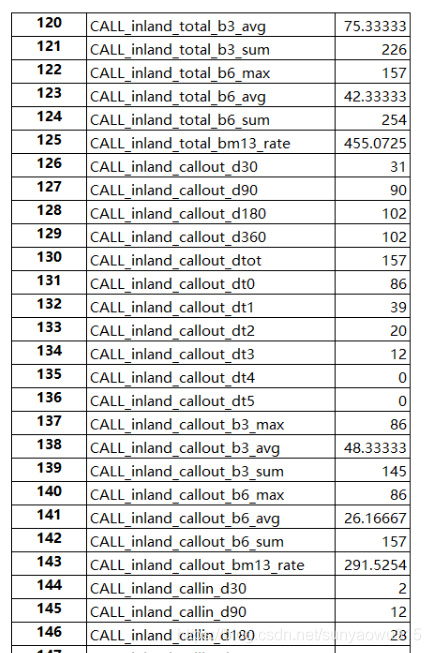
接下来,继续增加通讯录、联系人、短信、黑名单、标签等新的特征维度,用于交叉生成特征
tmp_2 = self.call_info_feature2(indata = tmp1) # 通话记录详单、与通讯录匹配情况,构建用户社交画像。判断通讯录真实性,判断通话真实性,统计频繁联系人表单,输入催收系统
tmp_3 = self.call_info_feature3(indata = tmp1) # 联系人contact_type命中标记:①警察②司法③贷款④催收等lable,识别账号社会风险。通过模糊匹配,精准匹配等异常标记进入本地名单库,识别本人风险
tmp_4 = self.call_info_feature4(indata = tmp1) # 紧急联系人、通讯录、联系人,运用复杂网络、社团识别等技术,通过手机号命中黑名单、异常号码库。识别一度联系人风险,判断本人欺诈性
依据经验,分析维度越多,衍生特征越多,这样,万维的数据就构建起来了。
如今,生产环境中遇到离散特征衍生时的处理方式主要有两种:
- ① 在做前期数据分析的时候,就将想要扩展和组合的数据提前处理好。
- 优点:经验充分,扩展后的数据往往有较好的效果;
- 缺点:人工处理,而且基本是写死成数据的,后期模型训练中不易调整。
- ② 使用类似独热编码(One-Hot-Encoding)的方案,将特征值全量打开,实现特征的自动化扩展。
- 优点:省时省力
- 缺点:数据全量打开,以至过程和结果不可控,且可能存在无意义特征的爆炸导致不可计算或者计算效率低等。
因此,我们提出一种较为合适的方法:将要处理的离散特征的特征值情况进行展现,然后基于其实际情况进行有选择可控制的特征自动化扩展和组合。
方法如下:
- 遍历产生离散特征值(自动)
- 计算特征离散程度和各属性值占比,排序选择需要扩展的特征。(自动+手动)
- 基于选择、处理后的特征值,扩展特征(自动)
- 基于选择、处理后的特征值,组合特征(自动)
- 特征量化
- 特征规范化
【参考】
- 特征工程之自动特征生成(自动特征衍生)工具Featuretools介绍 汀桦坞 https://blog.csdn.net/wiborgite/article/details/88761330
- 机器学习之特征组合、特征交叉 作者:Madazy 原文:https://blog.csdn.net/Madazy/article/details/84110400
- 特征组合之DeepFM 作者:Madazy 原文:https://blog.csdn.net/Madazy/article/details/84337609
- 特征组合之FFM 作者:Madazy 原文:https://blog.csdn.net/Madazy/article/details/84316840
- 利用GBDT模型构造新特征 作者:Bryan__ 原文:https://blog.csdn.net/bryan__/article/details/51769118
- FM及FFM算法 作者:陈玓玏 https://blog.csdn.net/weixin_39750084/article/details/83549027
- 特征选择与特征组合 北冥有小鱼 https://blog.csdn.net/qq_26598445/article/details/80998760
- 特征组合&特征交叉 (Feature Crosses) kugua233 https://segmentfault.com/a/1190000014799038
- 机器学习之离散特征自动化扩展与组合 DemonHunter211 https://blog.csdn.net/kwame211/article/details/78109254
- 自动特征工程 - AI科技大本营- https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/82392735
- 深度特征合成:实现数据科学自动化 forever_24 https://blog.csdn.net/u014686462/article/details/84063667
- 研习社-涛哥
对数据分析、机器学习、数据科学、金融风控等感兴趣的小伙伴,需要数据集、代码、行业报告等各类学习资料,可添加微信:wu805686220(记得要备注喔!),也可关注微信公众号:风控圏子(别打错字,是圏子,不是圈子,算了直接复制吧!)

关注公众号后,可联系圈子助手加入如下社群:
- 机器学习风控讨论群(微信群)
- 反欺诈讨论群(微信群)
- python学习交流群(微信群)
- 研习社资料(qq群:102755159)(干货、资料、项目、代码、报告、课件)
相互学习,共同成长。