Java内存模型
- 1.内存模型概念图
- 2.线程共享区
- 方法区
- 常量池
- 运行时常量池
- 全局字符串池
- class文件常量池
- 堆空间
- 3.线程独占区
- 虚拟机栈
- 本地方法栈
- 程序计数器
- 4.对象的创建
1.内存模型概念图

2.线程共享区
方法区
方法区也是线程共享区用于储存虚拟机加载的类信息(类的版本、字段、方法、接口),常量,静态变量,即时编译后的代码等数据
方法区逻辑上属于堆的一部分,但是与堆进行了区分,通常又叫非堆
HotSpot虚拟机使用永久代来实现方法区,使得HotSpot虚拟机的垃圾收集器可以像管理内存一样管理这部分内存,能省去专门为方法区专门为方法区编写内存管理代码工作,所有开发者喜欢将方法区称为永久代本质两者并不等价对于其虚拟机来说不存在永久代的概念
方法区可以选择不实现垃圾收集,一般来说这个区域对于内存回收的条件比较苛刻,但是这部分区域的回收确实是必要的
当方法区无法满足内存分配需求时,将会抛出OutOfMemoryError异常
常量池
运行时常量池
1. 运行时常量池是方法区的一部分1 .1 Class文件除了有类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池,用于存放编译器生成的各种字面量和符号引用,这部分内容在类加载后加入方法区运行时常量池存放1. 2 运行时常量相当于class文件中的常量池有所不同的其具备了动态性,class文件中常量池中的常量在编译期间就定义好了,而运行时常量池在程序运行期间也可以将常量加入该常量中,最常见的方法就是调用string类的intern()方法
全局字符串池
全局字符串池的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后该字符串对象实例的引用存到String pool中(记住:String pool中存的时引用值而不是具体的实例对象、具体的实例对象是在堆中开辟了一块空间存放的。)在HotSpot VM里实现的String pool功能的是一个StringTable类,他是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等用被赋予了“驻留字符串”的身份。这个StringTable 在每个hotshot vm的实例只有一份,被所有类共享。
class文件常量池
我们都知道,class文件中除了包含类的版本、字段、方法、接口、等描述信息外、还有一项信息就是常量池(Constant pool table)用于存放编译器生成的各种字面量和符号引用,字面量就是我们所说的常量概念,如文本字符串、被声明为final的常量值等,符号引用时一组符号来描述所引用的目标,符号可以时任何形式的字面量只要使用时无歧义的定位到目标位置就行(它与直接引用区分一下,直接引用一般时指方法区的本地指针,相对偏移量或时一个能简介定位搭配目标的句柄)一般包括三类常量
类和接口的全限定名
字段的名称和描述符
方法的名称和描述符
举个实例来说明一下:
String str1 = "abc"; String str2 = new String("def"); String str3 = "abc"; String str4 = str2.intern(); String str5 = "def"; System.out.println(str1 == str3);//true System.out.println(str2 == str4);//false System.out.println(str4 == str5);//true
1 2 3 4 5 6 7 8
上面程序的首先经过编译之后,在1.该类的class常量池中存放一些符号引用,2.然后类加载之后,将class常量池中存放的符号引用转存到运行时常量池中,3.然后经过验证,准备阶段之后,在堆中生成驻留字符串的实例对象(也就是上例中str1所指向的”abc”实例对象),4.然后将这个对象的引用存到全局String Pool中,也就是StringTable中,5.最后在解析阶段,要把运行时常量池中的符号引用替换成直接引用,那么就直接查询StringTable,保证StringTable里的引用值与运行时常量池中的引用值一致,大概整个过程就是这样了。(先存放类的符号引用(类名 描述符等)之类的东西然后类加载之后把这些东西存放在运行时常量池 然后在堆中生成实例 然后把对象的引用值存在字符串常量池中 然后解析阶段把,要把运行时常量池中的符号引用替换成直接引用)回到上面的那个程序,现在就很容易解释整个程序的内存分配过程了,首先,在堆中会有一个”abc”实例,全局StringTable中存放着”abc”的一个引用值,然后在运行第二句的时候会生成两个实例,一个是”def”的实例对象,并且StringTable中存储一个”def”的引用值,还有一个是new出来的一个”def”的实例对象,与上面那个是不同的实例,当在解析str3的时候查找StringTable,里面有”abc”的全局驻留字符串引用,所以str3的引用地址与之前的那个已存在的相同,str4是在运行的时候调用intern()函数,返回StringTable中”def”的引用值,如果没有就将str2的引用值添加进去,在这里,StringTable中已经有了”def”的引用值了,所以返回上面在new str2的时候添加到StringTable中的 “def”引用值,最后str5在解析的时候就也是指向存在于StringTable中的”def”的引用值,那么这样一分析之后,下面三个打印的值就容易理解了。
堆空间
JVM管理的最大以快内存区域,存放着内存实例是线程共享区
堆是垃圾收集器管理的主要区域,因此称为GC堆
JAVA堆的分类
3.1 从内存的回收的角度上看,可以分为新生代(Eden空间,From Survivor 空间, To Survivor空间)及老年代(Tenured Gen)
3.2 从内存分配的角度上看,为了解决分配内存的线程安全性问题,线程共享的JAVA堆中可能划分楚多个线程私有的分配缓冲区(TLAB)
JAVA堆可以处于物理上不连续的内存空间中,只要逻辑上连续即可。
可以通过参数Xms-Xms 来指定运行时堆内存的大小 堆内存空间不足也会抛OutOfMemoryError异常。
3.线程独占区
虚拟机栈
每个线程都有一个私有的栈,随者线程的创建而创建,生命周期与线程相同
虚拟机栈里面存着一种叫做“栈帧”的东西,每个方法都会创建一个栈帧,栈帧中存放了局部变量表,操作数栈、动态链接、方法出口等信息
2.1 局部变量表存放了编译期可知的各种基本数据类型和对象引用类型,通常我们所说的栈内存指的就是局部变量表这一部分

2.2 64位的long和double类型的数据会占用2各局部变量的空间,其余的数据类型只占用1个
2.3局部变量表所需的内存空间在编译器完成分配,当进入一个方法时,这个方法需要在帧分配多少内存是固定的,运行的期间不会改变局部变量表的大小
方法的调用到执行完毕,对应的就是栈帧的入栈和出栈的过程
栈的大小可以固定也可以动态扩展
4.1固定大小的情况下,当栈调用深度大于jvm所允许的范围,会抛出StackOverFlowError异常
4.2在动态扩展的情况下,若扩展时无法申请到足够的内存,会抛出OutOfMemoryError
5.栈内存溢出模拟
public class MainTest {public static void main(String[] args){new MainTest().test();}private void test() {System.out.println("run...");test();}}
报错如下
Exception in thread "main" java.lang.StackOverflowErrorat sun.nio.cs.UTF_8$Encoder.encodeLoop(UTF_8.java:691)at java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:579)
图例:

本地方法栈
1.和虚拟机栈类似,两者的区别就是虚拟机栈为虚拟机执行java方法服务,本地方法为虚拟机执行native方法服务
2.hotShot虚拟机不区分虚拟机栈和本地方法栈,两者是一块
3.与虚拟机栈一样,已本地方法栈也会抛出StackOverflowError和OutOfMemoryEorr异常
程序计数器
1.程序计数器是一块较小的空间,他可以看作当前线程所执行的字节码的行号指示器

2.如果线程执行的是java方法,这个计数器记录的是正在执行虚拟机字节码指令的地址(可以理解为上图所示的行号),如果正在执行的是native(本地方法:操作系统的方法)这个计数器的值为under fined
3.JVM的多线程是通过线程轮流切换并分配CPU执行时间片的方式来实现的,任何一个时刻,一个CPU只会执行一条线程中的指令。为了保证线程切换后能恢复到正常的执行位置,每条线程都需要有一个独立的程序计数器,各线程中独立储存,互不影响。
4.此区域是唯一一个再java虚拟机规范中没有规定任何OutOfMemoryError情况的区域,因为程序计数器是由虚拟机内部维护的,不需要开发者进行操作
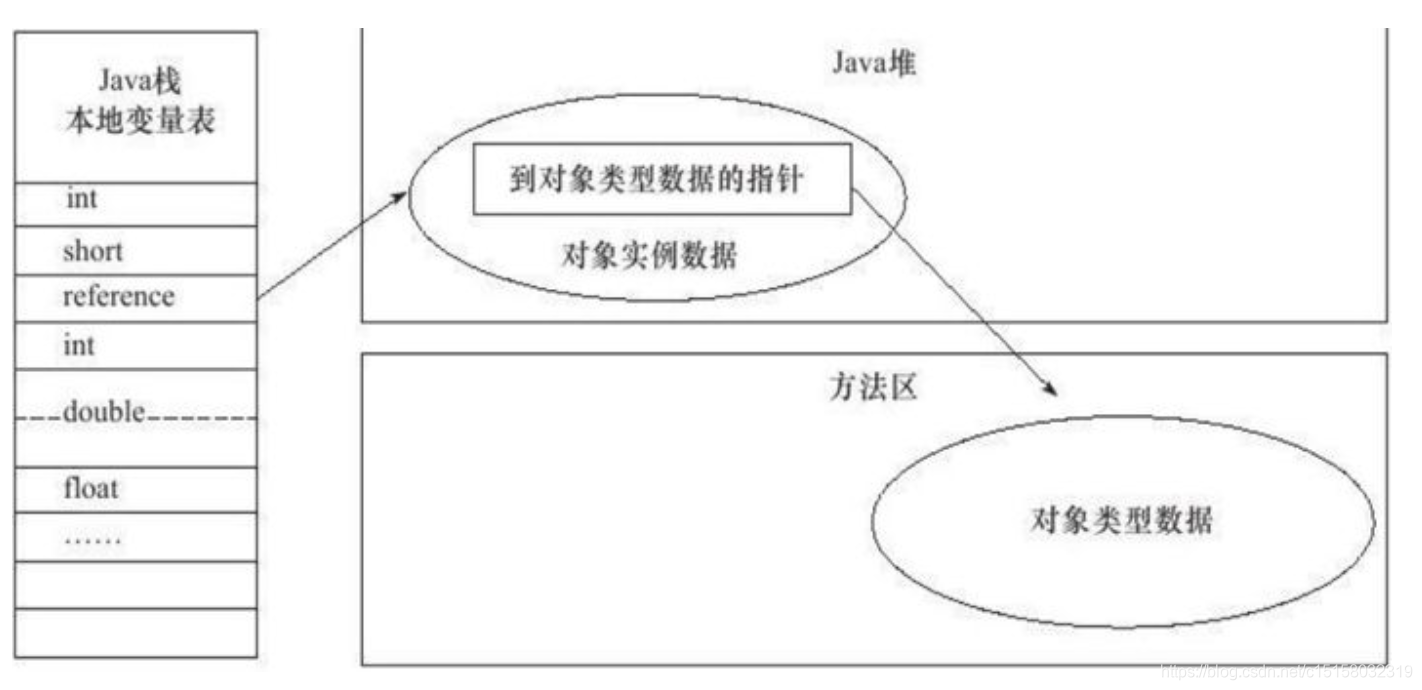
4.对象的创建












![ADF单位根检验三种形式_[STATA] 时间序列模型 ARIMA检验](https://img-blog.csdnimg.cn/img_convert/574bfbb99b5f73992c2771db174239f2.png)
