熵编码原理
- 一.熵编码原理
- 1.原理介绍
- 2.常见方案
- 3.整数位元法
- 4.熵编码模型
- 二.熵编码CABAC介绍
- 1.二进制化
- 2.上下文建模
- 3.二进制算术编码
- 常规编码
- 区间重归一化
- 旁路编码
一.熵编码原理
1.原理介绍
熵编码即编码过程中按熵原理不丢失任何信息的编码。信息熵为信源的平均信息量(不确定性的度量)。常见的熵编码有:1.香农(Shannon)编码、2.哈夫曼(Huffman)编码 3.算术编码(arithmetic coding)** **4.行程编码 (RLE) 5.基于上下文的自适应变长编码(CAVLC) 6.基于上下文的自适应二进制算术编码(CABAC)。
研究背景
数据压缩技术的理论基础就是信息论。信息论中的信源编码理论解决的主要问题:
(1)数据压缩的理论极限;
(2)数据压缩的基本途径。
根据信息论的原理,可以找到最佳数据压缩编码的方法,数据压缩的理论极限是信息熵。如果要求编码过程中不丢失信息量,即要求保存信息熵,这种信息保持编码叫熵编码,是根据消息出现概率的分布特性而进行的,是无损数据压缩编码。 [1]
2.常见方案
常见的熵编码有:香农(Shannon)编码、哈夫曼(Huffman)编码和算术编码(arithmetic coding)。在视频编码中,熵编码把一系列用来表示视频序列的元素符号转变为一个用来传输或是存储的压缩码流。输入的符号可能包括量化后的变换系数,运动向量,头信息(宏块头,图象头,序列的头等)以及附加信息(对于正确解码来说重要的标记位信息)。
熵编码一个很重要的应用领域就是图像压缩。
下面是JPEG的编码流程。蓝色框中的编码就是用了熵编码
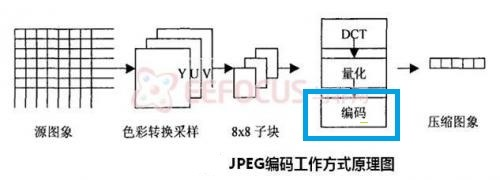
至于其他的视频标准,如MPEG2,H264, H265,编码流程都是大同小异,过程无非都是采样-DCT-量化-编码。
它们都会用到熵编码,例如JPEG用的是Huffman编码和算术编码,H264用的是CAVLC和CABAC。
3.整数位元法
编码方案
使用长度不同的比特串对字母进行编码有一定的困难。尤其是几乎所有几率的熵都是一个有理数。

熵编码流程
哈夫曼编码建议了一种将位元( bit)进位成整数的算法,但这个算法在特定情况下无法达到最佳的结果。为此有人加以改进,提供最佳整数位元数。这个算法使用二叉树来设立一个编码。这个二叉树的终端节点代表被编码的字母,根节点代表使用的位元。
除这个对每个要编码的数据产生一个特别的表格的方法外还有使用固定的编码表的方法。比如加入要编码的数据中符号出现的机率符合一定的规则的话就可以使用特别的变长编码表。这样的编码表具有一定的系数来使得它适应实际字母出现的机率。
改进
使用整数位元的方法往往无法获得使用熵计算的位元数,因此其压缩并非一定最佳。
比如字母列由两个不同的字母组成,其中一个字母的可能性是p(A) = 0.75,另一个字母的可能性是p(B) = 0.25。以上算法的结果是每个字母应该用一个位元来代表,因此其结果的位元数与字母数相同。
扩充功能取样位数可以稍微弥补该破绽:上例的p(AA) = 0.5625、p(AB) = 0.1875、p(BA) = 0.1875、p(BB) = 0.0625,以哈夫曼编码算法得结果为:每两个字母平均用(0.5625 * 1 + 0.1875 * 2 + 0.1875 * 3 + 0.0625 * 3) = 1.6875个位元,即平均每个字母用0.84375个位元来代表,向最佳熵值踏近了一步。
最佳熵编码器应该为第一个字母使用 − log2(0.75) ≈ 0.41个位元,为第二个字母使用 − log2(0.25) = 2个位元,因此整个结果是每个字母平均使用 − 0.75 * log2(0.75) - 0.25 * log2(0.25) ≈ 0.81个位元。
使用算术编码可以改善这个结果,使得原资讯按照熵最佳来编码。
4.熵编码模型
要确定每个字母的比特数算法需要尽可能精确地知道每个字母的出现机率。模型的任务是提供这个数据。模型的预言越好压缩的结果就越好。此外模型必须在压缩和恢复时提出同样的数据。在历史上有许多不同的模型。
静态模型
静态模型在压缩前对整个文字进行分析计算每个字母的机率。这个计算结果用于整个文字上。
优点:
编码表只需计算一次,因此编码速度高,除在解码时所需要的机率值外结果肯定不比原文长。
缺点:
计算的机率必须附加在编码后的文字上,这使得整个结果加长;
计算的机率是整个文字的机率,因此无法对部分地区的有序数列进行优化。 [3]
动态模型
在这个模型里机率随编码过程而不断变化。多种算法可以达到这个目的:
前向动态:机率按照已经被编码的字母来计算,每次一个字母被编码后它的机率就增高。
反向动态:在编码前计算每个字母在剩下的还未编码的部分的机率。随着编码的进行最后越来越多的字母不再出现,它们的机率成为0,而剩下的字母的机率升高,为它们编码的比特数降低。压缩率不断增高,以至于最后一个字母只需要0比特来编码。
优点:
模型按照不同部位的特殊性优化;
在前向模型中机率数据不需要输送。
缺点:
每个字母被处理后机率要重算,因此比较慢;
计算出来的机率与实际的机率不一样,在最坏状态下压缩的数据比实际原文还要长。
一般在动态模型中不使用机率,而使用每个字母出现的次数。除上述的前向和反向模型外还有其它的动态模型计算方法。比如在前向模型中可以不时减半出现过的字母的次数来降低一开始的字母的影响力。对于尚未出现过的字母的处理方法也有许多不同的手段:比如假设每个字母正好出现一次,这样所有的字母均可被编码。 [3]
模型度
模型度说明模型顾及历史上多少个字母。比如模型度0说明模型顾及整个原文。模型度1说明模型顾及原文中的上一个字母并不断改变其机率。模型度可以无限高,但是对于大的原文来说模型度越高其需要的计算内存也越多。
二.熵编码CABAC介绍
基于上下文的二进制算术编码(Context-Based Adaptive Binary Arithmetic Coding,CABAC)将自适应二进制算术编码和上下文模型相结合。是H.265/HEVC的主要熵编码方案。
主要包括三个步骤:
1.二进制化;
2.上下文建模;
3.二进制算术编码;
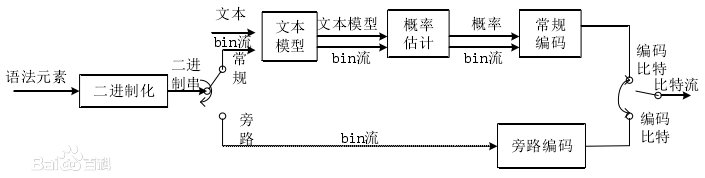
其流程如下:

1.二进制化
二进制化就是将输入的语法元素转化为二进制形式,如果语法元素以及是二进制形式则跳过该步骤。
H.265/HEVC中的二进制化方法有截断莱斯二元化(Truncated Rice binarization,TR),K阶指数哥伦布二元化(k-th order Exp-Golomb binarization,EGK)和定长二元化(Fixed-length binarization,FL)。K阶指数哥伦布编码前面已经介绍过。下面介绍TR和FL。
(1)截断莱斯二元化TR
设阈值为cMax,莱斯参数R,待二元化的语法元素为V。
截断莱斯码由前缀串和后缀串拼接成,前缀值P由下式计算得到:P = V >> R
则前缀串获取过程为:若P值小于(cMax >> R),则前缀串由P个1和一个0组成,长度为P+1;若P值大于等于(cMax >> R),则前缀串由(cMax >> R)个1组成,长度为(cMax >> R)。
当语法元素V小于cMax时,后缀值S为:S = V - (P << R)
后缀串为S的二元化串,长度为R。当语法元素V大于等于cMax时,无后缀串。
(2)定长二元化FL
当语法元素均匀分布时,可采用定长二元化。假设语法元素值为x,且x在[0,Max]间,则直接将x从十进制转为二进制得到二元化串。
2.上下文建模
一般情况下,不同语法元素间有一定相关性,且相同语法元素自身也具有一定记忆性。因此根据已编码元素进行条件编码可以提高编码性能。这些已编码元素就是当前待编码元素的上下文。
语法元素使用的上下文模型包括两个概率模型变量:最大概率符号MPS和概率状态索引pStateIdx。
MPS表示待编码的Bin最可能出现的符号,取值为1或0;与之对应,LPS为最小概率符号。在CABAC中,依据先验知识为LPS预设了64个概率值,如下表。

在对第一个二元位编码前需要对概率模型参数进行初始化。在H.265/HEVC中,为每个概率模型分配一个初始值V,通过V计算上下文模型初始变量MPS和pStateIdx。

HM中相关代码如下:
/**- initialize context model with respect to QP and initialization value.\param qp input QP value\param initValue 8 bit initialization value*/
Void ContextModel::init( Int qp, Int initValue )
{qp = Clip3(0, 51, qp);
Int slope = (initValue>>4)*5 - 45;Int offset = ((initValue&15)<<3)-16;Int initState = min( max( 1, ( ( ( slope * qp ) >> 4 ) + offset ) ), 126 );UInt mpState = (initState >= 64 );//!<m_ucState最后1位存放MPS值m_ucState = ( (mpState? (initState - 64):(63 - initState)) <<1) + mpState;
}
获得上下文模型初始参数后即可对输入二元符号进行二元算术编码和模型参数更新,实现上下文自适应的编码。概率模型在每个二元位编码后都要更新。
概率状态pStateIdx更新方法为:
若编码的二元符号值等于MPS,则通过查上面的表更新pStateIdx_new=transIdxMps(pStateIdx)
若编码的二元符号值等于LPS,如果pStateIdx为0则互换MPS和LPS,更新pStateIdx;否则不互换MPS和LPS,只更新pStateIdx;pStateIdx更新也是通过查表pStateIdx_new=transIdxLps(pStateIdx)
HM16中相关代码如下:
Void updateLPS (){m_ucState = m_aucNextStateLPS[ m_ucState ];}
Void updateMPS (){m_ucState = m_aucNextStateMPS[ m_ucState ];}
从概率模型更新过程可以看出:若当前编码Bin等于MPS,更新后的概率索引值变大,表示下一个符号是MPS的概率变大;若当前编码Bin等于LPS,更新后的概率索引值变小,表示下一个符号是LPS的概率变大;当概率索引值pStateIdx为0时,表示MPS和LPS的概率相同,若再出现LPS符号则MPS和LPS需要交换。
3.二进制算术编码
二进制算术编码也是算术编码的一种,只不过算术编码过程中的区间和编码输出等都用二进制表示。当前语法元素完成二进制化后,对每个Bin根据其概率模型进行二进制算术编码。二进制算术编码是基于递归区间划分方式,在递归过程中保存编码区间的长度和区间下限。包括两种编码方式:常规编码和旁路编码。常规编码利用自适应的概率模型进行编码。旁路编码以等概率方式进行,概率状态无需更新。
常规编码
编码器输入是上下文模型变量和待编码Bin,编码器的状态是当前编码区间长度ivlCurrRange和区间下限ivlLow。
编码流程如下:

算术编码首先需要估计每个符号概率然后进行区间划分。在CABAC中总是估计LPS的概率(P_lps<0.5),且LPS的概率通过64个离散值表示可以通过查表得到概率索引pStateIdx(见上一节)。
区间划分通常需要多位乘法运算(区间长度x概率),CABAC为了降低其复杂度通过查表获得区间长度。
首先计算索引:qRangeIdx=(ivlCurrRange >> 6) & 3
通过查下表LPS对应的子区间长度为:ivlLpsRange = rangeTabLps[pStateIdx] [qRangeIdx]
则MPS的子区间长度为:ivlCurrRange = ivlCurrRange - ivlLpsRange
因为二进制编码只有两个符号0和1,所有区间总是被分为两个子区间,且MPS总是在左侧,LPS总是在右侧。

如果当前Bin等于MPS,则MPS的区间长度R_mps作为下一个符号编码的区间长度R,区间下限L不变;如果当前Bin等于LPS,则LPS的区间长度R_lps作为下一个符号编码的区间长度R,区间下限L变为L+R_mps;编码完一个Bin后根据该Bin值更新上下文模型。
区间重归一化
上面区间划分后得到的新区间长度可能不在[256,512]间(HM中区间长度初始化为510),这就需要进行重归一化。


当区间长度小于256时就需要进行重归一化。
设归一化时用区间[0,102)表示[0,1);
1、当R<256&L<256时,区间落在[0,512)间,即[0,0.5)间(0.5二进制表示为0.1)。此时输出0(PutBit(0)),因为此区间内的数都是0.0x(二进制)。
2、当R<256&L>=512时,区间落在[512,1024)间,即[0.5,1)间。此时输出1(PutBit(1)),因为此区间内的数都是0.1x(二进制)。
3、当R<256&L<512时,区间落在[0,512)间或同时跨越[0,512)和[512,1024)。此时既可能是0.01x也可能是0.10x。暂缓输出,保存这个比特进入下一个重归一化循环。
4、当R>=256时,无法判断编码区间,需要通过输入下一个符号对R和L进行更新后继续判断,因此当前符号编码流程结束。由于这个原因,因此在一个符号编码结束后,另一个符号编码开始前,总是256<=R<512。

PutBit(B)用来输出编码符号0或1,从重归一化可以看出:
1、当满足条件1时执行PutBit(0),输出0;
2、当满足条件2时执行PutBit(1),输出1;
3、当满足条件3时,输出可能为“10”或者“01”,因此不能直接输出,走bitsOutstanding++的步骤。在下一次编码符号时,符合情况2,走PutBit(1),此时bitsOutstanding = 1,因此输出“10”。符合情况1,走PutBit(0),此时bitsOutstanding = 1,因此输出“01”;
另外,PutBit(B)不会编码第一个bit。原因是CABAC在初始化的时候,会以[0,1024)表示区间[0,1),而在初始化区间时R=510,L=0,这意味着已经进行了第一次区间选择,区间为[0,0.5),需要输出“0”。PutBit(B)在此阻止这个“0”的输出,这样就能得到正确的算术编码结果了。
WriteBits( B, N ) 表示将值B以N比特写入码流,然后将码流指针往前移动N个位置。
旁路编码
旁路编码不需要对概率模型进行更新,而是采用0和1概率各1/2的方式进行编码。当bypassFlag标志位为1时采用旁路编码。为了使区间划分更加简单,不采用直接对区间长度二等分的方法,而是采用保持编码区间长度不变使区间下限L加倍的方法实现区间划分。随后进行重归一化操作。旁路编码流程如下:

参考来源:
1.熵编码
2. 熵编码解答
3. CSDN博主 Dillon2015
4. CABAC
5. 新一代高效视频编码H.265HEVC原理、标准与实现