Python 爬虫笔记
- HTTP协议
- requests模块
- get() 和post()函数
- headers
- 数据解析
- 正则表达式
- bs4解析-HTML语法
- Xpath
- 批量爬取百度图片
- selenium
毕设与图像分类相关,所以需要大量的图片数据,所以先学学爬虫爬图片。
本文作为自学笔记,仅供参考
声明:本文所有爬取的内容,都是合法的公开内容,不涉及侵权,且不做商用,仅用于个人学习使用。
学习课程:B站路飞学城IT
爬虫:
简单来说就是利用程序获取互联网上的资源。
robots.txt协议 :规定网站中哪些数据不可以爬取, 只是协议,但并不能防止恶意爬取
爬虫的一般步骤:
- 拿到页面源代码
- 解析该源代码,拿到数据
在学习爬虫之前,要先了解一下HTTP协议。
HTTP协议
HTTP协议是万维网的通信基础。简单来说就是计算机访问网页所需遵守的规则。
接下来是计算机网络的基础知识。
HTTP有两种报文,请求报文和响应报文。
请求报文:
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。

响应报文:
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文

请求头中最常见的一些重要内容:
- User-Agent:请求载体的身份标识(用什么发送的请求)
- Referer:防盗链(这次请求是从哪个页面来的? 反爬会用到)
- cookie:本地字符串数据信息(用户登录信息, 反爬的token)
响应头中一些重要的内容:
- cookie
- 各种神奇的莫名其妙的字符串(一般都是token)
请求方式:
GET:显式提交
POST:隐式提交
接下来我们就要使用get 和 post方式去爬取一些网页。如果你没有学习过计算机网络,那么只需要先记住有这两种请求方式即可。
requests模块
get() 和post()函数
主要使用requests.get() 函数 和 requests.post()函数来请求获取网页上的内容
使用get还是post根据要爬取的页面的请求方式选择
例如:北京新发地的菜价页面就是post

百度的就是get

requests.get()
传入的第一个参数是url,统一资源定位标识,简单来说即要爬取的网页地址。
# 最简单的get请求方式
url = "http://www.baidu.com"
requests.get(url)
增加url参数 参数名为:params , 字典形式
例如:

params参数中的内容将直接加在url后面。
requests.post()
post加url参数, 参数名为 data 字典形式
有些网页的中的内容并不会直接出现在源代码页面中, 而是动态加载, 此时我们就需要抓包,然后查看其请求参数,并使用该参数请求页面。
例如:北京新发地

我们检查一下该源代码

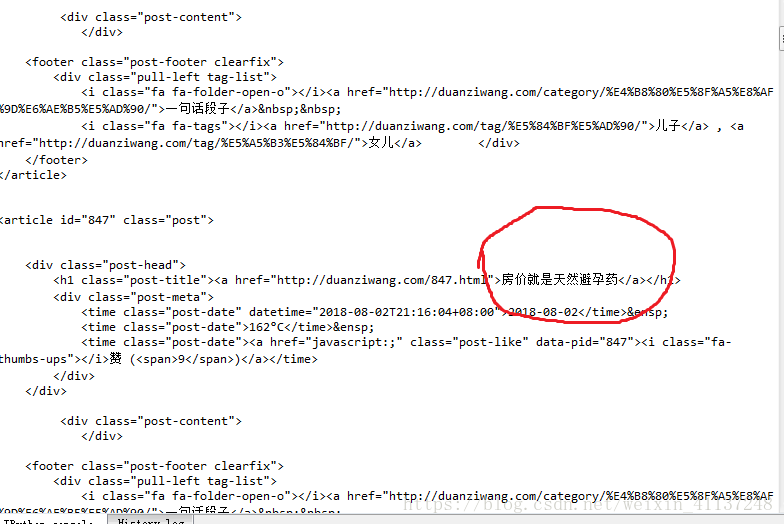
可以看出在源代码中并不存在菜价相关的信息,此时进行抓包
在XHR中可以看到存在一个getPriceData.html

点击预览并展开列表

可以发现菜价信息就在这个页面中
我们直接复制标头中的请求地址是只能打开第一页的菜价信息,那么我们如何获取第二页的菜价信息呢

在第二页抓包后会发现请求URL并没有改变, 但是其参数改变了

current 的值变为了2, 也就是说current的值就是代表第几页。
因次在使用post请求时,我们需要增加data参数,并将current参数添加进去。这样通过修改current的值,就可以获取所有页面的菜价信息。
import requestsurl = "http://www.xinfadi.com.cn/getPriceData.html"data = {"limit": 20,"current": 2
}
# 获取页面源代码
resp = requests.post(url, data=data)dic = resp.json() // 由于菜价信息是json格式,课直接保存为json格式
lst = dic["list"]
for it in lst:print(it["prodName"] + " " + it["avgPrice"] + "元/斤") //输出信息
headers
由于一些网站设置了一些简单的反爬机制,有时是我们需要在get或post函数中添加一个headers参数,headers是字典,其中只有一个键值对,就是"User-Agent":“xxxxxxxx”
User Agent中文名为用户代理,是Http协议中的一部分,属于头域的组成部分,User Agent也简称UA。它是一个特殊的字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。通过这个标 识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计;例如用手机访问谷歌和电脑访问是不一样的,这些是谷歌根据访问者的 UA来判断的。UA可以进行伪装。
一般来说,获取该网页的User-Agent就可以成功欺骗。
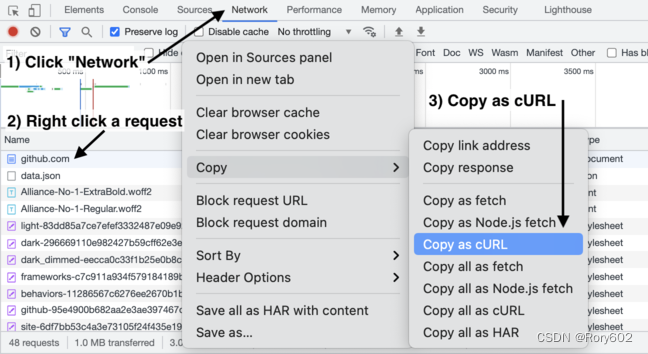
步骤:(以Edge浏览器为例)
- 打开你要爬虫的网页
- F12打开控制台
- 点击network(网络)
- F5刷新网页
- 点击列表中出现的第一个html文件
- 在请求标头中找到user-agent,复制其后的所有文字
- 将刚才复制的User-Agent字段构造成字典形式

实例:
爬取豆瓣排行榜
import requests# get 请求带参数
url = "https://movie.douban.com/j/chart/top_list"param = {"type": "24","interval_id": "100:90","action": "","start": 0,"limit": 20,
}headers = { // 基本的防止反爬"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62"
}resp = requests.get(url=url, params=param, headers=headers)print(resp.json())
resp.close()
爬取百度翻译
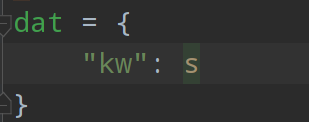
import requestsurl = 'https://fanyi.baidu.com/sug's = input()
dat = {"kw": s
}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62"
}
resp = requests.post(url, data=dat, headers=headers)print(resp.json())
resp.close()
数据解析
当使用get或post方式请求到页面源码之后,接下来就是对源码进行解析,然后拿到我们想要的数据。
数据解析常用的有3种方式:利用正则表达式,bs4,Xpath
正则表达式
元字符: 正则表达式的基本构成
. 匹配除换行符外的任意字符
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符^ 匹配字符串的开始
$ 匹配字符串的结尾大写即和小写相反
\W 匹配非字母或数字或下划线
\S 匹配非空白符
\D 匹配非数字
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符 [a-z] 表示匹配a-z的所有字符 [A-Z0-9]表示匹配A-Z和0-9的所有字符 [a-zA-Z0-9]同理
[^...] 匹配除了字符组中字符的所有字符
量词:控制前面的元字符出现的次数
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
贪婪匹配和惰性匹配
.* 贪婪匹配
.*? 惰性匹配
re 模块
re.match(pattern, string, flags=0)
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。re.search(pattern, string, flags=0)
re.search 扫描整个字符串并返回第一个成功的匹配。re.compile(pattern, flags=0)compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,
供 match() ,search(), findall(), finditer()使用。re.findall(pattern, string, flags=0)
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,
如果没有找到匹配的,则返回空列表, 注意: match 和 search 是匹配一次, findall 匹配所有。re.finditer(pattern, string, flags=0)
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。一般常用的是finditer()
实例: 爬取豆瓣top250
import requests
import re
import csvurl = "https://movie.douban.com/top250?start=0" header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62"
}resp = requests.get(url, headers=header) // 获取网页源代码
page_content = resp.text # 用正则匹配解析数据, 生成一个正则表达式( Pattern )对象
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?'r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>', re.S)# 开始匹配
result = obj.finditer(page_content) // 找到所有符合匹配模式的字符串
f = open("data.csv", mode="a+", newline="") # 这里加newline="" 是防止写入文件多出空行
csvwriter = csv.writer(f) // 创建csv文件写入器
# 遍历迭代器
for it in result:dic = it.groupdict()dic['year'] = dic['year'].strip() # 消除空白字符csvwriter.writerow(dic.values()) # 写入data.csvf.close()
print("OVER!")
bs4解析-HTML语法
bs4相对于使用正则表达式解析HTML文本会更简单一些。
在此之前需要了解一些HTML的基本语法。
HTML超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。
有点类似于markdown的一些语法,简单来说就是使用标签来修改文本的显示方式, 大小, 颜色,位置等等。
基本的标签:
-
标题
HTML 标题(Heading)是通过
-
标签来定义的。
<h1>这是一个标题</h1> <h2>这是一个标题</h2> <h3>这是一个标题</h3>

- HTML 段落
HTML 段落是通过标签
来定义的。

- HTML 链接
HTML 链接是通过标签 来定义的。
<a href="https://www.runoob.com">这是一个链接</a>
href 后面的即指定链接的地址。
-
HTML 图像
HTML 图像是通过标签 来定义的.
<img src="/images/logo.png" width="258" height="39" />
src后面的是图像地址,width和height是宽和高 -
HTML 元素
HTML 文档由 HTML 元素定义
HTML 元素由 开始标签 元素内容 结束标签构成

-
HTML 元素语法
- HTML 元素以开始标签起始
- HTML 元素以结束标签终止
- 元素的内容是开始标签与结束标签之间的内容
- 某些 HTML 元素具有空内容(empty content)
- 空元素在开始标签中进行关闭(以开始标签的结束而结束)
- 大多数 HTML 元素可拥有属性
-
HTML 属性
属性是HTML 元素提供的附加信息。如:
herf属性指明了链接的地址
简单来说一般的HTML 语法格式为
<标签 属性="属性值">被标记的内容
</标签>
Beautiful Soup 库常用函数
-
BeautifulSoup的安装
BeautifulSoup是Python的第三方库,需要安装,直接在Pycharm中安装

在Terminal中输入 pip install bs4, 就OK了 -
BeautifulSoup的常用库函数
-
BeautifulSoup()我们可以使用该函数解析HTML文本, 创造一个BeautifulSoup对象, 如:
import requests
from bs4 import BeautifulSoupurl = "http://www.bjtzh.gov.cn/bjtz/home/jrcj/index.shtml" resp = requests.get(url) resp.encoding = 'utf-8' # windows默认是gbk, 所以要改为 utf-8编码# 解析数据 page = BeautifulSoup(resp.text, "html.parser") # html.paser指定HTML解析器 -
find(标签, 属性) 找到符合的第一个标签即停止,并返回该标签内的所有内容, 仍是BeautifulSoup对象 find_all(标签, 属性) 找到符合的标签,返回的是BeautifulSoup对象的列表如
table = page.find(“table”) # 获取页面中所有table 标签
trs = table.find_all(“tr”) # 获取 页面中所有tr标签元素
-
实例: 爬取菜价
import requests
from bs4 import BeautifulSoup
import csv
# 解析数据
# 1. 将页面源代码交给BeautifulSoup处理,生成BS对象
# 2. 从bs对象中查找数据
# find(标签, 属性) 找到符合的第一个标签即停止,并返回该标签内的所有内容
# find_all(标签, 属性) 找到所有的
# BeautifulSoup会将HTML解析为bs对象, 然后可以直接跟根据标签名查找# 获取数据
url = "http://www.bjtzh.gov.cn/bjtz/home/jrcj/index.shtml"
resp = requests.get(url)
resp.encoding = 'utf-8' # windows默认是gbk, 所以要改为 utf-8编码# 解析数据
page = BeautifulSoup(resp.text, "html.parser") # html.paser指定HTML解析器
table = page.find("table") # 获取页面中所有table 标签
trs = table.find_all("tr")[1:] # 获取 页面中所有tr标签元素\# 创建csv文件
f = open("food_price.csv", "w", encoding="utf-8", newline="")
csvwriter = csv.writer(f)for tr in trs: # 在所有tr中找到所有tdtds = tr.find_all("td")if(len(tds) <= 3): # 该页面中 有一个tr标签元素中 只有三行td, 且不包含菜价信息continuename = tds[0].textavg = tds[3].text.strip()csvwriter.writerow([name + " " +avg]) # 写入菜名和平均菜价# 注意 writerow 如果写入字符串, 要用 [] 括起来, 不然每个字符都会被逗号隔开f.close()
print("over!")
Xpath
Xpath 也是解析源码的一种手段,这里不多做解释。
简单来说就是通过HTML的标签来定位。
批量爬取百度图片
百度图片相对其他图片还是比较好爬的,没有复杂的反爬机制。
另外,header需要加上Accept字段。
还有,通过对百度图片的抓包,会发现,它页面加载的图片是每30张一组,

并且用pn字段来控制。
这30张图片的地址都存储在data字典中,

所以我们第一步复制url,https://image.baidu.com/search/acjson?
然后创建params字典, 将页面的参数都添加进去。
最后用循环控制访问的次数,我们就能愉快的爬取到所有的图片了。
代码:
import requests
url = 'https://image.baidu.com/search/acjson?'
header = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9","Accept-Encoding": "gzip, deflate, br","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Connection": "keep-alive","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39"
}name = input("请输入要搜索的内容")
params = {"tn": "resultjson_com","logid": "11750137256256656289","ipn": "rj","ct": "201326592","is": "","fp": "result","fr":"","word": name,"queryWord": name,"cl": "2","lm": "-1","ie": "utf-8","oe": "utf-8","adpicid": "","st":"","z":"","ic":"","hd":"","latest":"","copyright":"","s":"","se":"","tab":"","width":"","height":"","face":"","istype":"","qc":"","nc": "1","expermode":"","nojc":"","isAsync":"","pn": 30,"rn": "30","1647928939426":""
}
imgid = 1
for i in range(0, 30):resp = requests.get(url, headers=header, params=params).json()datalist = resp['data']for j in range(0, 30):img = requests.get(datalist[j]['middleURL']).contentfilename = "E:/pythonProject/数据集/羊/" + str(imgid) + ".jpg"with open(filename, 'wb') as f:f.write(img)print("已爬取" + str(imgid) + "张")imgid += 1params['pn'] += 30selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google,Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。——百
度百科
简单来说,selenium就是用程序实现用户的实际操作,它本质上是一个Web应用程序测试工具,但用它写爬虫也很方便,能轻松绕过一些反爬机制。
下载:直接在Pycharm中