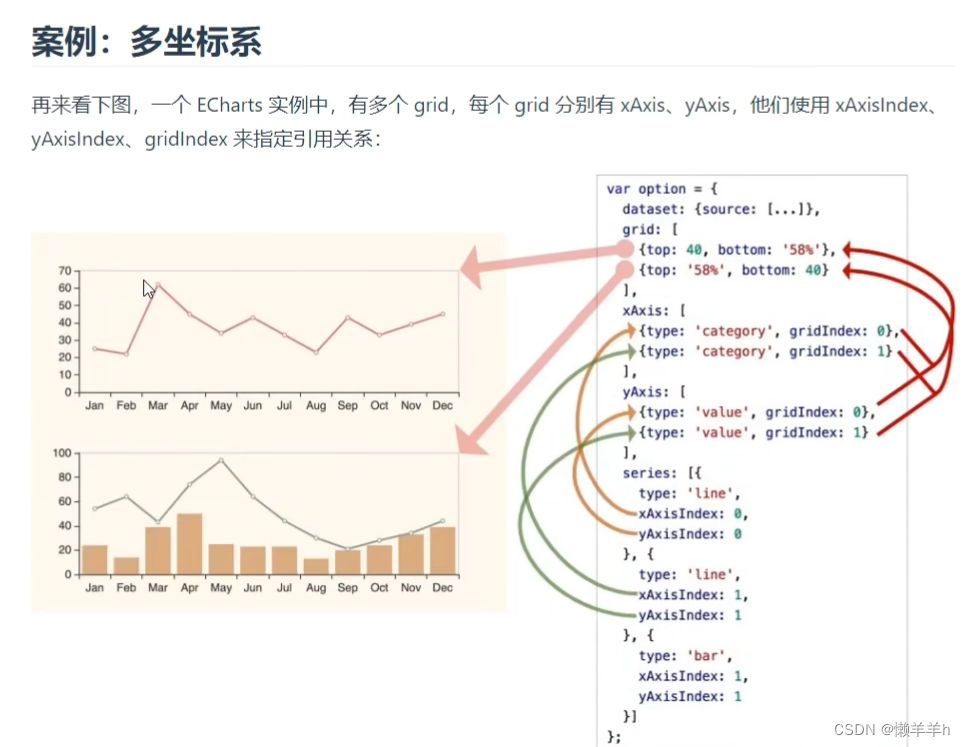
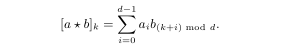如同计算机视觉中一样,在训练目标识别的网络之前,会对图片进行预处理,如 裁切,旋转、放大缩小,以加强网络的泛化能力。在数据挖掘中,我们首先要做的就是对拥有的数据进行分析( 涉及到《概率论与数理分析》的知识 ),这里我们可以利用一些好的数据科学库和可视化库如 pandas、numpy、matplotlib等来辅助数据分析的工作。
目录
- 1.载入需要的各种库
- 1.1 缺失库的安装
- 2.观测数据的首尾信息
- 2.1 查询语句
- 3.洞悉数据总概况
- 3.1 describe()
- 3.2 info()
- 4.数据的是否缺失和异常 以及 预测值的分布
- 4.1 isnull()
- 4.2 预测值分布
- 4.2.1 数据分布概况
- 4.2.2 数据的偏度和峰度
- 4.2.3 预测值的具体频数
1.载入需要的各种库
#coding:utf-8
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')
import missingno as msno
from pandas import DataFrame
import seaborn as sns
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
import matplotlib.pyplot as plt
1.1 缺失库的安装
A.直接利用命令安装
conda install 库名
pip install 库名
B.利用anaconda这个软件平台下载
首先需要注意的是要切换好自己要用的虚拟环境
然后直接搜索 库名 ,再点击Apply即可,如下图

2.观测数据的首尾信息
以训练集为例,观察是否有连贯的错误(如 数据类型不对,数据缺失,数据值不符等)出现,而在首部没有出现,所以有必要查看一下。
import pandas as pd
from pandas import DataFrame, Series
import matplotlib.pyplot as plt
Train_data = pd.read_csv('./train.csv')
Train_data.head().append(Train_data.tail())
Train_data.shape
这里需要注意的是文件的读取,选择是相对路径还是绝对路径
数据展示
id heartbeat_signals label
0 0 0.9912297987616655,0.9435330436439665,0.764677... 0.0
1 1 0.9714822034884503,0.9289687459588268,0.572932... 0.0
2 2 1.0,0.9591487564065292,0.7013782792997189,0.23... 2.0
3 3 0.9757952826275774,0.9340884687738161,0.659636... 0.0
4 4 0.0,0.055816398940721094,0.26129357194994196,0... 2.0
99995 99995 1.0,0.677705342021188,0.22239242747868546,0.25... 0.0
99996 99996 0.9268571578157265,0.9063471198026871,0.636993... 2.0
99997 99997 0.9258351628306013,0.5873839035878395,0.633226... 3.0
99998 99998 1.0,0.9947621698382489,0.8297017704865509,0.45... 2.0
99999 99999 0.9259994004527861,0.916476635326053,0.4042900... 0.0(100000, 3)
2.1 查询语句
data.head().append(data.tail())——观察首尾数据
data.shape——观察数据集的行列信息
3.洞悉数据总概况
这里会使用 pandas库中的describe() 和 info() 这两个函数来对数据进行一个总概况的观察。
以训练集为例
3.1 describe()
通过describe() 可以获取数据的相关统计量,如 个数count、平均值mean、方差std、最小值min、中位数25% 50% 75% 、最大值。这些指标可以帮我迅速掌握数据的表征范围和是否有异常值出现。
print(Train_data.describe())
id label
count 100000.000000 100000.000000
mean 49999.500000 0.856960
std 28867.657797 1.217084
min 0.000000 0.000000
25% 24999.750000 0.000000
50% 49999.500000 0.000000
75% 74999.250000 2.000000
max 99999.000000 3.000000
3.2 info()
print(Train_data.info)
id heartbeat_signals label
0 0 0.9912297987616655,0.9435330436439665,0.764677... 0.0
1 1 0.9714822034884503,0.9289687459588268,0.572932... 0.0
2 2 1.0,0.9591487564065292,0.7013782792997189,0.23... 2.0
3 3 0.9757952826275774,0.9340884687738161,0.659636... 0.0
4 4 0.0,0.055816398940721094,0.26129357194994196,0... 2.0
... ... ... ...
99995 99995 1.0,0.677705342021188,0.22239242747868546,0.25... 0.0
99996 99996 0.9268571578157265,0.9063471198026871,0.636993... 2.0
99997 99997 0.9258351628306013,0.5873839035878395,0.633226... 3.0
99998 99998 1.0,0.9947621698382489,0.8297017704865509,0.45... 2.0
99999 99999 0.9259994004527861,0.916476635326053,0.4042900... 0.0[100000 rows x 3 columns]>
测试集的信息
print(Test_data.info())
RangeIndex: 20000 entries, 0 to 19999
Data columns (total 2 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 id 20000 non-null int64 1 heartbeat_signals 20000 non-null object
dtypes: int64(1), object(1)
memory usage: 312.6+ KB
4.数据的是否缺失和异常 以及 预测值的分布
4.1 isnull()
缺失值直接用 pandas的isnull()判断即可
Train_data.isnull().sum()
id 0
heartbeat_signals 0
label 0
dtype: int64
4.2 预测值分布
Train_data['label']
0 0.0
1 0.0
2 2.0
3 0.0
4 2.0...
99995 0.0
99996 2.0
99997 3.0
99998 2.0
99999 0.0
Name: label, Length: 100000, dtype: float64
Train_data['label'].value_counts()
0.0 58883
4.0 19660
2.0 12994
1.0 6522
3.0 1941
Name: label, dtype: int64
4.2.1 数据分布概况
import scipy.stats as st
y = Train_data['label']
plt.figure(1); plt.title('Default')
sns.distplot(y, rug=True, bins=20)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
plt.show()
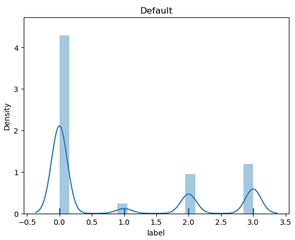
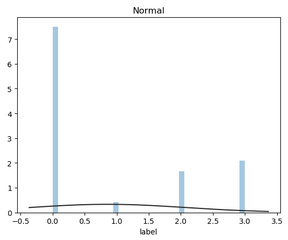

4.2.2 数据的偏度和峰度
偏度百科:
正态分布的偏度为0,两侧尾部长度对称。若以bs表示偏度。bs<0称分布具有负偏离,也称左偏态,此时数据位于均值左边的比位于右边的少,直观表现为左边的尾部相对于与右边的尾部要长,因为有少数变量值很小,使曲线左侧尾部拖得很长;bs>0称分布具有正偏离,也称右偏态,此时数据位于均值右边的比位于左边的少,直观表现为右边的尾部相对于与左边的尾部要长,因为有少数变量值很大,使曲线右侧尾部拖得很长;而bs接近0则可认为分布是对称的。若知道分布有可能在偏度上偏离正态分布时,可用偏离来检验分布的正态性。右偏时一般算术平均数>中位数>众数,左偏时相反,即众数>中位数>平均数。正态分布三者相等。

峰度百科:用来度量随机变量概率分布的陡峭程度

sns.distplot(Train_data['label']);
print("Skewness: %f" % Train_data['label'].skew())
print("Kurtosis: %f" % Train_data['label'].kurt())
Skewness: 0.871005
Kurtosis: -1.009573
4.2.3 预测值的具体频数
plt.hist(Train_data['label'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()