这里写目录标题
- 1 爬虫介绍
- 1.1 什么是爬虫
- 1.2 爬虫的作用
- 1.3 业界情况
- 1.4 合法性
- 1.5 反爬
- 1.6 爬虫的本质
- 1.7 爬虫的基本流程
- 1.8 爬虫的基本手段
- 1.9 为什么是python
1 爬虫介绍
1.1 什么是爬虫
爬虫更官方点的名字叫数据采集,英文一般称作spider
网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,
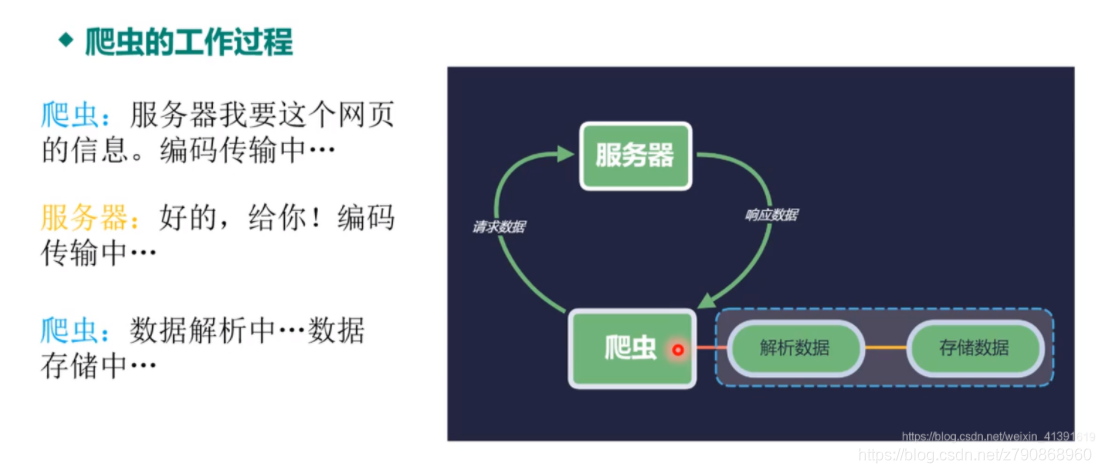
爬虫程序通过请求URL地址,根据响应的内容进行解析采集数据。
如果响应内容是HTML,分析其DOM树结构,进行DOM解析,或者是正则匹配。
如果响应内容是XML/JSON数据,则可以转换数据对象,然后对再对数据对象进行解析。
网络爬虫在本质上就是从互联网上爬取数据!

爬虫更官方点的名字叫数据采集,英文一般称作spider
网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,
爬虫程序通过请求URL地址,根据响应的内容进行解析采集数据。
如果响应内容是HTML,分析其DOM树结构,进行DOM解析,或者是正则匹配。
如果响应内容是XML/JSON数据,则可以转换数据对象,然后对再对数据对象进行解析。
网络爬虫在本质上就是从互联网上爬取数据!
1.2 爬虫的作用
现如今大数据时代已经到来,网络爬虫技术成为这个时代不可或缺的一部分,企业需要数据来分析
用户行为,来分析自己产品的不足之处,来分析竞争对手的信息等等
通过有效的爬虫手段批量的从互联网上采集数据,它不仅可以降低人工成本,还可以提高有效数据
量,给运营/销售部门以数据支撑,从而加快企业的产品发展。

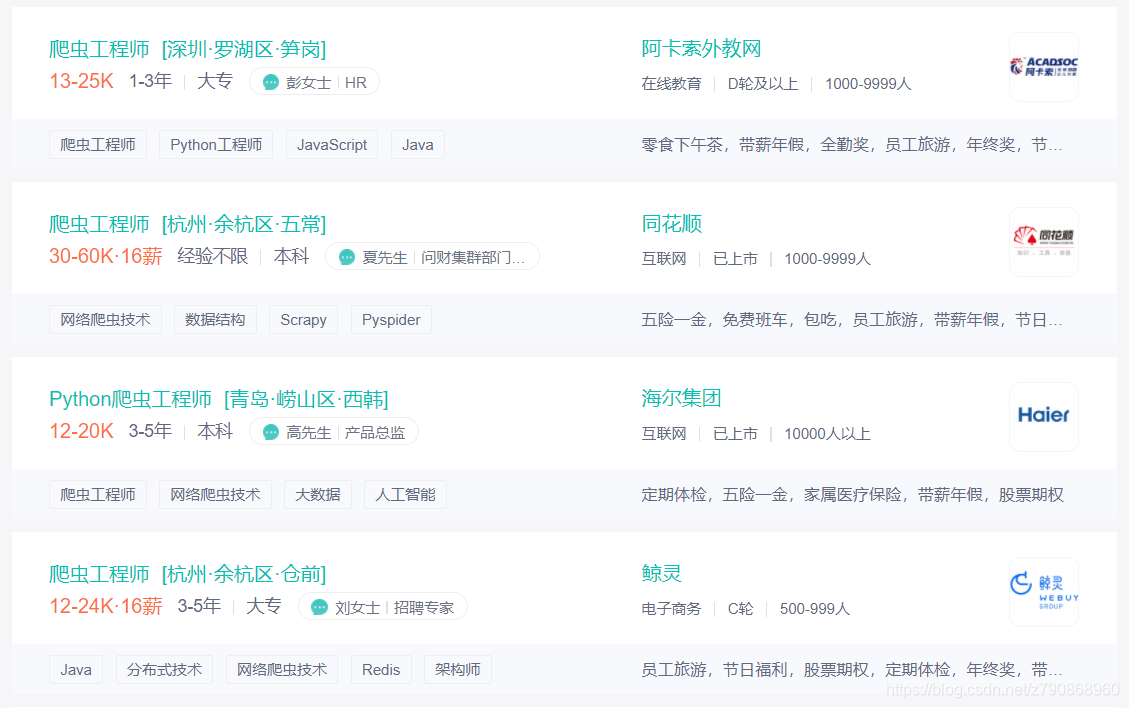
1.3 业界情况
目前互联网产品竞争激烈,业界大部分公司都会使用爬虫技术对竞品产品的数据进行挖掘、采集和
大数据分析,这是商业竞争的必备手段,所以很多公司都设立了“爬虫工程师”的工作岗位。
1.4 合法性
爬虫是利用程序进行批量爬取网页上的公开信息,也就是前端显示的数据信息。因为信息是完全公
开的,所以是合法的。其实就像浏览器一样,浏览器是解析响应内容并渲染为页面,而爬虫是解析
响应内容并采集想要的数据再进行存储。
魔蝎被查
https://baijiahao.baidu.com/s?id=1643978804427289836&wfr=spider&for=pc

爬虫究竟是合法还是违法
一段代码导致200人公司被抓:https://www.cnblogs.com/ityouknow/p/11684770.html
爬虫究竟是合法还是违法:https://www.cnblogs.com/ityouknow/p/11697613.html
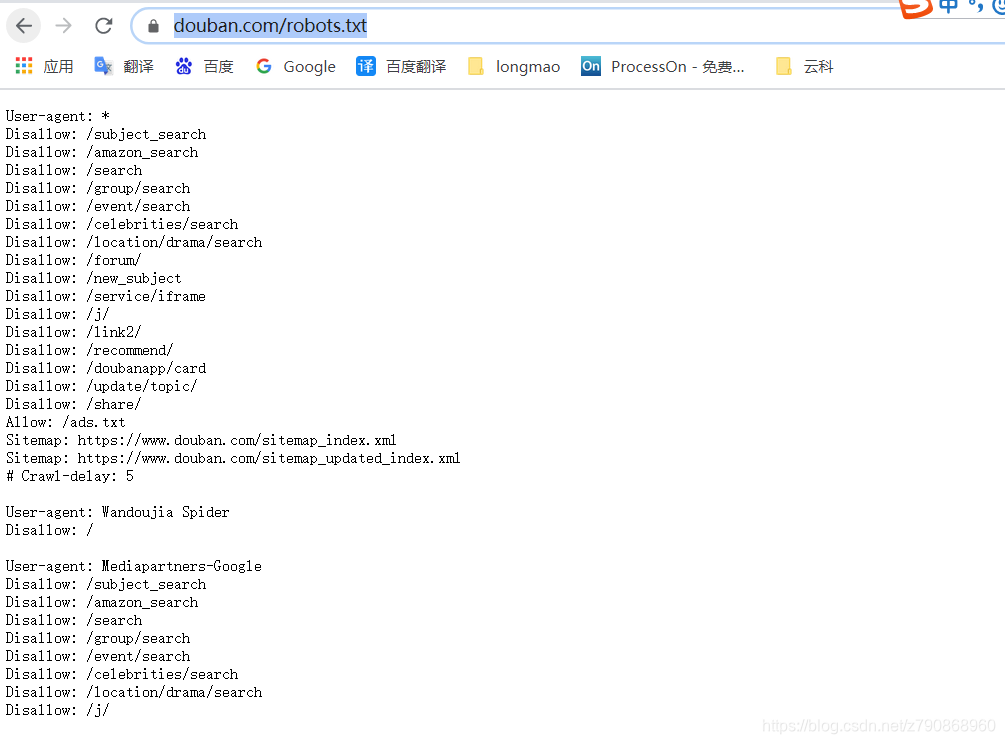
豆瓣rebots:https://www.douban.com/robots.txt
rebots文件告诉爬虫什么东西可以访问,什么东西不能访问
从rebots中还能获取网站地图:https://www.douban.com/sitemap_index.xml

1.5 反爬
爬虫很难完全的制止,道高一尺魔高一丈,这是一场没有硝烟的战争,即码农VS码农。反爬虫一些
手段如下所示:
(1)合法检测:请求校验(例如用请求头信息中的useragent属性来判断是否为一个浏览器,例
如用请求头信息中的referer属性来确定上一次的跳转页面等)。
(2)小黑屋:利用IP地址限制用户的请求频率,或者直接拦截(即封IP)。
(3)投毒:是反爬虫的最高境界,即可以不用拦截爬虫,因为拦截是一时的,而投毒则可以返
回虚假数据(即构造一个含有虚假数据的页面返回给你),可以误导竞品的决策。
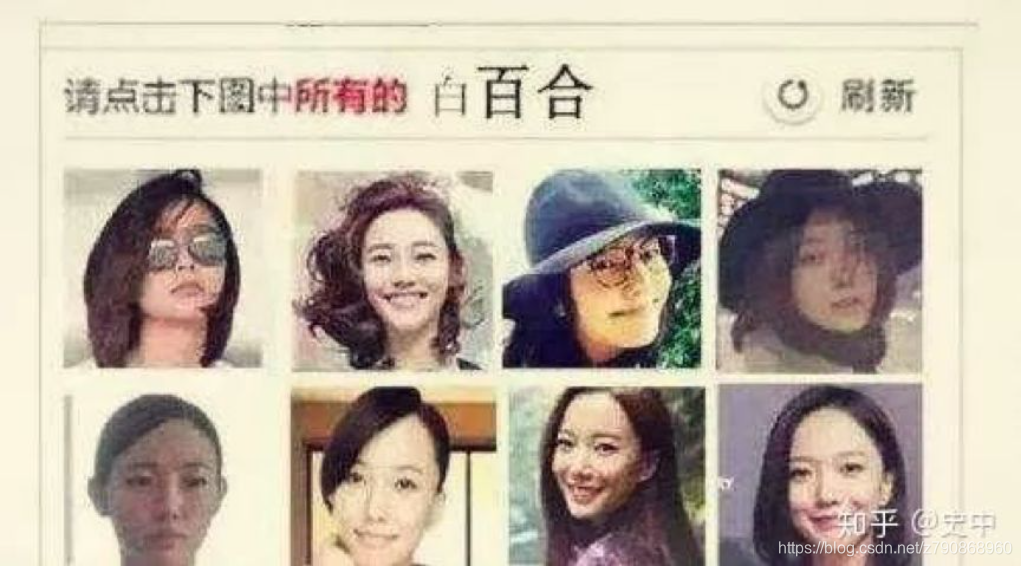
(4)输入验证码:即判断当前的访问用户是一个真人还是一个爬虫机器人。
知乎有哪些有趣的反爬虫手段:https://www.zhihu.com/question/58342241
12306的验证码
1.6 爬虫的本质
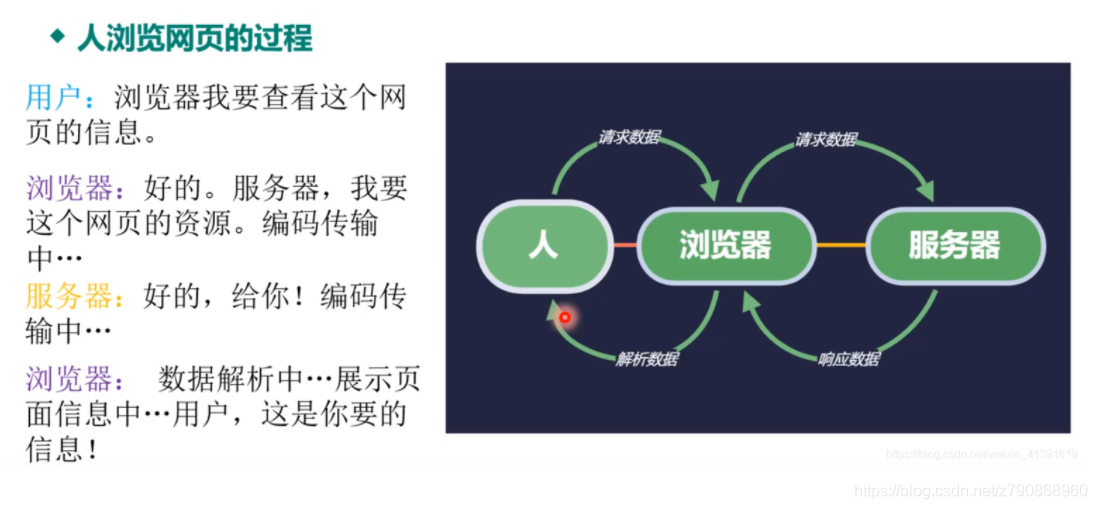
爬虫的本质就是自动化的去模拟正常人类发起的网络请求,然后获取网络请求所返回的数据。 跟我
们人手动去点击一个连接,访问一个网页获取数据,并没有什么本质的区别。
1.7 爬虫的基本流程
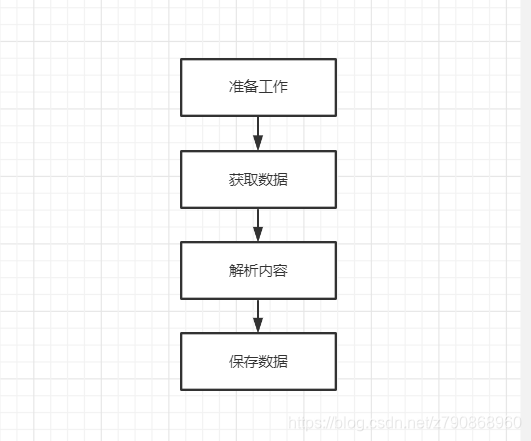
爬虫的基本流程,如下所示:
(1)准备工作,通过浏览器查看分析目标网页,学习编程基础规范。
(2)获取数据,通过HTTP库向目标站点发起请求,请求可以包含额外的header等信息,如果服
务器能正常响应,会得到一个Response,便是所要获取的页面内容。
(3)解析内容,得到的内容可能是HTML,json等格式,可以使用页面解析库、正则表达式等进
行解析
(4)保存数据,保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文
件
1.8 爬虫的基本手段
破解请求限制
请求头设置,如将请求头信息中的useragent属性设置为有效客户端。
根据实际情况,控制请求频率。
IP代理。
签名/加密参数从HTML/Cookie/JS分析。
破解登录授权
请求带上用户Cookie信息(身份认证信息)。
破解验证码
简单的验证码可以使用识图读验证码第三方库。
解析数据
HTML的DOM解析。
正则匹配,通过的正则表达式来匹配想要爬取的数据,如:有些数据不是在HTML标签里,而
是在HTML的标签的JS变量中。
使用第三方库解析HTML或DOM,例如使用类jQuery的库。
数据字符串。
正则匹配(根据情景使用)。
转成JSON/XML对象进行解析。
1.9 为什么是python
爬虫可以用各种语言写, C++, Java都可以, 为什么要Python?
首先用C++搞网络开发的例子不多。
Java侧重于Web开发。
Python这种稍严谨而流行库又非常多的语言, 都大大弱化了针对计算机运行速度而打造的特
性, 强化了为程序员容易思考而打造的特性。所以我们选择Python。
Python的优势
Python语法易学,容易上手。
社区活跃,实现方案多可参考。
各种功能包丰富。
少量代码即可完成强大功能。