主方法main
定义主函数main,程序的入口,首先导入io包,用os.path.exists判断字典文件是否存在,如果不存在则新建一个,然后进入循环中,让用户输入相应的数字,执行相应的功能。
def main():
flag = os.path.exists('dictionary.csv')
if flag == False:
d = open('dictionary.csv', 'w')
d.close()
while 'true':
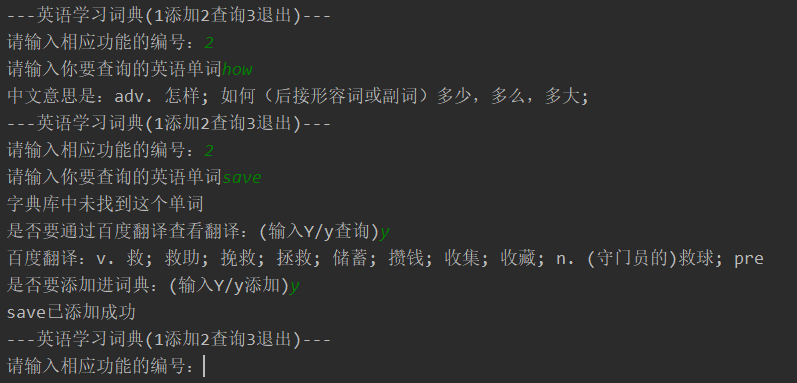
print('---英语学习词典(1添加2查询3退出)---')
num = input('请输入相应功能的编号:')
if num == '1':
inputWord()
elif num == '2':
serachWord()
elif num == '3':
break
else:
print('输入有误,请重新输入')
inputWord方法
inputWord这是一个添加英语和对应中文意思的方法,打开这个文件,先把光标移动到开头,通过一行一行扫描,然后把行内的英语单词通过分片的形式分割出来,判断用户输入的英文单词字典中是否存在,如果存在则提示,并输入对应的翻译,如果不存在则再进行添加进字典里面
def inputWord():
with open('dictionary.csv', 'a+', encoding='utf-8', newline='') as csv_file:
csv_file.seek(0)
e = input('请输入你要录入的英语单词:')
files = csv_file.readlines()
for file in files:
file = file.replace('\n', '')
ls = file.split('-')
if ls[0] == e:
print('该单词已添加过了,中文意思是:' + ls[1])
return
# 字典找不到单词,开始添加
csv_file.seek(2)
c = input('请输入对应的中文意思:')
line = '\n' + e + '-' + c
csv_file.writelines(line)
print(e + '已添加成功')
serachWord方法
serachWord这是查找功能,用户输入英文单词,查询中文意思,打开字典文件,每行扫描,提取前面的英文单词,遍历与用户输入的单词匹配,如果不存在则提示,没有找到这个单词,然后给用户提供是否需要通过百度翻译,查看意思,并且翻译结束后可以添加进字典中
def serachWord():
word = input('请输入你要查询的英语单词')
with open('dictionary.csv', 'r+', encoding='utf-8') as csv_file:
files = csv_file.readlines()
# print(files)
# print(type(files))
for file in files:
file = file.replace('\n', '')
ls = file.split('-')
# print(ls)
if ls[0] == word:
print('中文意思是:' + ls[1])
return
print('字典库中未找到这个单词')
flag = input('是否要通过百度翻译查看翻译:(输入Y/y查询)')
if (flag == 'Y') | (flag == 'y'):
chn = baudu(word)
print('百度翻译:' + chn)
if chn != '出错了':
flag2 = input('是否要添加进词典:(输入Y/y添加)')
if (flag2 == 'Y') | (flag2 == 'y'):
line = '\n' + word + '-' + chn
csv_file.writelines(line)
print(word + '已添加成功')
baidu方法
baidu这个方法,是通过百度翻译官网爬虫实现,用到requests库
def baudu(word):
url = 'https://fanyi.baidu.com/sug'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
data = {'kw': word}
try:
r = requests.post(url, data=data, headers=headers, timeout=5)
r.raise_for_status()
data = r.json()['data']
for i in data:
if i['k'] == word:
return i['v']
else:
return '出错了'
except:
return '出错了'
实验结果: