本文主要内容:
1.爬虫的相关概念。
2.Requsets库安装。
3.Requests库介绍。
4.爬取网页的通用代码框架。
1.爬虫相关概念。
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。(百度百科)
网络爬虫就是从网页中按照规则爬取数据,然后对数据进行处理,得到我们需要的有价值的数据的过程。
从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
2.Requests库安装。
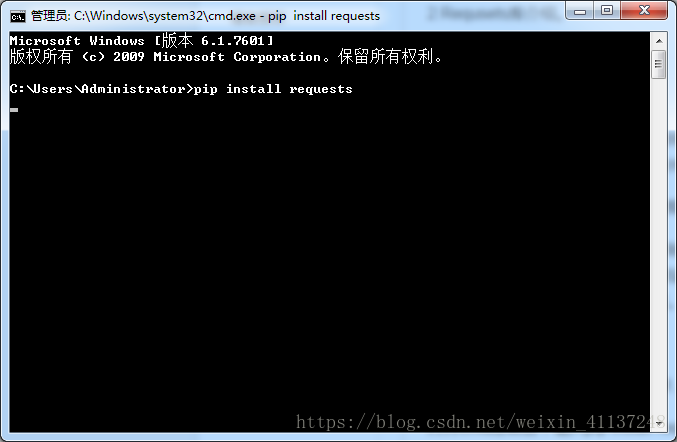
要使用Requests库需要先进行安装,我的Python环境是3.6。安装过程很简单,只须在cmd控制台上用pip命令就行可以了。
打开cmd控制台,输入pip install requests.
3.Requests库介绍:
以下列出方法名及用途,具体使用大家可以自行百度或者参考文章最后的链接文件,里面有详细的Request库介绍。

我们通过调用Request库中的方法,得到返回的对象。其中包括两个对象,request对象和response对象。
request对象就是我们要请求的url,response对象是返回的内容,如图:

response对象比Request对象更复杂,response对象包括以下属性:
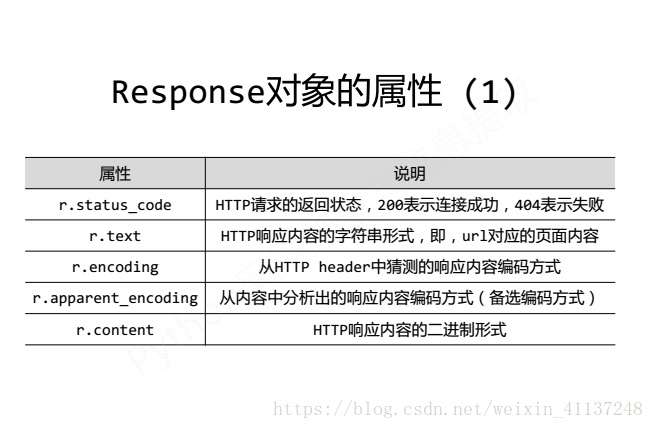
接下来我们测试response对象属性:
假设我们访问的是百度的首页,打开IDLE输入以下代码:
import requests
r=requests.get("http://baidu.com")
print(r.status_code)
print(r.encoding)
print(r.apparent_encoding)
print(r.text[:100])
得到的结果如下:

4.爬取网页的通用代码框架。
前面已经大致了解了Request库以及爬虫的工作原理,下面介绍的是爬取网页的通用代码框架,这在我们的对话机器人中也将用到,因为爬取网页具有不确定性(网页不响应,url错误等),在代码中增加try,except语句检测错误。
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30) #获得url链接对应的response对象
r.raise_for_status() #检查状态码,如果状态码不是200则抛出异常。
r.encoding = r.apparent_encoding #用分析内容的编码作为整我对象的编码,视情况使用。
return r.text
except:
print("faile")
return ""
这个框架是今后都会用到的,需要理解和掌握。
在我们的实例中我们用到这个框架爬取段子,网址是我随便百度到的一个段子网,具体代码如下:
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
#r.encoding = r.apparent_encoding
return r.text
except:
print("faile")
return ""
def main():
url = 'http://duanziwang.com/category/%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%AE%B5%E5%AD%90/1/'
html = getHTMLText(url)
print(html)
main()
运行截图如下:
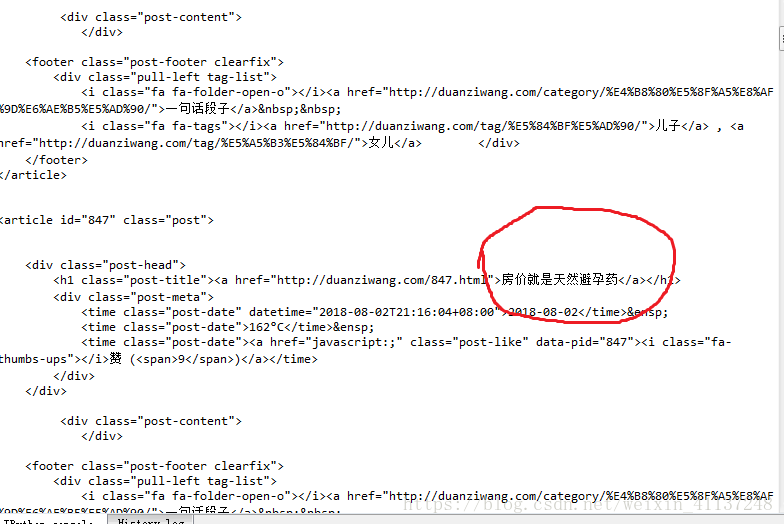
这是我们得到的返回内容,在后面的文章中我们将从庞大的HTML文本中使用beautifulsoup库提取具体的我们想要的东西,即提取出段子(标红内容)。
更详细的介绍请参考文档:
链接:https://pan.baidu.com/s/1ciCFifH_MzGMdAvDZVX3-A 密码:2ovp