目录
- 网络爬虫
- 一、爬取[南阳理工OJ题目](http://www.51mxd.cn/problemset.php-page=1.htm)
- python代码
- 结果
- 二、爬取[重交新闻](http://news.cqjtu.edu.cn/xxtz.htm)
- python代码
- 结果
- 小结
网络爬虫
简介
网络爬虫英文名叫Web Crawler戒WebSpider。是一种自动浏览网页并采集所需要信息癿程序。
通过编写脚本模拟浏览器发起请求获取数据。爬虫从初始网页的URL开始, 获取初始网页上的URL,在抓取网页的过程中,不断从当前页面抽取新的url放入队列。直到满足系统给定的停止条件才停止。
一、爬取南阳理工OJ题目
爬取每道题的题号,难度,标题,通过率,通过数/总提交数

python代码
安装第三方包requests,BeautifulSoup4
pip install requests
pip install BeautifulSoup4


import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']# 题目数据
subjects = []# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):# get请求第pages页r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)# 判断异常r.raise_for_status()# 设置编码r.encoding = 'utf-8'# 创建BeautifulSoup对象,用于解析该html页面数据soup = BeautifulSoup(r.text, 'lxml')# 获取所有td标签td = soup.find_all('td')# 存放某一个题目的所有信息subject = []# 遍历所有tdfor t in td:if t.string is not None:subject.append(t.string) # 获取td中的字符串if len(subject) == 5: # 每5个为一个题目的信息subjects.append(subject)subject = []# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:fileWriter = csv.writer(file)fileWriter.writerow(csvHeaders) # 写入表头fileWriter.writerows(subjects) # 写入数据print('\n题目信息爬取完成!!!')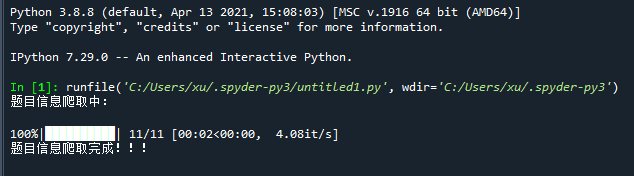
结果


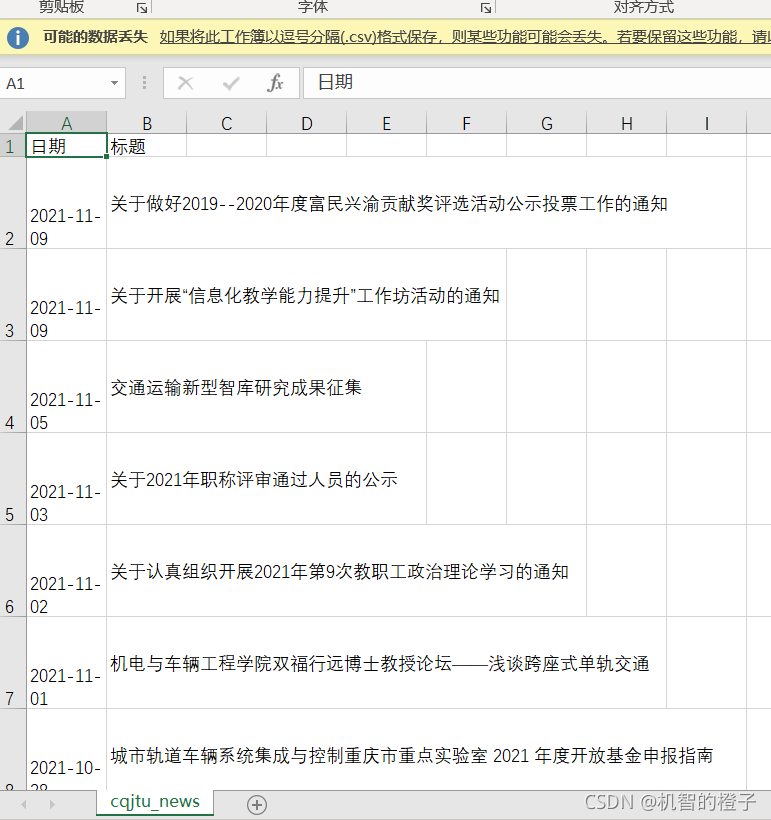
二、爬取重交新闻
爬取新闻的发布日期 和 标题

python代码
import requests
from bs4 import BeautifulSoup
import csv# 获取每页内容
def get_one_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}try:info_list_page = [] # 一页的所有信息resp = requests.get(url, headers=headers)resp.encoding = resp.status_codepage_text = resp.textsoup = BeautifulSoup(page_text, 'lxml')li_list = soup.select('.left-list > ul > li') # 找到所有li标签for li in li_list:divs = li.select('div')date = divs[0].string.strip()title = divs[1].a.stringinfo = [date, title]info_list_page.append(info)except Exception as e:print('爬取' + url + '错误')print(e)return Noneelse:resp.close()print('爬取' + url + '成功')return info_list_page# main
def main():# 爬取所有数据info_list_all = []base_url = 'http://news.cqjtu.edu.cn/xxtz/'for i in range(1, 67):if i == 1:url = 'http://news.cqjtu.edu.cn/xxtz.htm'else:url = base_url + str(67 - i) + '.htm'info_list_page = get_one_page(url)info_list_all += info_list_page# 存入数据with open('教务新闻.csv', 'w', newline='', encoding='utf-8') as file:fileWriter = csv.writer(file)fileWriter.writerow(['日期', '标题']) # 写入表头fileWriter.writerows(info_list_all) # 写入数据if __name__ == '__main__':main()
结果


小结
分析所要获取的内容信息的存放位置后设置条件进行网络爬虫。
链接
网络爬虫入门