一、Scrapy
1、cookie设置
目前cookie的设置不支持在headers进行设置, 需要通过以下三种方式进行设置:
第一种:setting文件中设置cookie
- 当
COOKIES_ENABLED是注释的时候,scrapy默认没有开启cookie。 - 当
COOKIES_ENABLED没有注释设置为False的时候,scrapy默认使用了settings里面的cookie。 - 当
COOKIES_ENABLED设置为True的时候,scrapy就会把settings的cookie关掉,使用自定义cookie。
注意:
- 当使用settings的cookie的时候,又把
COOKIES_ENABLED设置为True,scrapy就会把settings的cookie关闭,而且也没使用自定义的cookie,会导致整个请求没有cookie,导致获取数据失败。- 如果使用自定义cookie就把
COOKIES_ENABLED设置为True- 如果使用settings的cookie就把
COOKIES_ENABLED设置为False
第二种:middlewares中设置cookie
在middlewares中的downloadermiddleware中的process_request中配置cookie,配置如下:
request.cookies=
{'Hm_lvt_a448cb27ae2acb9cdb5f92e1f0b454f3': '1665643660',
' _ga': 'GA1.1.755852642.1665643660'
}
注意:cookie内容要以键值对的形式存在
第三种:在spider爬虫主文件中,重写start_request方法,在scrapy的Request函数的参数中传递cookies
重载start_requests方法
def start_requests(self):headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) Gecko/20100101 Firefox/44.0"}# 指定cookiescookies = {'Hm_lvt_a448cb27ae2acb9cdb5f92e1f0b454f3': '1665643660', ' _ga': 'GA1.1.755852642.1665643660'}
2、Get请求带参数
yield scrapy.FormRequest(url=url,method='GET',formdata=params,callback=self.parse_result
)
3、 item数据只有最后一条
只显示主页数据中爬到的最后一条数据,其他都正常
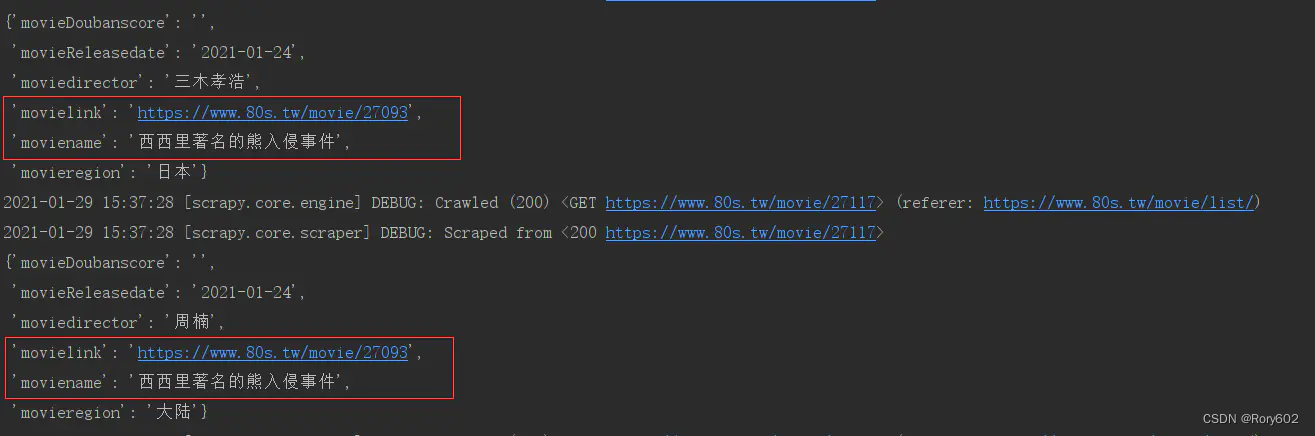
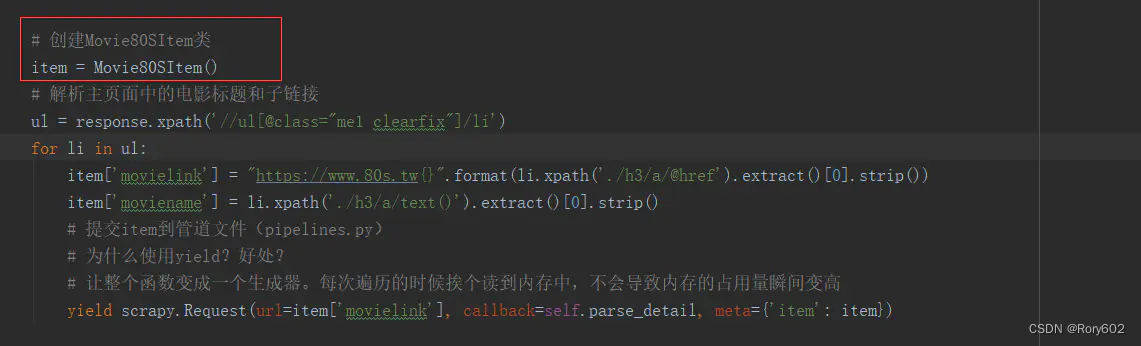
这是我对标签进行遍历时,将item对象放置在了for循环的外部。修改代码就好
修改前:
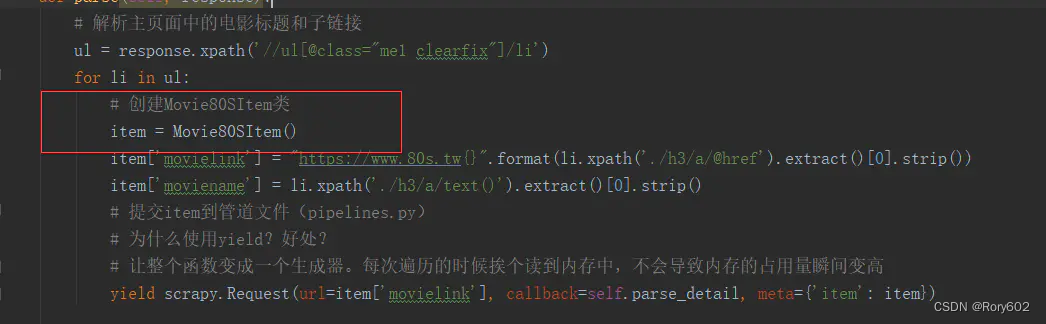
修改后:
成功
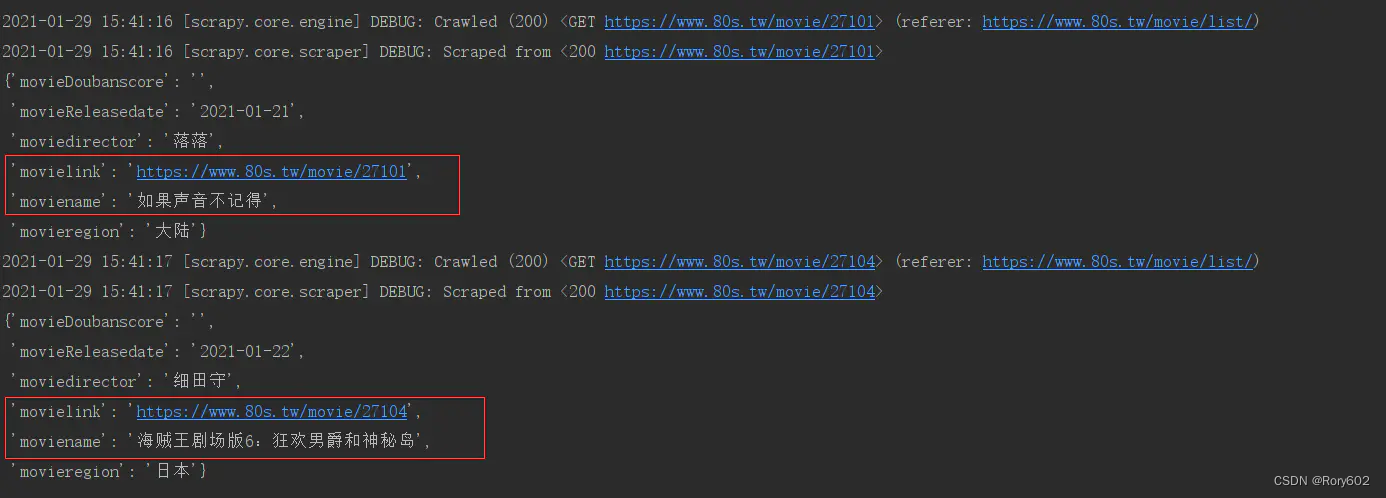
scrapy中的yield scrapy.Request 在传递item 的注意点, 或者使用deepcopy
4、start_requests或者start_urls多个请求只请求第一个
默认情况下,scrapy防止重复请求。由于在起始url中只有参数不同,scrapy会将起始url中的其余url视为第一个url的重复请求。这就是为什么你的spider在获取第一个url后停止。为了解析其余的url,我们在scrapy请求中启用了dont_filter标志。
修改前:
def start_requests(self):for i in range(10):yield scrapy.Request('https://baidu.com', self.parse, meta={"seq": i})
修改后:
def start_requests(self):for i in range(10):yield scrapy.Request('https://baidu.com', self.parse, meta={"seq": i}, dont_filter=True)
5、数据流
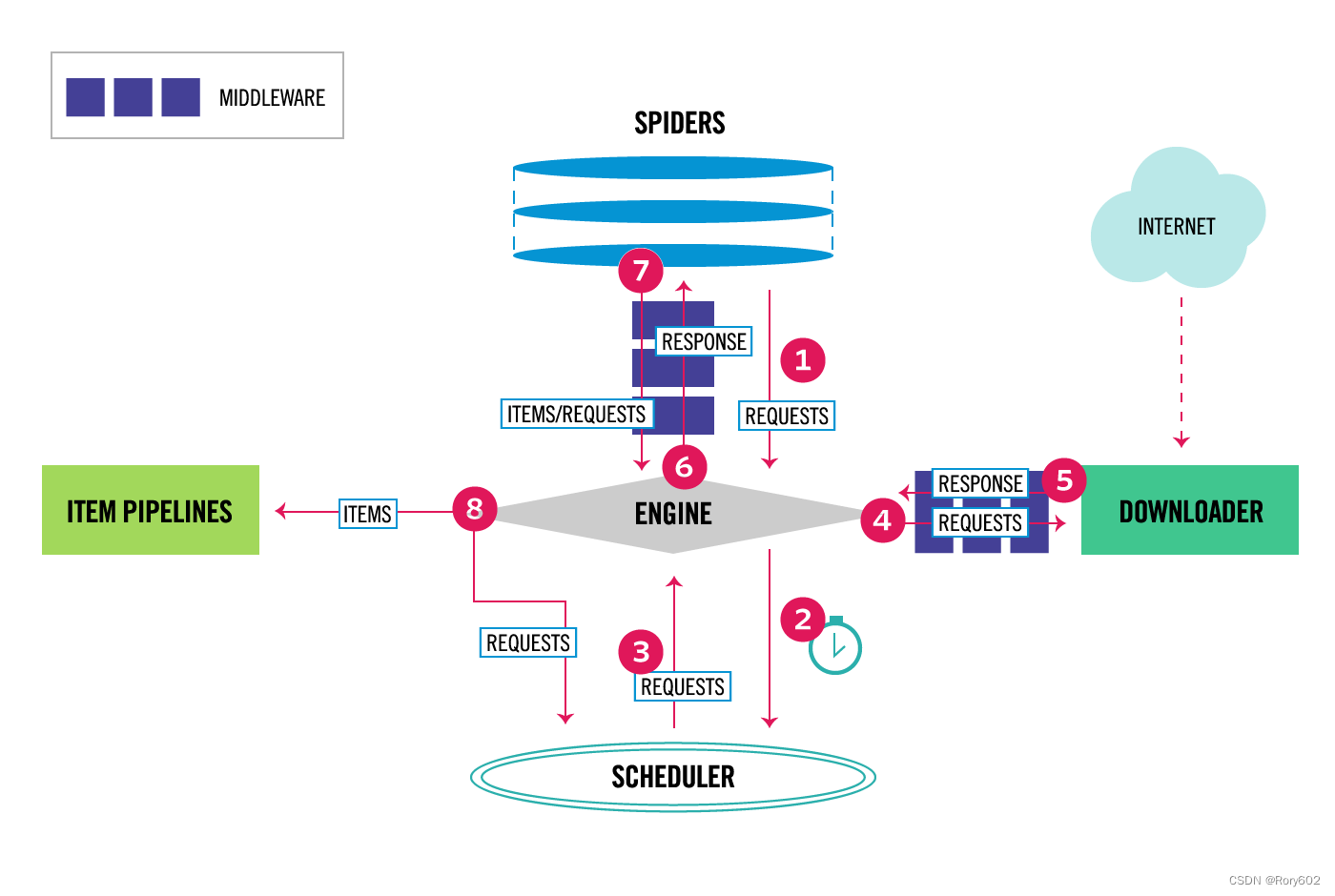
Scrapy中的数据流是由执行引擎控制的,它是这样的:
Engine <component-engine>方法获取要来自Spider <component-spiders>爬取的初始请求。Engine <component-engine>将请求交给Scheduler <component-scheduler>调度,并向Scheduler <component-scheduler>索取下一个抓取请求。Scheduler <component-scheduler>从队列中返回下一个请求给Engine <component-engine>。Engine <component-engine>通过Downloader middleware <component-download -middleware将请求发送给Downloader <component-downloader>。- 一旦页面完成下载,
Downloader <component-downloader>生成一个响应(带有该页面)并将其发送给引擎,传递给Downloader middleware <component-download -middleware。 Engine <component-engine>从Downloader <component-downloader>接收响应,并将其通过Spider Middleware <component- Spider Middleware发送到Spider <component- Spider >进行处理。Spider <component- Spider >处理响应,并通过Spider Middleware <component- Spider Middleware向Engine <component-engine>返回抓取items和新请求。Engine <component-engine>将已处理的items发送到Item pipeline <component-pipeline >,然后将已处理的请求发送到Scheduler <component-scheduler>,并请求可能的下一个请求进行爬取。- 该过程重复(从步骤3开始),直到不再有来自
Scheduler <component-scheduler>的请求。
6、组件
Scrapy Engine
引擎负责控制系统所有组件之间的数据流,并在某些操作发生时触发事件。
Scheduler
scheduler <topics-scheduler> 从引擎接收请求,并将它们入队列,以便在引擎请求它们时稍后提供它们(也提供给引擎)。
Downloader
Downloader负责获取网页并将其提供给引擎,而引擎又将其提供给spiders。
Spiders
spider是由Scrapy用户编写的自定义类,用于解析响应并从中提取items <topics-items>或要发送的其他请求。
Item Pipeline
The Item Pipeline负责处理被spiders提取(或刮取)的items。典型的任务包括清理、验证和持久化(比如将items存储在数据库中)。
Downloader middlewares
下载器中间件是位于引擎和下载器之间的特定钩子,当请求从引擎传递到下载器时处理请求,并处理从下载器传递到引擎的响应。
如果需要执行以下操作之一,请使用Downloader中间件:
- 在请求被发送到Downloader之前处理它(即在Scrapy将请求发送到网站之前)。
- 发送给
spider之前更改响应。 - 发送一个新的Request,而不是将收到的响应传递给
spider。 - 在不获取网页的情况下将响应传递给爬行器
- 默默地放弃一些请求。
Spider middlewares
Spider middlewares是位于引擎和Spiders之间的特定钩子,能够处理spider输入(responses)和输出(items 和 requests)。
如果有以下需要,可以使用Spider中间件:
- spider回调输出的后处理,更改、增加、删除请求或items。
- start_requests的后处理。
- spider的异常处理。
- 根据响应内容为某些请求调用errback而不是回调。
二、代码断点
1、网站代码运行的时间轴
加载html、加载js-->运行js初始化-->用户触发了某个事件-->调用某断js-->明文数据–>加密函数-->加密数据–>给服务器发信息(XHR-SEND)–>接收到服务器数据-->解密函数–>刷新网页渲染
2、常用断点
- DOM
- 定位比较准
- 执行比较靠前
- 加密函数比较远
- 我们无法根据栈快速定位
- DOM事件
- 如果DOM断点不能下,就可以用DOM事件,和DOM端点特性一致。可以根据事件,例如:
搜索、提交按钮定位js代码
- 如果DOM断点不能下,就可以用DOM事件,和DOM端点特性一致。可以根据事件,例如:
- XHR
- 执行比较靠后,距离加密函数相对较近,可以根据栈快速定位
- 非xhr发送的就无法断点
- 代码行
- 代码中debugger
- 全局事件(浏览器事件)
- 异常捕获
- 处理try的时候
三、加解密
1、流程
抓包 -> 调试 -> 扣取js ->改写 -> 本地运行值
2、常见的加密方式
2.1 取盐校验(不可逆)
- 预备知识
(1)md5、md2、md4、带密码的md5(hmac)
概述:
MD5信息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。md5存在16位、32位、40位
md5为什么不能解密?
MD5在线加密原因1:MD5加密原理是散列算法,散列算法也称哈希算法。计算机专业学的数据结构就有哈希表这一知识点。比如10除以3余数为一,4除以3余数也为一,但余数为一的就不知道这个数是哪个了。所以md5不能解密。
原因2:MD5是一种加密技术方法。MD5的全称是Message-digest Algorithm 5,也称为信息摘要算法。通俗的讲,将一段密码截取掉一部分,剩下的那部分,你无法把他还原。例如:123456789,截取掉中间一部分456,剩下123789。当你在数据库拿到123789这串加密串时,你无法知道原来的密码是多少。 - 代码测试:
下载jquery.md5.js文件function testmd5(){var password = $("#md5").val();var md5password = $.md5(password);console.log("没有加密之前的是:"+password);console.log("加密以后是:"+md5password);
(2)sha1、sha256、sha512
- sha :40位、64位、128位
2.2 对称加密 (可逆)
(1)AES
-
预备知识
AES加密 — 详解
在线解密or加密地址 -
代码测试:
js实现AES加密
安装:npm i crypto-jslet str = '****';// 需要加密的字符串 let keyStr = '****';// 密钥 let ivStr = '****';// iv偏移量 const key = CryptoJS.enc.Utf8.parse(keyStr); // 十六位十六进制数作为密钥 const iv = CryptoJS.enc.Utf8.parse(ivStr); // 十六位十六进制数作为密钥偏移量 let srcs = CryptoJS.enc.Utf8.parse(str); let encrypted = CryptoJS.AES.encrypt(srcs, key, { iv: iv, mode: CryptoJS.mode.CBC, padding: CryptoJS.pad.Pkcs7 }); let appKey = encrypted.toString();//加密后的信息js实AES解密const CryptoJS = require('crypto-js'); const AesDecode = function (str, key, iv) {let pkey = CryptoJS.enc.Utf8.parse(key);let piv = CryptoJS.enc.Utf8.parse(iv);let pt = CryptoJS.enc.Hex.parse(str);let stringify = CryptoJS.enc.Base64.stringify(pt)let decrypt = CryptoJS.AES.decrypt(stringify, pkey, {iv: piv, mode: CryptoJS.mode.CBC, padding: CryptoJS.pad.Pkcs7});let decryptedStr = decrypt.toString(CryptoJS.enc.Utf8);return decryptedStr.toString(); }ps:解密函数可能不同,参照网站的js脚本修改解密方式 -
线上测试
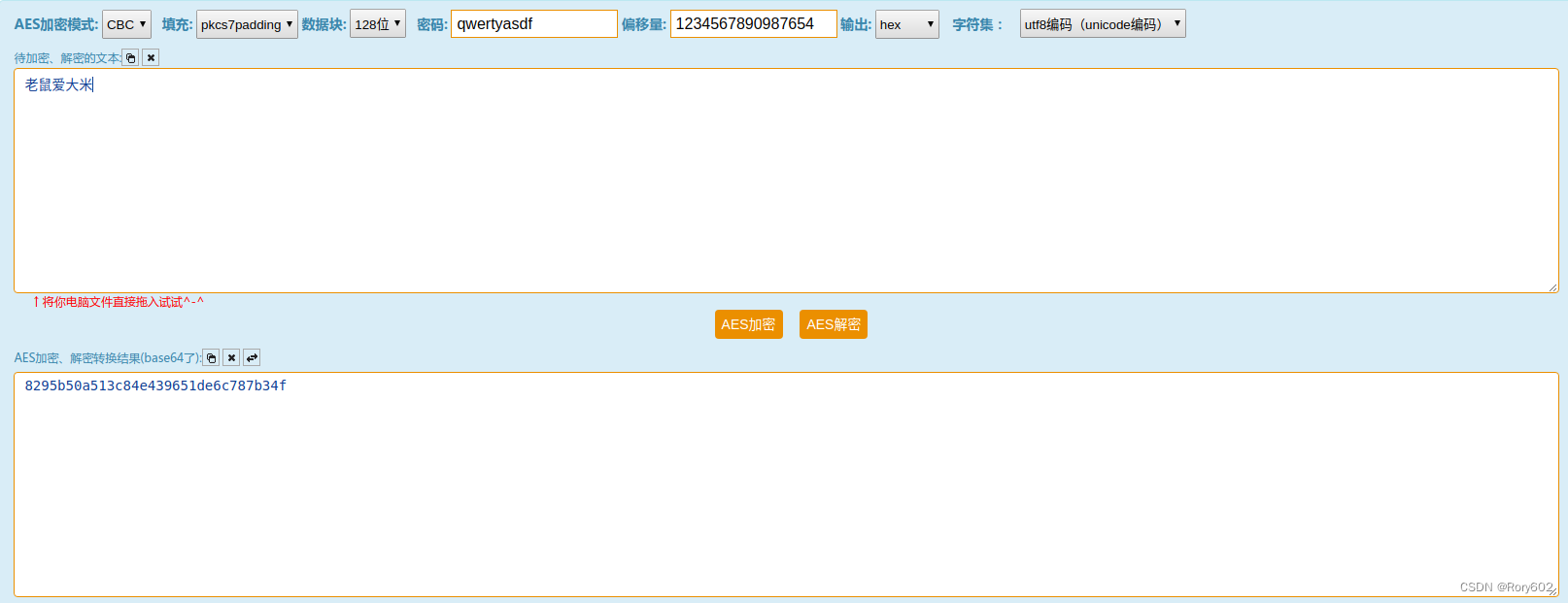
加密
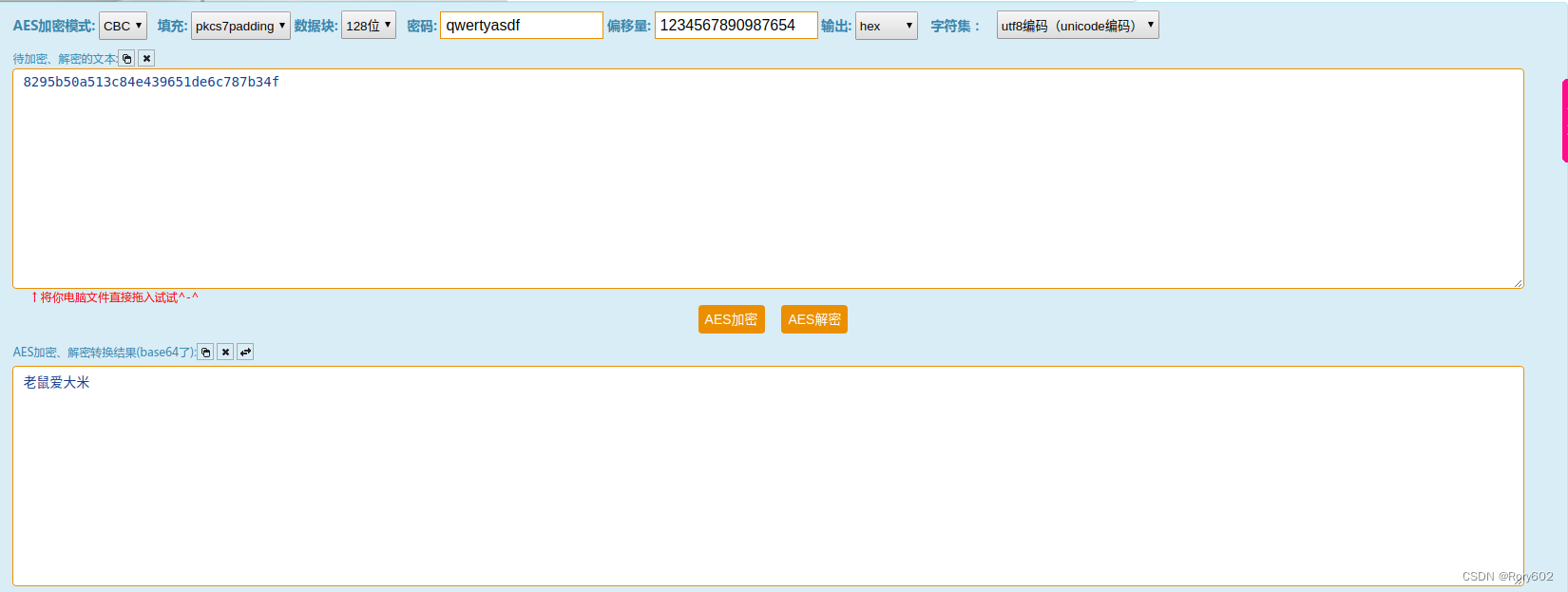
解密
(2)DES
(3)3DES
2.3 非对称加密 (可逆)
- 预备知识
RSA是一种公钥密码算法,RSA的密文是对代表了明文的数字的E次方求mod N的结果。换句话说,就是将明文和自己做E次乘方,然后将其结果除以N求余数,这个余数就是密文。其次是解决公私钥格式问题,网上查了一下,pkcs1和pkcs8的格式,两种格式的公私钥只是算法和填充方式不一样,那么公私钥加解密的原理应该以一样的。而且两个类型的可以互转。 - 代码测试:
安装jsencrypt
npm install jsencrypt
import JSEncrypt from 'jsencrypt'let priKey = '-----BEGIN RSA PRIVATE KEY-----MIICXQIBAAKBgQDvupVIIoSGBwdLXqP/ox0YYr1pj7ZmadC7i0mujqzIjpBh/NCJmZWtb4rmZyN18PPcctxIbyndJQ//BrUnFc4v0F4fjciHBuwSBAtaMBjoyj2CBiijHK6H96+cHv+AiudD0Vf3Ij0T7BaLZJZ/Ss3M25mRuT5cYN09M8Bt34Dv2wIDAQABAoGAVJQNqx+Shf7g0fSYA882qq3biezMO6HFpQVlf5KS30d9JTUfFgz7w+8AoH1vA2N5hiN4GI4vxPgYhq+FJj8JOSKAcmaGYnPKUd41yI/07tHMxNuXngJW0AyjhFFloEwp620VZGMzdPqkUMG5JvIViYoXc5yb1bE55l0TOUHUK/ECQQD9BYx4KqlNs9VKdrBla79iqjlgAff8nK542g/pIeKTcin/ARQRxVue/ABHyNnaJY+Ji7fpRACg3u2ECklur1DlAkEA8oz6X2l2xt+lK2bXCJhQ8dI68DGAQZBIwAHNQfTkppZXuTg/EErPo6XgXT3cletQ6+rvF3Dd2lk8loRQ5JzxvwJAdUIxCy+aLqx82HmQ3i/FDlCdLmU7LBLguJk2bnCJtJNf6xHw3xt7jn5zEtF+RJ7Lmo7puG0PbX5izKKHzYfqEQJBALTZGuHDQBW+sWewEUtOTqRP7TQkpI2+KBBKB6JTF52CYbwvzQ23yiQpzSWYt31s7HRLQqRGupRQjxVnaO1ce/8CQQCy65L/c+kqTF3zqrnoaKlScz6D877fsR1MQO3OJdCPkJdKTaGVrtKMazBBp0CN9Z98SJxvqIFizpesQnb+Daq2-----END RSA PRIVATE KEY-----'
let pubKey = '-----BEGIN PUBLIC KEY-----MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDvupVIIoSGBwdLXqP/ox0YYr1pj7ZmadC7i0mujqzIjpBh/NCJmZWtb4rmZyN18PPcctxIbyndJQ//BrUnFc4v0F4fjciHBuwSBAtaMBjoyj2CBiijHK6H96+cHv+AiudD0Vf3Ij0T7BaLZJZ/Ss3M25mRuT5cYN09M8Bt34Dv2wIDAQAB-----END PUBLIC KEY-----'
let RSA = {//使用公钥加密jiami(str) {let encrypt = new JSEncrypt();encrypt.setPublicKey(pubKey);let encrypted = encrypt.encrypt(str);return encryptedconsole.log('加密后数据:%o', encrypted);},jiemi(str) {//使用私钥解密let decrypt = new JSEncrypt();decrypt.setPrivateKey(priKey);let uncrypted = decrypt.decrypt(str);return uncrypted;console.log('解密后数据:%o', uncrypted); // 张三}
}
export default RSA;//使用, 公钥私钥可以通过命令行生成
import Rsa from '@/utils/rsa.js';
let message = '要加密的内容';
let str=Rsa.jiami(message);
console.log(str)
console.log(str,Rsa.jiemi(str));
- 线上测试
RSA,RSA2公钥私钥加密解密
3、常见JS混淆
- eval
- 混淆AA和OO
- 混淆JJ
- 混淆FuckJS
四、Webpack
1、什么是 chunk-vendors.js 文件?
chunk-vendors.js,顾名思义,是所有不属于您自己,而是来自其他方的模块的捆绑包 。它们被称为第三方模块,或 vendor 模块。通常,它意味着(仅和)来自您项目的 /node_modules 目录的所有模块。在 webpack 3 中,你必须自己做,你必须做一些样板文件才能拥有至少 2 个 block :一个用于您自己的代码,一个用于 /node_modules中的模块目录。
在 webpack 4 中,这很简单:你使用 optimization.splitChunks默认的 options:
module.exports = {//...optimization: {splitChunks: {chunks: 'async',minSize: 30000,maxSize: 0,minChunks: 1,maxAsyncRequests: 5,maxInitialRequests: 3,automaticNameDelimiter: '~',name: true,cacheGroups: {vendors: {test: /[\\/]node_modules[\\/]/, // this is what you are looking forpriority: -10},default: {minChunks: 2,priority: -20,reuseExistingChunk: true}}}}};
参考资料:
JS逆向之Webpack(一)
网页爬虫之WebPack模块化解密(JS逆向)
爬虫从入门到精通(13) | 了解webpack
五、Hook
- Fidder
- 油猴浏览器插件
六、动态js
- 动态js断点无法生效
- 格式:filename.js?=1666896541 样式
- 需要Fiddler进行本地文件替换
七、补头
- windows
- document
八、Debugger消除
- breakpoint处设置为False
- 将调起Debugger的方法设置为空
- 计时器定时调起时,将setInterval方法设置为空,
不是定时器定义位置,是定时器调用其他方法的位置。
九、sojson
- 通过正则,防止代码格式化
十、Charles
- Charles微信小程序抓包(详解)
- 破解
十一、AST
- js安全之ast混淆
- 在线ast解析工具(astexplorer)
- What is Babel?
- JS解混淆-AST还原案例
- 利用AST对抗js混淆(一) 基础知识
- 爬虫, 反爬虫, JS 逆向, 安卓逆向, AST
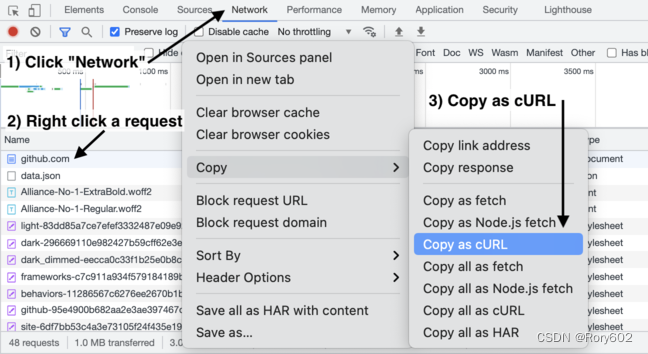
十二、工具cURL转化为代码
Convert curl commands to Python, JavaScript and more
参考资料
https://www.jianshu.com/p/de3e0ed0c26b
https://blog.csdn.net/holmes369/article/details/104477183/
https://github.com/scrapy/scrapy/blob/master/docs/topics/architecture.rst
https://www.jianshu.com/p/8824623b551c
https://blog.csdn.net/zhaoyanjun6/article/details/120285594
https://www.coder.work/article/6855114
https://blog.csdn.net/qq_41293573/article/details/122697084
https://blog.csdn.net/XKFC1/article/details/125220301
https://blog.csdn.net/weixin_43694639/article/details/88723280