MapReduce工作原理及基础编程(代码见文章后半部分)
JunLeon——go big or go home

目录
MapReduce工作原理及基础编程(代码见文章后半部分)
一、MapReduce概述
1、什么是MapReduce?
2、WordCount案例解析MapReduce计算过程
(1)运行hadoop自带的样例程序
(2)MapReduce工作过程
3、Shuffle过程详解
二、MapReduce编程基础
1、Hadoop数据类型
2、数据输入格式InputFormat
3、输入数据分块InputSplit和数据记录读入RecordReader
4、数据输出格式OutputFormat
5、数据记录输出类RecordWriter
6、Mapper类
7、Reduce类
三、MapReduce项目案例
1、经典案例——WordCount
2、计算考试平均成绩
3、网站日志分析
前言:
Google于2003年在SOSP上发表了《The Google File System》,于2004年在OSDI上发表了《MapReduce: Simplified Data Processing on Large Clusters》,于2006年在OSDI上发表了《Bigtable: A Distributed Storage System for Structured Data》。这三篇论文为大数据及云计算的发展奠定了基础。
一、MapReduce概述
1、什么是MapReduce?
MapReduce是一个分布式、并行处理的计算框架。
MapReduce 把任务分为 Map 阶段和 Reduce 阶段。开发人员使用存储在HDFS 中数据(可实现快速存储),编写 Hadoop 的 MapReduce 任务。由于 MapReduce工作原理的特性, Hadoop 能以并行的方式访问数据,从而实现快速访问数据。
表1 map函数和rudece函数
| 函数 | 输入 | 输出 | 说明 |
| map | <k1,v1> <0,helle world> <12,hello hadoop> | List<k2,v2> <hello,1> <world,1> <hello,1> <hhadoop,1> | 将获取到的数据集进一步解析成<key,value>,通过Map函数计算生成中间结果,进过shuffle处理后作为reduce的输入 |
| reduce | <k2,List(v2)> <hadoop,1> <hello,{1,1}> <world,1> | <k3,v3> <hadoop,1> <hello,2> <world,1> | reduce得到map输出的中间结果,合并计算将最终结果输出HDFS,其中List(v2),指同一k2的value |
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
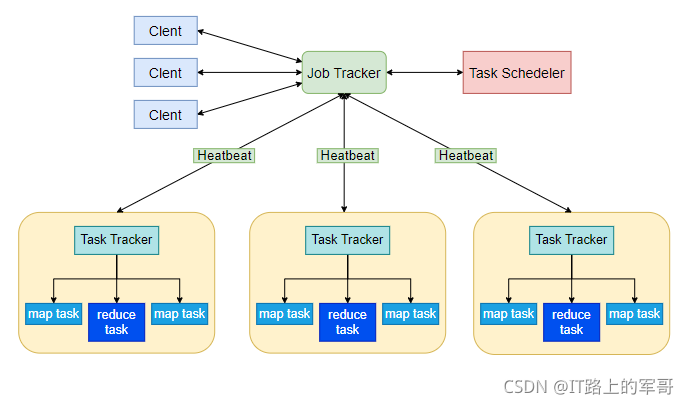
1)Client
用户编写的MapReduce程序通过Client提交到JobTracker端 用户可通过Client提供的一些接口查看作业运行状态。
2)JobTracker
JobTracker负责资源监控和作业调度 JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点 JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源。
3)TaskTracker
TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等) TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用。
4)Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动。
MapReduce各个执行阶段:
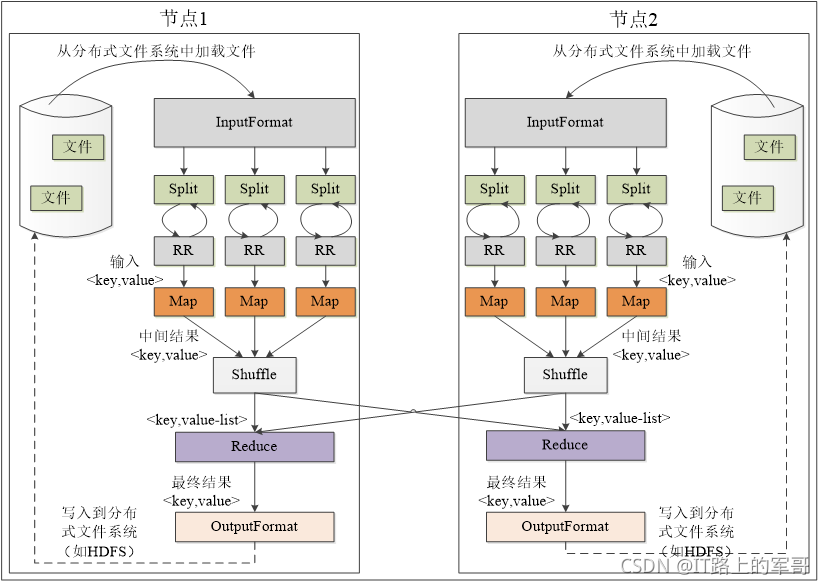
MapReduce应用程序执行过程:
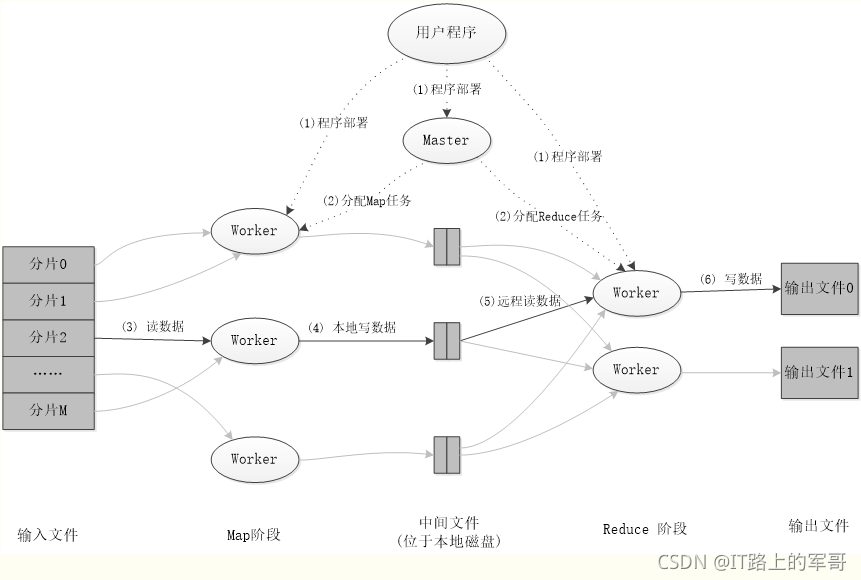
可以参考大佬黎先生的博客:MapReduce基本原理及应用 - 黎先生 - 博客园
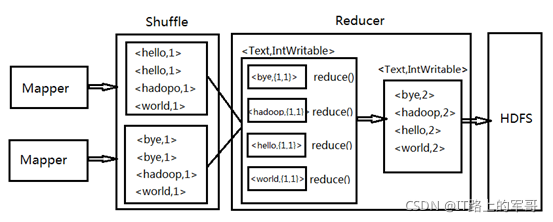
2、WordCount案例解析MapReduce计算过程
(1)运行hadoop自带的样例程序
WordCount案例是一个经典案例,是Hadoop自带的样例程序。
作用:统计单词数量(出现的次数)
应用:求和、求平均值、求最值,
jar包存储在$HADOOP_HOME/share/hadoop/mapreduce/:
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
例如:

步骤:
1.在本地创建一个文件

输入以下内容:

2.上传到HDFS指定目录
在HDFS中创建指定文件:

上传文件:

3.使用hadoop jar命令运行jar程序,统计单词数量

4.输出结果
执行部分过程:

查看生成的文件:

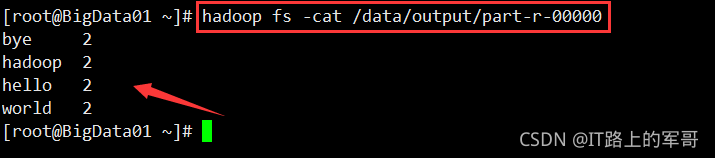
查看计算结果:
(2)MapReduce工作过程
工作流程是Input从HDFS里面并行读取文本中的内容,经过MapReduce模型,最终把分析出来的结果用Output封装,持久化到HDFS中。
1.Mapper工作过程:

附上Mapper阶段代码:
public static class WorldCount_Mapper extends Mapper<LongWritable, Text, Text, IntWritable>{@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)throws IOException, InterruptedException {System.out.println("split:<" + key + ","+ value + ">" );String[] strs = value.toString().split(" ");for (String string : strs) {System.out.println("map:<" + key + ","+ value + ">" );context.write(new Text(string),new IntWritable(1));}}}
KEYIN--LongWritable:输入key类型,记录数据分片的偏移位置
VALUEIN—Text:输入的value类型,对应分片中的文本数据
KEYOUT--Text:输出的key类型,对应map方法中计算结果的key值
VALUEOUT—IntWritable:输出的value类型,对应map方法中计算结果的value值
Mapper类从分片后传出的上下文中接收数据,数据以类型<LongWritable,Text>的键值对接收过来,通过重写map方法默认一行一行的读取数据并且以<key,value>形式进行遍历赋值。
2.Reducer工作过程:
附上Reducer阶段代码:
public static class WorldCount_Reducer extends Reducer<Text, IntWritable, Text, IntWritable>{@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int index = 0;for (IntWritable intWritable : values) {System.out.println("reduce:<" + key + ","+ intWritable + ">" );index += intWritable.get();}context.write(key,new IntWritable(index));}}
Reducer任务继承Reducer类,主要接收的数据来自Map任务的输出,中间经过Shuffle分区、排序、分组,最终以<key,value>形式输出给用户。
Job提交代码:
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Job job = Job.getInstance();job.setJarByClass(WorldCount.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);job.setMapperClass(WorldCount_Mapper.class);job.setReducerClass(WorldCount_Reducer.class);FileInputFormat.addInputPath(job,new Path("hdfs://192.168.100.123:8020/input"));FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.100.123:8020/output"));job.waitForCompletion(true);}
JobClients是用户提交的作业与ResourceManager交互的主要接口,JobClients提供提交作业、追踪进程、访问子任务的日志记录、获取的MapReduce集群状态信息等功能。
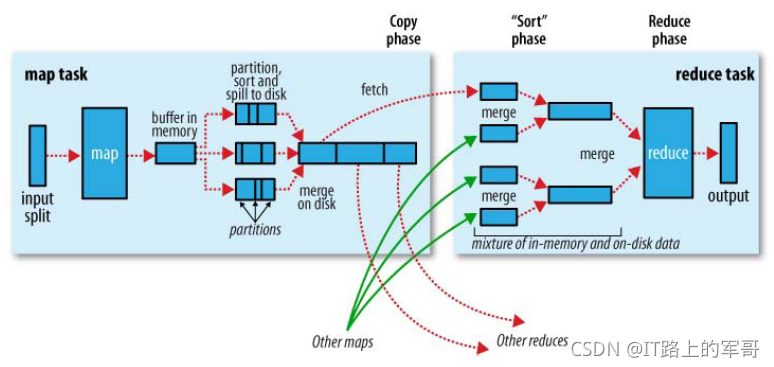
3、Shuffle过程详解
Hadoop运行机制中,将map输出进行分区、分组、排序、和合并等处理后作为输入传给Reducer的过程,称为shuffle过程。
shuffle阶段又可以分为Map端的shuffle和Reduce端的shuffle。
一、Map端的shuffle
写磁盘:Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
分区、分组、排序:在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个分区(partition)中的数据再按key来排序。partition的目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。
文件合并:最后,每个Map任务可能产生多个溢写文件(spill file),在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个已经分区和排序的输出文件。至此,Map的shuffle过程就结束了。
压缩:在shuffle过程中如果压缩被启用,在map传出数据传入Reduce之前可执行压缩,默认情况下压缩是关闭的,可以将mapred.compress.map.output设置为true可实现压缩。
二、Reduce端的shuffle
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
接下来就是排序(sort)阶段,也成为合并(merge)阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。最终在Reduce端生成一个较大的文件作为Reduce的输入。MapReduce编程接口
二、MapReduce编程基础
1、Hadoop数据类型
Hadoop数据包括:BooleanWritable、ByteWritable、DoubleWritable、FloatWritale、IntWritable、LongWritable、Text、NullWritable等,它们实现了WritableComparable接口。其中Text表示使用UTF8格式存储的文本、NullWritable类型是当(key,value)中的key或value为空时使用。
表2 Hadoop Writable与Java数据类型参照表
| Java基本类型 | Writable封装类 | 类型 | 序列化后的长度为 |
| boolean | BooleanWritable | 布尔型 | 1 |
| byte | ByteWritable | 字节型 | 1 |
| double | DoubleWritable | 双精度浮点型 | 8 |
| float | FloatWritable | 单精度浮点型 | 8 |
| int | IntWritable VIntWritable | 整型 | 4 1-5 |
| long | LongWritable | 长整型 | 8 |
| short | ShortWritable | 短整型 | 2 |
| null | NullWritable | 空值 | 0 |
| Text | 文本类型 |
除了上述Hadoop类型外,用户还可以自定义新的数据类型。用户自定义数据类型需要实现Writable接口,但如果需要作为主键key使用或需要比较大小时,则需要实现WritableComparable接口。
2、数据输入格式InputFormat
抽象类InputFormat<K,V>有三个直接子类:
FileInputFormat<K,V>、DBInputFormat<T>、DelegatingInputFormat<K,V>
其中,文件输入格式类FileInputFormat<K,V>类有几个子类:
TextInputFormat、KeyValueInputFormat、SequenceFileInputFormat<K,V>、NlineInputFormat、CombineFileInputFormat<K,V>
序列化文件输入类SequenceFileInputFormat<K,V>有几个子类:
SequenceFileAsBinaryInputFormat、SequenceFileAsTextInputFormat、SequenceFileInputFilter<K,V>
数据库输入格式类DBInputFormat<T>的直接子类是:DataDriverDBInputFormat<T>,而这个子类又派生子类:OracleDataDriverDBInputFormat<T>
表3 常用数据输入格式类
| InputFormat类 | 描述 | 键(Key) | 值(Value) |
| TextInputFormat | 默认输入格式,读取文本文件的行 | 当前行的偏移量 | 当前行内容 |
| KeyValueTextInputFormat | 将行解析成键值对 | 行内首个制表符的内容 | 行内其余内容 |
| SequenceFileInputFormat | 专用于高性能的二进制格式 | 用户定义 | 用户定义 |
3、输入数据分块InputSplit和数据记录读入RecordReader
编程时由用户选择的数据输入格式InputFormat类型来自动决定数据分块InputSplit和数据记录RecordReader类型。一个InputSplit将单独作为一个Mapper的输入,即作业的Mapper数量是由InputSplit个数决定的。
表4 数据输出格式类对应的Reader类型
| InputFormat类 | RecordReader类 | 描述 |
| TextInputFormat | LineRecordReader | 读取文本文件的行 |
| KeyValueTextInputFormat | KeyValueLineRecordReader | 读取行并将行解析为键值对 |
| SequenceFileInputFormat | SequenceFileRecordReader | 用户定义的格式产生键与值 |
| DBInputFormat | DBRecordReader | 仅适合读取少量数据记录,不适合数据仓库联机数据分析大量数据的读取处理 |
4、数据输出格式OutputFormat
抽象类OutputFormat<K,V>有四个直接子类:
FileOutputFormat<K,V>、DBOutputFormat<K,V>、NullOutputFormat<K,V>、FilterOutputFormat<K,V>
FileOutputFormat<K,V>有两个直接子类:
TextOutputFormat<K,V>、SequenceFileOutputFormat<K,V>
SequenceFileOutputFormat<K,V>有直接子类:SequenceFileAsBinaryOutputFormat
FilterOutputFormat<K,V>有直接子类:LazyOutputFormat<K,V>
5、数据记录输出类RecordWriter
数据记录输出类RecordWriter是一个抽象类。
表5 数据输出格式类对应的数据记录Writer类型
| OutputFormat类 | RecordWriter类 | 描述 |
| TextOutputFormat | LineRecordWriter | 将结果数据以“key + \t + value”形式输出到文本文件中 |
| SequenceFileOutputFormat | SequenceFileRecordWriter | 用户定义的格式产生键与值 |
| DBOutputFormat | DBRecordWriter | 将结果写入到一个数据库表中 |
| FilterOutputFormat | FilterRecordWriter | 对应于过滤器输出模式的数据记录模式,只将过滤器的结果输出到文件中 |
6、Mapper类
Mapper类是一个抽象类,位于hadoop-mapreduce-client-core-2.x.x.jar中,其完整类名是:org.apache.hadoop.mapreduce.Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>,需派生子类使用,在子类中重写map方法:map(KEYIN key,VALUEIN value,Mapper.Context context)对出入的数据分块每个键值对调用一次。
7、Reduce类
Reduce类是一个抽象类,位于hadoop-mapreduce-client-core-2.x.x.jar中,其完整类名是:org.apache.hadoop.mapreduce.Reduce<KEYIN,VALUEIN,KEYOUT,VALUEOUT>,需派生子类使用,在子类中重写reduce方法:reduce(KEYIN key,Inerable <VALUEIN> value,Reducer.Context context)对出入的数据分块每个键值对调用一次。
三、MapReduce项目案例
1、经典案例——WordCount
代码演示:
package hadoop.mapreduce;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class MyWordCount {/** KEYIN:是map阶段输入的key(偏移量)* VALUEIN:是map阶段输入的value(文本文件的内容--行)* KEYOUT:是map阶段输出的key(单词)* VALUEOUT:是map阶段输出的value(单词的计数--1)* * Java基本数据类型:* int、short、long、double、float、char、boolean、byte* hadoop数据类型* IntWritable、ShortWritable、LongWritable、DoubleWritable、FloatWritable* ByteWritable、BooleanWritable、NullWritable、Text* Text:使用utf8编码的文本类型*/public static class WordCount_Mapper extends Mapper<LongWritable, Text, Text, IntWritable>{@Override //方法的重写protected void map(LongWritable key, Text value, Mapper<LongWritable, Text,Text, IntWritable>.Context context)throws IOException, InterruptedException {String[] line = value.toString().split(" "); //将获取到的数据以空格进行切分成一个个单词for (String word : line) { //遍历单词的数组context.write(new Text(word), new IntWritable(1)); //单词进行计数,将中间结果写入context}} }/** KEYIN:reduce阶段输入的key(单词)* VALUEIN:reduce阶段输入的value(单词的计数)* KEYOUT:reduce阶段输出的key(单词)* VALUEOUT:reduce阶段输出的value(单词计数的总和)* * reduce方法中做以下修改:* 将Text arg0改为Text key* 将Iterable<IntWritable> arg1改为Iterable<IntWritable> value* 将Context arg2修改为Context context*/public static class WordCount_Reducer extends Reducer<Text, IntWritable, Text, IntWritable>{@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, IntWritable>.Context context)throws IOException, InterruptedException {int sum = 0; //创建一个变量,和for (IntWritable intWritable : values) { //遍历相同key单词的计数sum += intWritable.get(); //将相同key单词的计数进行累加}context.write(key, new IntWritable(sum)); //将计算的结果写入context}}//提交工作public static void main(String[] args) throws Exception {String inPath= "hdfs://192.168.182.10:8020/input.txt";String outPath = "hdfs://192.168.182.10:8020/output/";Configuration conf = new Configuration();Job job = Job.getInstance(); //创建Job对象jobFileSystem fs = FileSystem.get(conf);if (fs.exists(new Path(outPath))) {fs.delete(new Path(outPath), true);}job.setJarByClass(MyWordCount.class); //设置运行的主类MyWordCountjob.setMapperClass(WordCount_Mapper.class); //设置Mapper的主类job.setReducerClass(WordCount_Reducer.class); //设置Reduce的主类job.setOutputKeyClass(Text.class); //设置输出key的类型job.setOutputValueClass(IntWritable.class); //设置输出value的类型//设置文件的输入路径(根据自己的IP和HDFS地址设置)FileInputFormat.addInputPath(job, new Path(inPath)); //设置计算结果的输出路径(根据自己的IP和HDFS地址设置)FileOutputFormat.setOutputPath(job, new Path(outPath));System.exit((job.waitForCompletion(true)?0:1)); //提交任务并等待任务完成}
}打包上传虚拟机:
步骤:
右键单击项目名 --> 选择 Export --> Java --> JAR file --> Browse...选择存放路径 --> 文件名
命名为wordcount.jar,将打包好的jar包上传到虚拟机中
运行代码:
在本地创建一个文件input.txt
vi input.txt添加内容:
hello world
hello hadoop
bye world
bye hadoop上传到DHFS中:
hadoop fs -put input.txt /使用jar命令执行项目:
hadoop jar wordcount.jar hadoop.mapreduce.MyWordCount如下图:

查看结果:

2、计算考试平均成绩
代码演示:
Mapper类
package hadoop.mapreduce;import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;/** 编写CourseScoreAverageMapper继承Mapper类*/
public class CourseScoreAverageMapper extends Mapper<LongWritable, Text, Text, IntWritable>{@Override //方法的重写protected void map(LongWritable key, Text value, Mapper<LongWritable, Text,Text, IntWritable>.Context context)throws IOException, InterruptedException {String line = new String(value.getBytes(),0,value.getLength(),"UTF8"); //转换中文编码Counter countPrint = context.getCounter("CourseScoreAverageMapper.Map 输出传递Value:", line); //通过计数器输出变量值countPrint.increment(1L); //将计数器加一StringTokenizer tokenArticle = new StringTokenizer(line,"\n"); //将输入的数据按行“\n”进行分割while(tokenArticle.hasMoreElements()) {StringTokenizer tokenLine = new StringTokenizer(tokenArticle.nextToken()); //每行按空格划分String strName = tokenLine.nextToken(); //按空格划分出学生姓名String strScore = tokenLine.nextToken(); //按空格划分出学生成绩Text name = new Text(strName); //转换为Text类型int scoreInt = Integer.parseInt(strScore); //转换为int类型context.write(name, new IntWritable(scoreInt)); //将中间结果写入contextcountPrint = context.getCounter("CourseScoreAverageMapper.Map中循环输出信息:", "<key,value>:<"+strName+","+strScore+">"); //输出信息countPrint.increment(1L); //将计数器加一}}
}Reducer类
package hadoop.mapreduce;import java.io.IOException;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Reducer;/** 编写CourseScoreAverageReducer继承Reduce类*/
public class CourseScoreAverageReducer extends Reducer<Text, IntWritable, Text, IntWritable>{@Override //重写reduce方法protected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, IntWritable>.Context context)throws IOException, InterruptedException {int sum = 0; //总分int count = 0; //科目数for (IntWritable val : values) { //遍历相同key的分数sum += val.get(); //将相同key的分数进行累加count++; //计算科目数}int average = (int)sum/count; //计算平均分context.write(key, new IntWritable(average)); //将计算的结果写入contextCounter countPrint = context.getCounter("CourseScoreAverageReducer.Reducer中输出信息:", "<key,value>:<"+key.toString()+","+average+">"); //输出信息countPrint.increment(1L); //计数器加1}
}
Driver类
package hadoop.mapreduce;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class CourseScoreDriver {public static void main(String[] args) throws Exception {Configuration conf = new Configuration(); //获取配置文件Job job = Job.getInstance(conf,"CourseScoreAverage"); //创建Job对象jobString[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); //获取命令行参数if(otherArgs.length<2) { System.err.print("Usage:hadoop jar MyAverage.jar <in> <out> ");System.err.print("hadoop jar MyAverage.jar hadoop.mapreduce.CourseScoreDriver <in> <out>");System.exit(2);}else {for (int i = 0; i < otherArgs.length-1; i++) { //设置文件输入路径if(!("hadoop.mapreduce.CourseScoreDriver".equalsIgnoreCase(otherArgs[i]))) { //排除hadoop.mapreduce.CourseScoreDriver这个参数FileInputFormat.addInputPath(job, new Path(otherArgs[i]));System.out.println("参数IN:"+otherArgs[i]);}}//设置文件输出路径FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-1])); //设置输出路径System.out.println("参数OUT:"+otherArgs[otherArgs.length-1]);}FileSystem hdfs = FileSystem.get(conf); //创建文件系统if(hdfs.exists(new Path(otherArgs[otherArgs.length-1]))) { //如果已经存在该路径,则删除该路径hdfs.delete(new Path(otherArgs[otherArgs.length-1]), true);}job.setJarByClass(CourseScoreDriver.class); //设置运行的主类CourseScoreDriverjob.setMapperClass(CourseScoreAverageMapper.class); //设置Mapper的主类job.setCombinerClass(CourseScoreAverageReducer.class); //设置Combiner的主类job.setReducerClass(CourseScoreAverageReducer.class); //设置Reduce的主类job.setOutputKeyClass(Text.class); //设置输出key的类型job.setOutputValueClass(IntWritable.class); //设置输出value的类型job.setInputFormatClass(TextInputFormat.class); //设置输入格式job.setOutputFormatClass(TextOutputFormat.class); //设置输出格式System.exit((job.waitForCompletion(true)?0:1)); //提交任务并等待任务完成System.out.println("Job Finished!");}
}
打包上传虚拟机:
步骤:
右键单击项目名 --> 选择 Export --> Java --> JAR file --> Browse...选择存放路径 --> 文件名
命名为average.jar , 将打包好的average.jar上传到虚拟机中
运行代码:
首先准备三个文件 Chinese.txt、Math.txt、English.txt,添加如下内容:
 将文件上传到HDFS的data目录下:
将文件上传到HDFS的data目录下:
hadoop fs -mkdir /data
hadoop fs -put Chinese.txt /data/
hadoop fs -put Math.txt /data/
hadoop fs -put English.txt /data/执行代码:
hadoop jar average.jar hadoop.mapreduce.CourseScoreDriver /data /data/output查看结果,如下图:
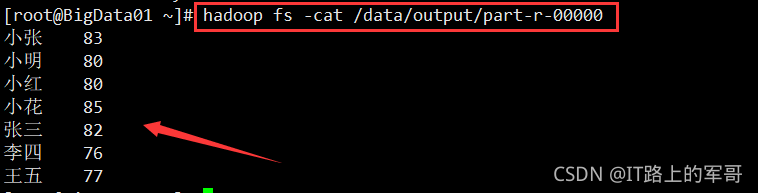
3、网站日志分析
代码演示:
打包上传虚拟机:
运行代码: