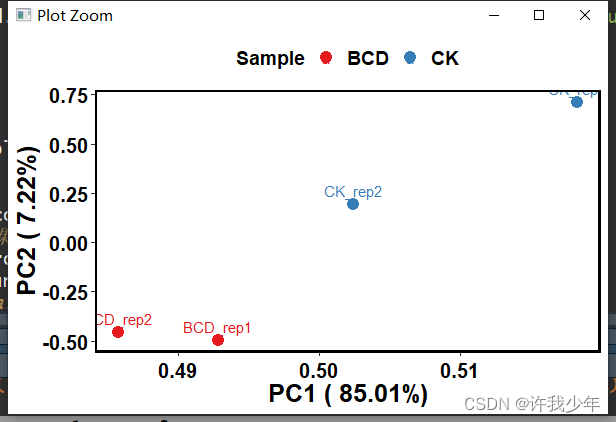
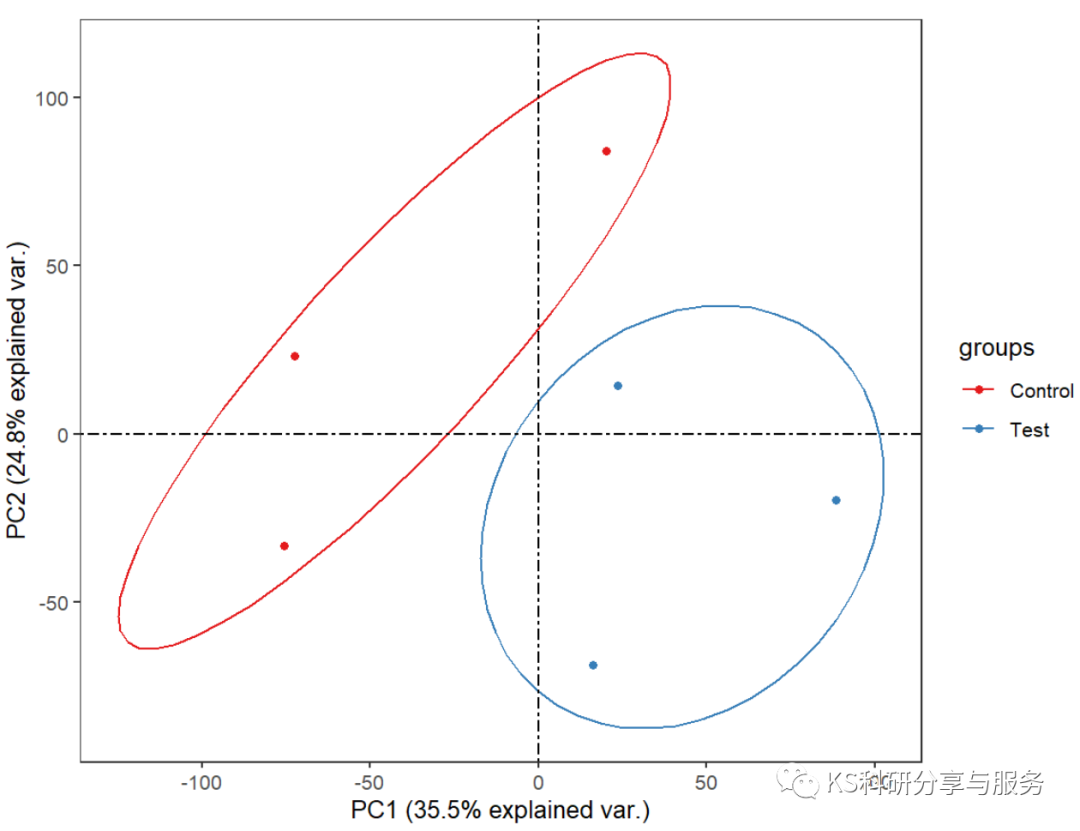
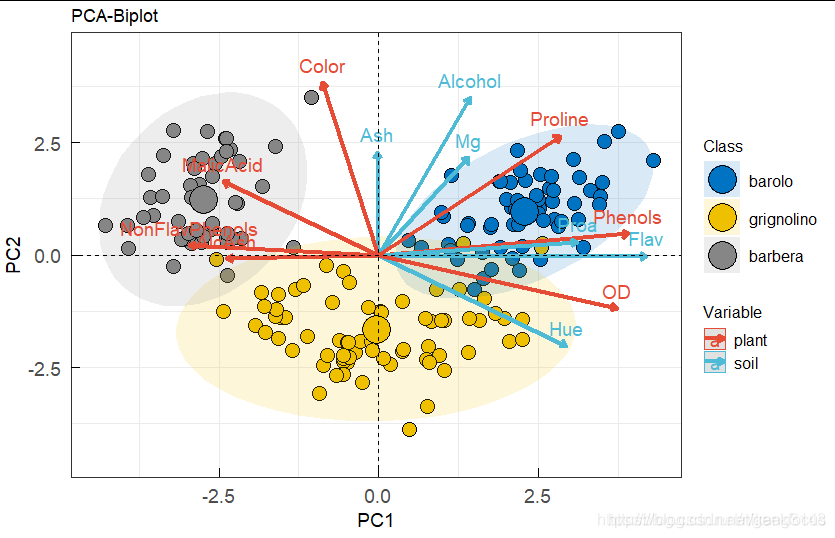
一 PCA分析法介绍
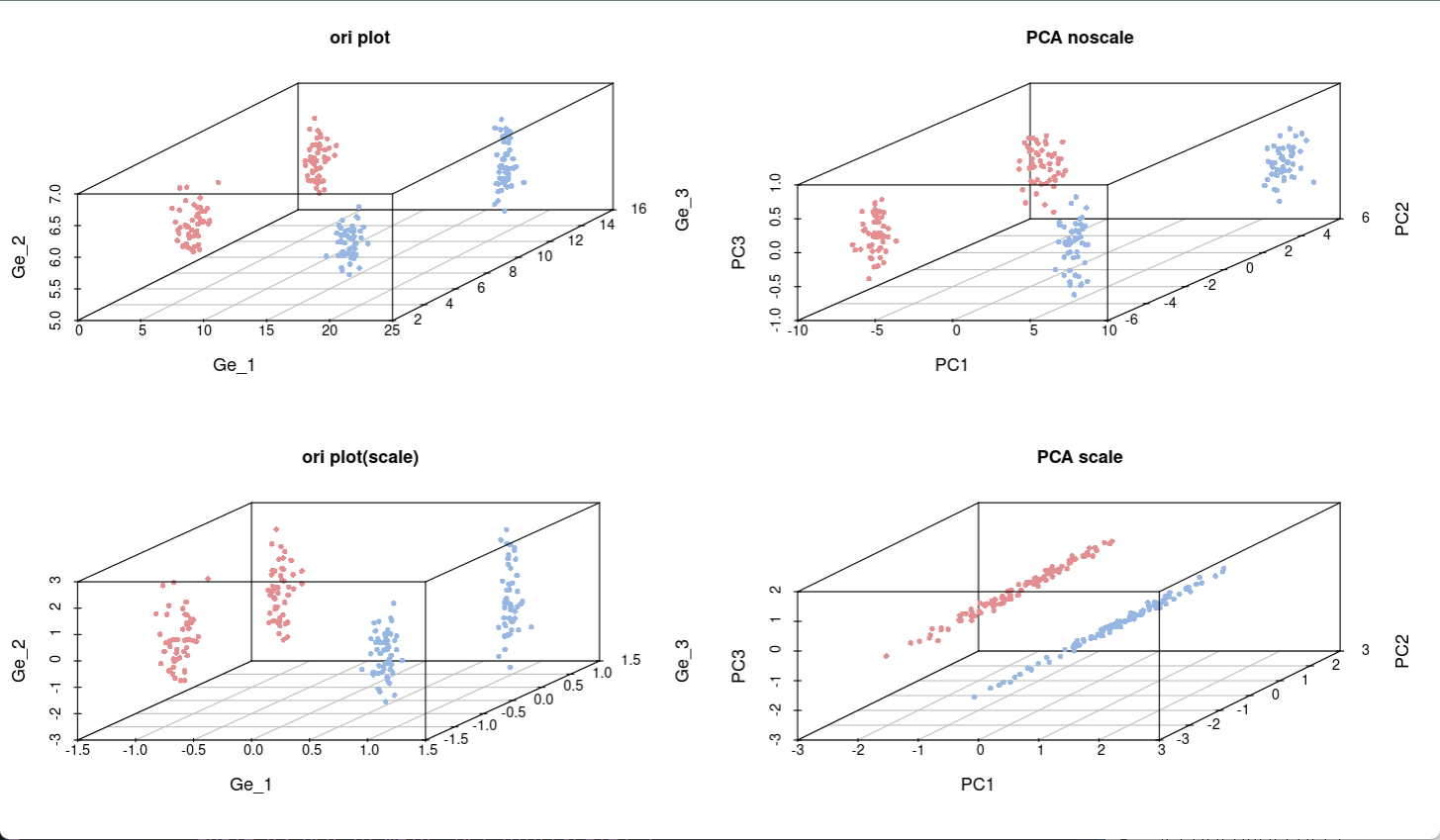
可以理解为是一种降维的思想,将M列数据降维成对应的N列数据,用主要的几个字段解释整体方差变异
也可以理解为一种低维度的映射,举例将三维的数据找到一个二维映射面,同时可以尽力解释出较多的信息来
举例如下图所示:

二 PCA分析法的基础步骤
1.对数据求平均值,即求取对应的均值u=E(X)
2.对特征数据进行去中心化处理,即X= X-E(X)=X-u
3.对去中心化处理的特征矩阵求取协方差矩阵COV(X)
4.对协方差矩阵求特征根和特征向量numta1,namuta2,numta3…及对应特征向量
5.求前K个对应大的特征向量
6.将原始M维去中心化的特征矩阵乘上由特征向量(按列组合)组成的矩阵,就可得到最终的结果N维
三 相关代码
3.1 手工计算对应的代码
#加载库
import numpy as np
import matplotlib.pyplot as plt#加载数据
def load_data(file_name, delim='\t'):fr = open(file_name)str_arr = [line.strip().split(delim) for line in fr.readlines()]dat_arr = [list(map(float,line)) for line in str_arr]return np.mat(dat_arr)#定义PCA方法
def pca(data_mat, topNfeat = 999999):# 求平均值mean_val = np.mean(data_mat, axis = 0)#去中心化mean_removed = mean_val - data_mat# 获取协方差矩阵cov_mat = np.cov(mean_removed, rowvar=0)# 获取特征根及特征向量eigen_vals, eigen_vecs = np.linalg.eig(cov_mat)# 特征根排序eigen_val_ind = np.argsort(eigen_vals)# 删除解释量小的特征根eigen_val_ind = eigen_val_ind[:-(topNfeat+1):-1]print(eigen_val_ind)# 由高到低排序red_eigen_vecs = eigen_vecs[:,eigen_val_ind]print(red_eigen_vecs)# l新维度的数据low_data_mat = mean_removed * red_eigen_vecs# 获取目标向量值recon_mat = (low_data_mat * red_eigen_vecs.T) + mean_valreturn low_data_mat, recon_mat# 主函数调用
if __name__ == '__main__':data_mat = load_data("data.txt")low_data_mat, recon_mat = pca(data_mat, 1)plt.figure()plt.scatter(data_mat[:,0].flatten().A[0], data_mat[:,1].flatten().A[0], marker='^', s = 90)plt.scatter(recon_mat[:,0].flatten().A[0], recon_mat[:,1].flatten().A[0], marker='o', s = 50, c = "red")plt.show()
3.2 机器学习PCA计算的代码
## 使用机器学习的内置函数计算,使用鸢尾花数据
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt#加载数据
iris = load_iris()
x = iris.keys()
data_x = iris.data
data_y = iris.target
#print(data_y,data_x)#PCA方法训练并求取新维度的数据
pca = PCA(n_components=2)
pca = pca.fit(data_x)
x_dr = pca.transform(data_x)#图形化显示
plt.scatter(x_dr[data_y==0,0],x_dr[data_y==0,1],c='red',label=iris.target_names[0])
plt.scatter(x_dr[data_y==1,0],x_dr[data_y==1,1],c='green',label=iris.target_names[1])
plt.scatter(x_dr[data_y==2,0],x_dr[data_y==2,1],c='blue',label=iris.target_names[2])
plt.legend
plt.title("iris dataset")
plt.show()
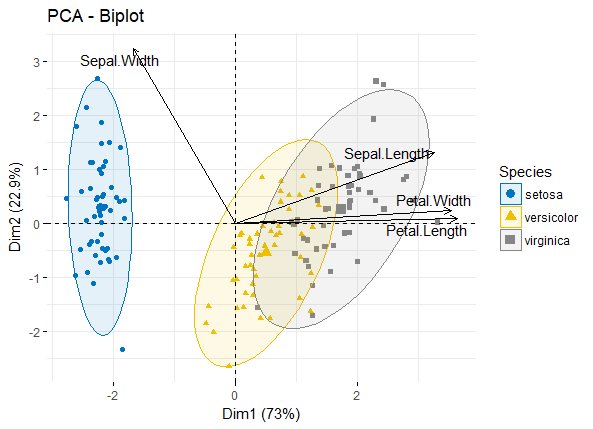
鸢尾花的二维显示效果: