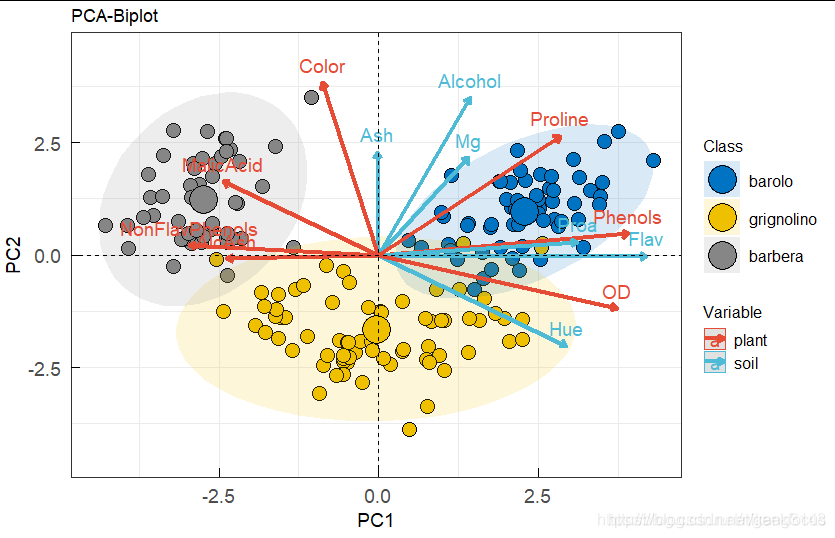
zhe
点击名片 关注我们
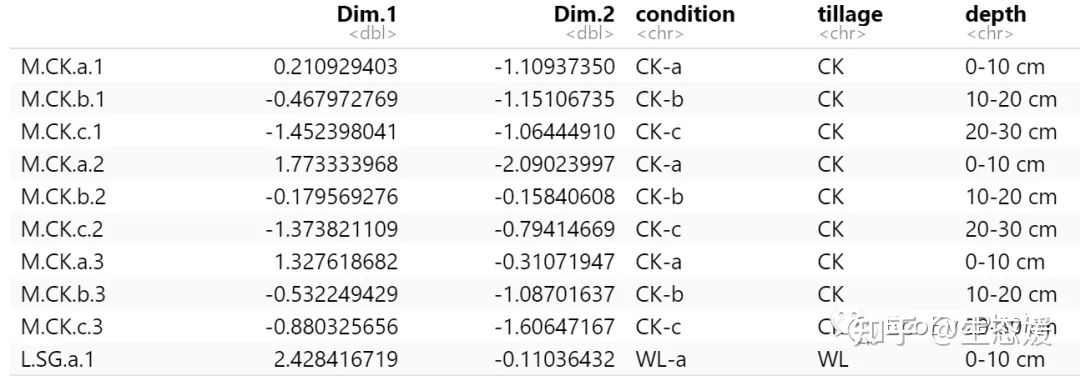
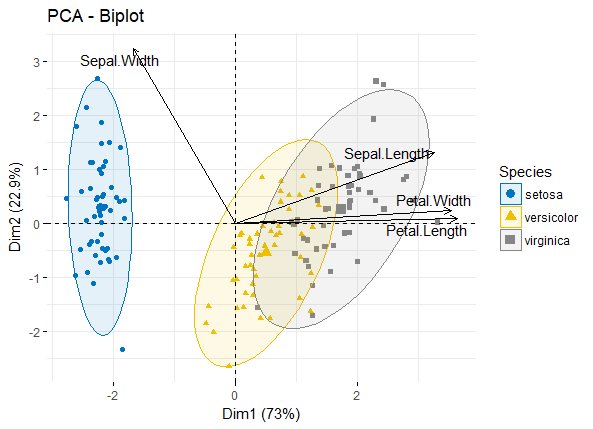
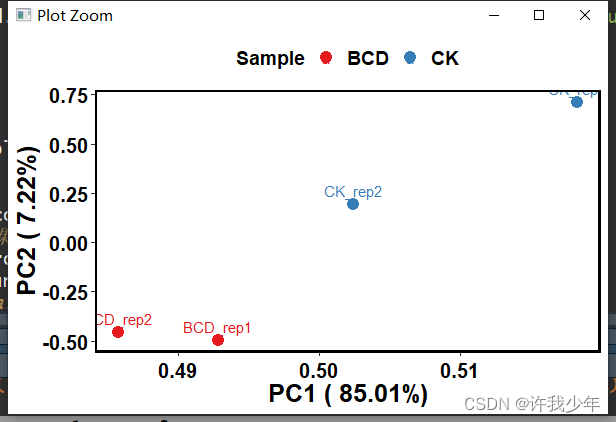
有师妹来咨询,怎样画类似于上图的双坐标轴PCA双序图。正好之前虽然PCA和RDA分析及绘图都写过教程,但是变量分析结果没有在图中显示,所以使用R统计绘图-环境因子相关性热图流程开始按图1整理环境因子数据,行为样品名称,列为环境因子名称和分组信息,共有11个环境变量,3个分组信息。
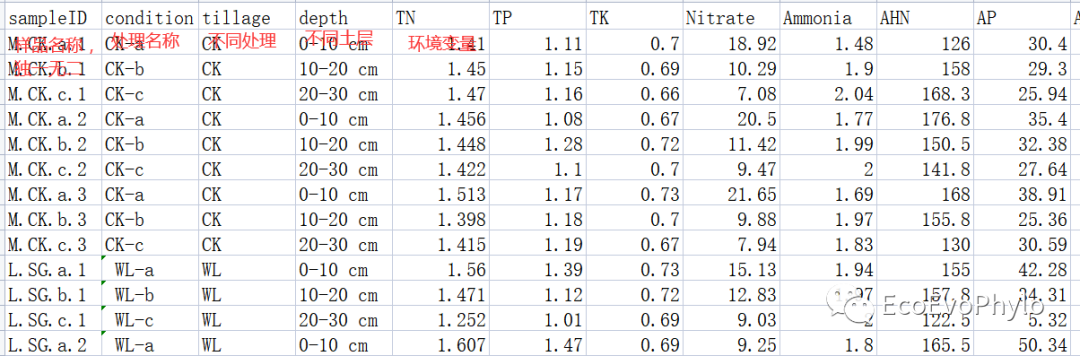
图1|环境因子及分组信息表,env.csv。行为样品名称,列为环境因子名称和分组信息,共有11个环境变量,3个分组信息。
一、 设置工作路径并调用R包
# 设置工作路径
#knitr::opts_knit$set(root.dir="D:\\EnvStat\\PCA")# 使用Rmarkdown进行程序运行
Sys.setlocale('LC_ALL','C') # Rmarkdown全局设置
setwd("D:\\EnvStat\\PCA")# 调用R包
library(vegan)
library(ggplot2)
library(scales)二、数据准备
options(stringsAsFactors=F)# R中环境变量设置,防止字符型变量转换为因子
# 读入环境因子数据表
ENV=read.csv("env.csv",header = T,row.names = 1,sep = ",",comment.char = "",stringsAsFactors = F,colClasses = c(rep("character",4),rep("numeric",11)))
head(ENV) # 查看数据前几行
#dim(ENV) # 查看数据行、列数
#str(ENV) # 查看数据表每列的数据形式三、PCA分析及绘图
3.1 PCA分析
使用vegan包进行PCA分析。
pca=rda(ENV[4:14],scale=T)
summary(pca)
图2|PCA分析结果。
3.2 提取绘图数据
提取样本与环境变量的前两个PC轴的数据,用于绘制双序图。
# 3.2.1 提取前两轴样本特征值
s.pca=data.frame(pca$CA$u[,1:2],ENV[1:3]) # 样本得分与分类变量形成数据框
s.pca # 用点表示样本特征值
summary(s.pca) # 描述统计# 3.2.2 提取前两轴变量特征值
e.pca=data.frame(pca$CA$v[,1:2])
e.pca # 用箭头表示变量特征值
summary(e.pca) # 描述统计# 3.2.3 计算轴标签
PC1 =round(pca$CA$eig[1]/sum(pca$CA$eig)*100,2) #第一轴标签
PC2 =round(pca$CA$eig[2]/sum(pca$CA$eig)*100,2) #第二轴标签
PC1 # 一个数值
PC2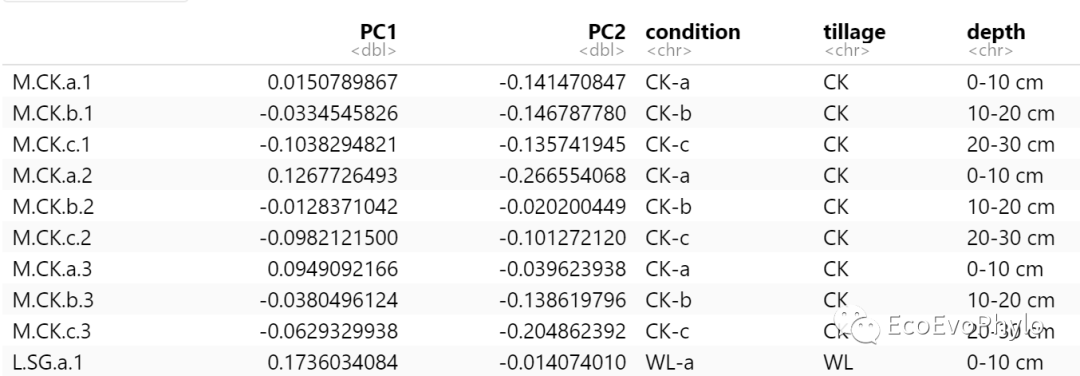
图3|样本前两轴特征值。
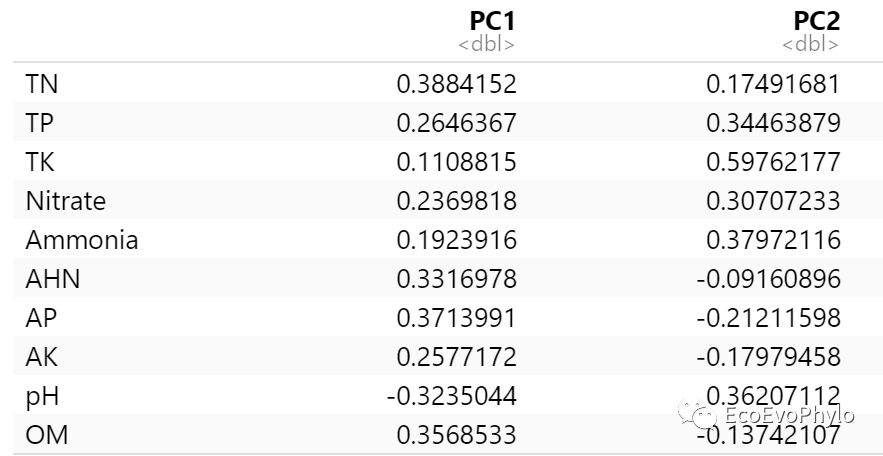
图4|环境变量前两轴特征值。
3.3 绘制样本与变量双序图
3.3.1 单坐标轴PCA双序图
使用点表示样本特征值,箭头表示环境变量特征值。
# 3.3.1 样本和环境变量共用一个坐标轴
p1 = ggplot(data=s.pca,aes(PC1,PC2))+geom_point(aes(color=tillage,fill=tillage,shape=depth),size=3)+scale_color_manual(values=c("red","blue","green","grey"))+scale_shape_manual(values =c(15,16,17))+stat_ellipse(aes(group=tillage,color=tillage),level = 0.95,linetype=2)+labs(title="PCA plot",x=paste("PC1",PC1," %"),y=paste("PC2",PC2," %"))+theme_bw()+theme(axis.title = element_text(family = "serif", face = "bold", size = 18,colour = "black"))+theme(axis.text = element_text(family = "serif", face = "bold", size = 16,color="black"))+theme(panel.grid=element_blank())+geom_hline(yintercept=0)+geom_vline(xintercept=0)+geom_segment(data=e.pca,aes(x=0,y=0,xend=e.pca[,1],yend=e.pca[,2]),size=1,colour="blue",arrow=arrow(angle = 35,length=unit(0.3,"cm")))+geom_text(data=e.pca,aes(x=e.pca[,1],y=e.pca[,2],label=rownames(e.pca)),size=3.5,colour="black", hjust=(1-sign(e.pca[,1]))/2,angle=(180/pi)*atan(e.pca[,2]/e.pca[,1]))+theme(legend.position="top")
p1## 保存pdf格式图片到本地
ggsave("PCA1.pdf",plot = p1,device = "pdf",height = 6,width = 8)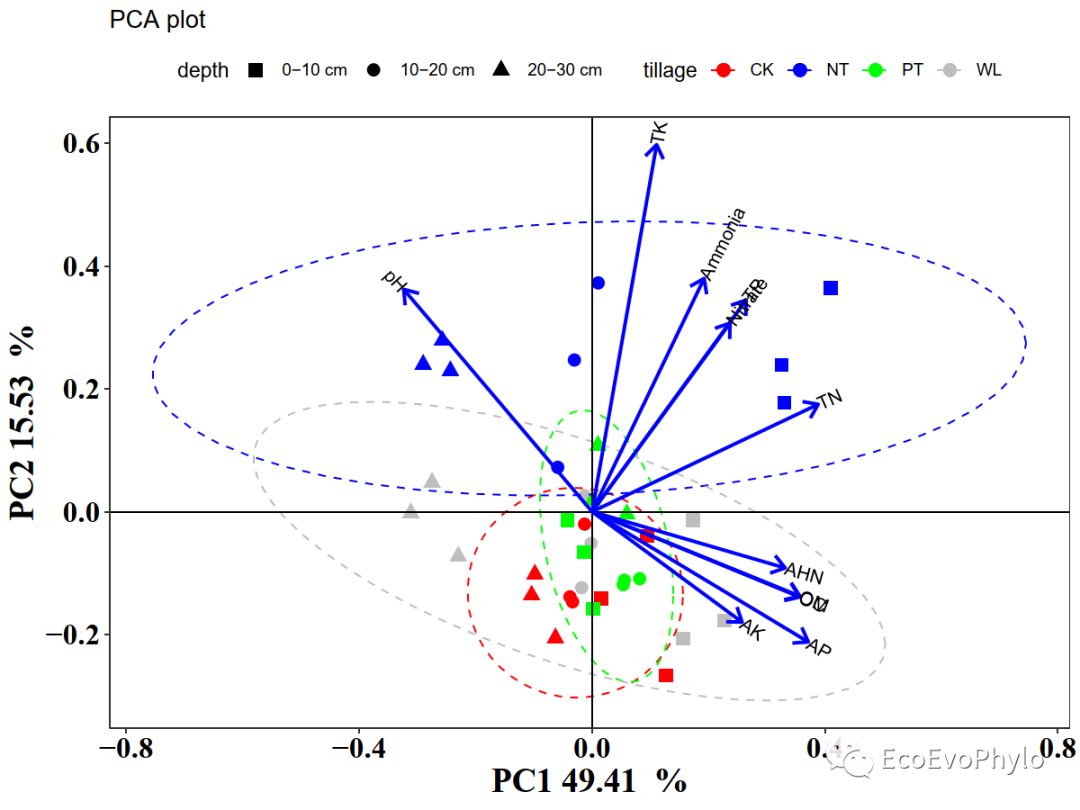
图5|单坐标轴样本和环境变量PCA双序图。
3.3.2 双坐标轴PCA双序图
使用点表示样本,箭头表示环境变量。因为两者PC轴的量级不一样,为了图的美观易读,下和左坐标轴表示样本的PC1和PC2,上和右坐标轴表示环境变量的PC1和PC2。
# 3.3.2 样本和环境变量使用不同的坐标轴
### stat_ellipse()添加置信椭圆
p2 = ggplot(data=s.pca,aes(PC1,PC2))+geom_point(aes(color=tillage,fill=tillage,shape=depth),size=3)+scale_color_manual(values=c("red","blue","green","grey"))+scale_shape_manual(values =c(15,16,17))+stat_ellipse(aes(group=tillage,color=tillage),level = 0.95,linetype=2)+labs(title="PCA plot",x=paste("PC1",PC1," %"),y=paste("PC2",PC2," %"))+theme_bw()+theme(axis.title = element_text(family = "serif", face = "bold", size = 18,colour = "black"))+theme(axis.text = element_text(family = "serif", face = "bold", size = 16,color="black"))+theme(panel.grid=element_blank())+geom_hline(yintercept=0)+geom_vline(xintercept=0)
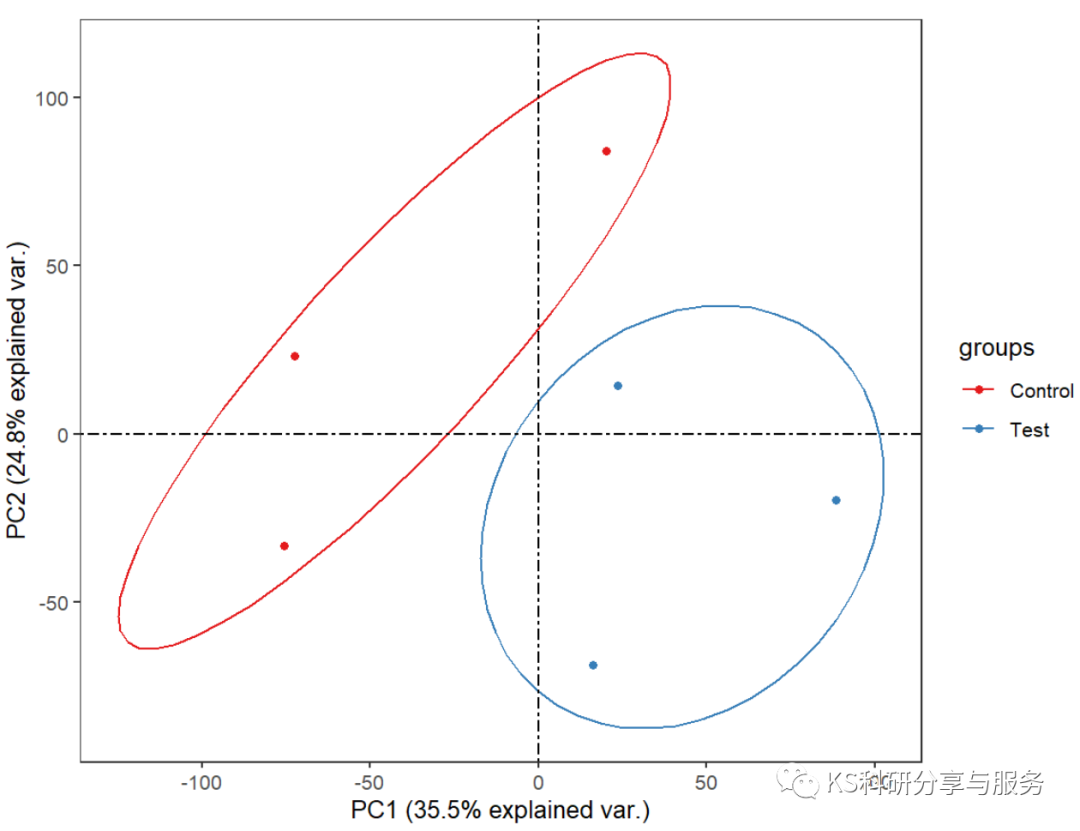
p2 # 首先绘制带95%置信椭圆的样本排序散点图## 使用sec_axis()设置第二坐标区间,坐标轴区间根据自身数据区间设置。
### scale_x/y_continuous(position="bottom/left")可用于设置第二坐标轴设置为下和上侧。
### breaks=round(seq(-0.8,1,0.2),1)用于设置刻度;
### labels=round(seq(-0.8,1,0.2),1)))设置刻度标签;
### theme()用于将第二坐标的轴线和刻度线设置为红色;
### coord_fixed(ratio =1.5/1) 设置X/Y坐标轴刻度长度相对比例。
p2 = p2 +geom_segment(data=e.pca,aes(x=0,y=0,xend=e.pca[,1],yend=e.pca[,2]),size=1,colour="black",arrow=arrow(angle = 35,length=unit(0.3,"cm")))+scale_x_continuous(expand=c(0,0),limits = c(-0.8,1),breaks=round(seq(-0.8,1,0.2),1),labels=round(seq(-0.8,1,0.2),1),sec.axis = sec_axis(~rescale(.,c(-0.8,1)),breaks=round(seq(-0.8,1,0.2),1),labels=round(seq(-0.8,1,0.2),1)))+scale_y_continuous(expand=c(0,0),limits = c(-0.4,0.6),breaks=round(seq(-0.4,0.6,0.1),1),labels=round(seq(-0.4,0.6,0.1),1),sec.axis = sec_axis(~rescale(.,c(-0.8,1.2)), breaks=round(seq(-0.8,1.2,0.2),1),labels=round(seq(-0.8,1.2,0.2),1)))+geom_text(data=e.pca,aes(x=e.pca[,1],y=e.pca[,2],label=rownames(e.pca)),size=3.5,colour="black",hjust=(1-sign(e.pca[,1]))/2,angle=(180/pi)*atan(e.pca[,2]/e.pca[,1]))+theme(legend.position="top",axis.line.x.top = element_line(colour="red"),axis.line.y.right = element_line(color = "red"),axis.ticks.x.top = element_line(color = "red"),axis.ticks.y.right = element_line(color = "red"))+coord_fixed(ratio =1.5/1)
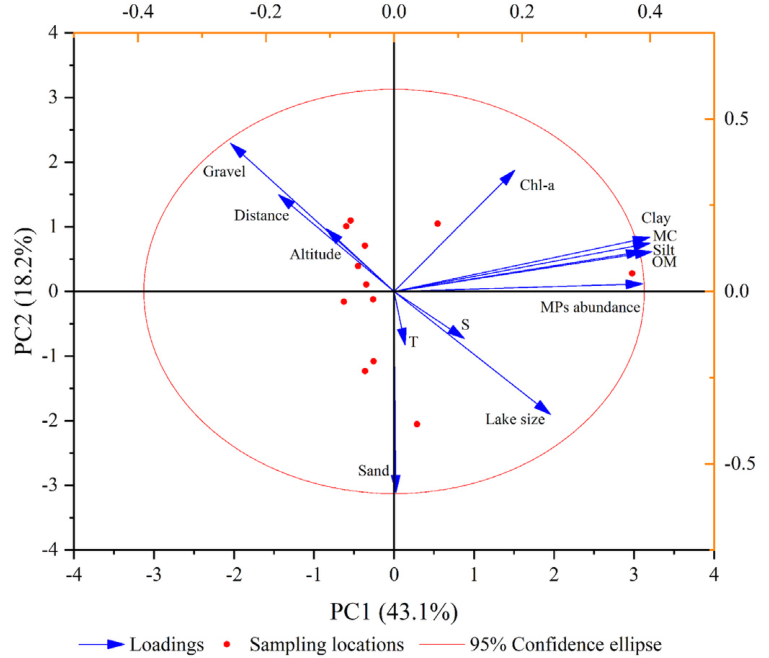
p2 # 添加环境因子箭头,并添加次坐标轴## 保存pdf格式图片到本地
ggsave("PCA2.pdf",plot = p2,device = "pdf",height = 6,width = 8)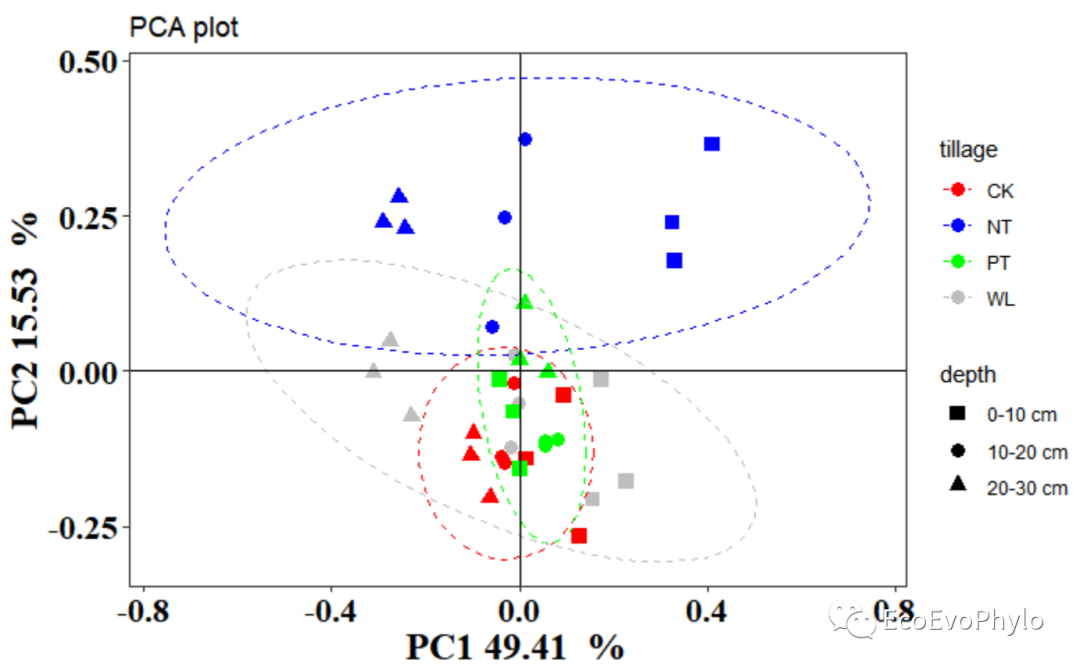
图6|PCA样本排序图。
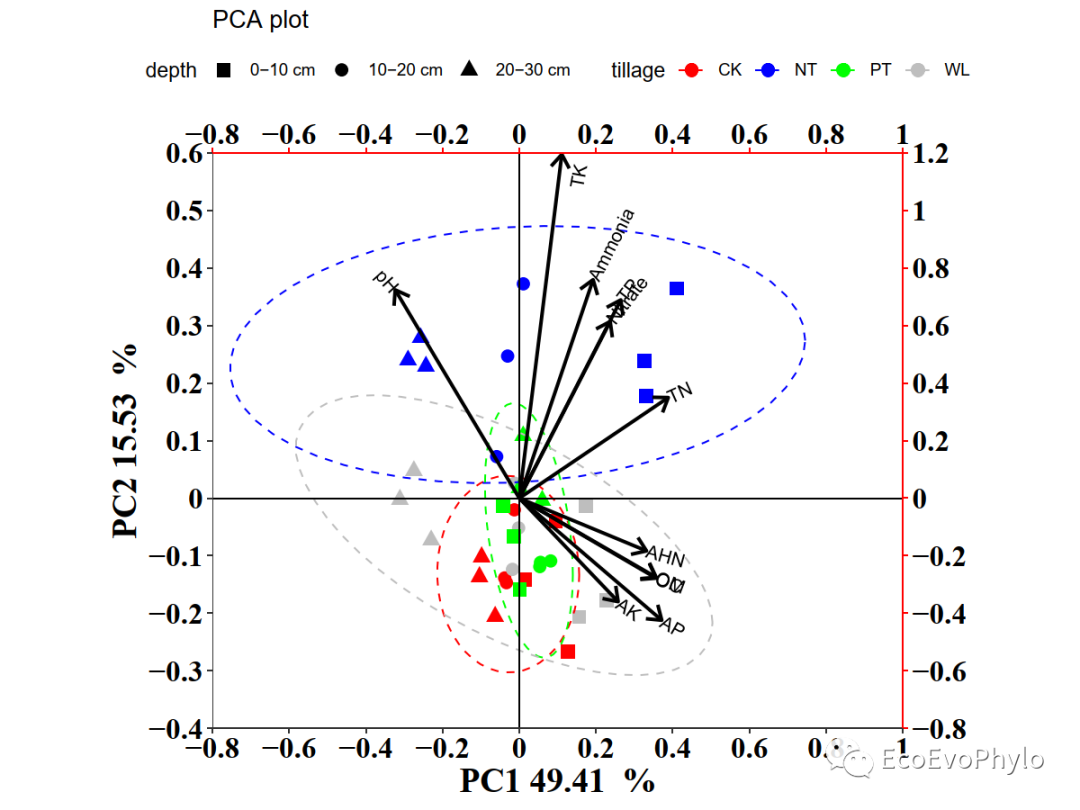 图7|PCA双坐标轴双序图。需要注意的是,如果需要刻度线是对应的,比如0与0对应,则需要主坐标轴与次坐标轴的设置范围是等比例的,且必须设置expand=c(0,0)。如果只是绘制双Y轴图,可以设置全部从0起始,其他刻度可以不用对应上。
图7|PCA双坐标轴双序图。需要注意的是,如果需要刻度线是对应的,比如0与0对应,则需要主坐标轴与次坐标轴的设置范围是等比例的,且必须设置expand=c(0,0)。如果只是绘制双Y轴图,可以设置全部从0起始,其他刻度可以不用对应上。
使用拼图的方法绘制双坐标轴图也是可以的,参考文献部分提供了另一种方法,所以这里就不写了。QQ交流群文件夹中下载,或后台发送“PCA双坐标轴双序图”,获取数据与代码文件。
参考文献
一文解决ggplot2坐标轴轴刻度线的设置问题
R语言ggplot2-调整坐标轴(一)
用R绘制双Y轴方法2
分享一个在ggplot2中绘制双坐标轴(Y轴)的方法
推荐阅读
R统计绘图-分子生态相关性网络分析
R语言实战|初阶1:基本图形
R语言实战|入门5:高级数据管理
R语言实战|入门4:基本数据管理
R语言实战|入门3:图形初阶
R语言实战|入门2:了解数据集
R语言实战|入门1:R语言介绍
R中进行单因素方差分析并绘图
R统计-多变量单因素参数、非参数检验及多重比较
R绘图-相关性分析及绘图
R绘图-相关性系数图
R统计绘图-环境因子相关性热图
R统计绘图-corrplot绘制热图及颜色、字体等细节修改
R统计绘图-corrplot热图绘制细节调整2(更改变量可视化顺序、非相关性热图绘制、添加矩形框等)
R绘图-RDA排序分析
R统计-VPA分析(RDA/CCA)
R统计-PCA/PCoA/db-RDA/NMDS/CA/CCA/DCA等排序分析教程
R数据可视化之美-节点链接图
R统计绘图-rgbif包下载GBIF数据及绘制分布图
R统计-正态性分布检验[Translation]
R统计-数据正态分布转换[Translation]
R统计-方差齐性检验[Translation]
R统计-Mauchly球形检验[Translation]
R统计绘图-单、双、三因素重复测量方差分析[Translation]
R统计绘图-混合方差分析[Translation]
R统计绘图-协方差分析[Translation]
R统计绘图-One-Way MANOVA

EcoEvoPhylo :主要分享微生物生态和phylogenomics的数据分析教程。
扫描左侧二维码,关注EcoEvoPhylo。让我们大家一起学习,互相交流,共同进步。
学术交流QQ群 | 438942456
学术交流微信群 | jingmorensheng412
加好友时,请备注姓名-单位-研究方向。