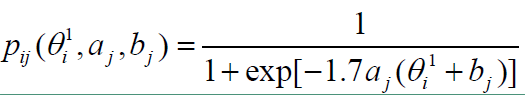IRT模型中参数估计
IRT(Item Response Theory) 项目反应理论。是教育评估与心理测量理论中的重要模型。主要目的是通过被试(examinees) 的对于一套试题的反应(responses), 对被试 的能力(ability parameters) 参数 θ \theta θ 和题目(item parameters) 作出估计。由于被试的反应变量一般是离散变量,基本的是0-1反应变量,link 函数一般有probit和logit两种。例如,2pl, 2pno,3pl等。
而对于不同的反应模型,估计方法大致相同,总体来说分为两大体系。频率框架下是联合极大似然估计(Joint Maximum Likelihood Estimation, JMLE) 和边际极大似然(Marginal Maximum Likelihood Estimation, MMLE). Bayesian 框架下,常用估计方法有Gibbs算法、MCMC算法及其衍生估计方法。
下面要介绍的EM算法是基于logit link下的2pl模型进行EM估计。
2pl模型的EM估计
-
2pl模型
2pl模型,全称是two parameter logistic model,实际上是logistics 回归中的一种。
假设 i = 1 , 2 , … … , N i=1,2,……,N i=1,2,……,N 个人作答了 j = 1 , 2 , … … , J j=1,2,……,J j=1,2,……,J 个题目,相应的反应矩阵 Y = ( Y i j ) i = 1 , j = 1 N , J Y=(Y_{ij})_{i=1,j=1}^{N, J} Y=(Yij)i=1,j=1N,J 代表第 i i i 个人在作答第 j j j 题的反应,也就是说, Y i j = 1 Y_{ij}=1 Yij=1 代表答对了,否则代表没有答对,这里只考虑两值反应。假设人的能力参数 θ i \theta_{i} θi,项目参数集合 Ω = { a = ( a j ) j = 1 J , d = ( d j ) j = 1 J } \varOmega=\left\lbrace \boldsymbol{a}=(a_{j})_{j=1}^{J}, \boldsymbol{d}=(d_{j})_{j=1}^{J}\right\rbrace Ω={a=(aj)j=1J,d=(dj)j=1J}, 表示项目参数区分度a和难度参数的等价参数d。
2pl模型的项目反应函数如下,
L ( Y ; θ , a , d ) = ∏ i = 1 N ∏ j = 1 J P ( Y i j = 1 ; θ i , a j , d j ) Y i j P ( Y i j = 0 ; θ i , a j , d j ) 1 − Y i j L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})=\prod_{i=1}^{N} \prod_{j=1}^{J} P(Y_{ij}=1;\theta_{i}, a_{j}, d_{j})^{Y_{ij}}P(Y_{ij}=0;\theta_{i}, a_{j}, d_{j})^{1-Y_{ij}} L(Y;θ,a,d)=i=1∏Nj=1∏JP(Yij=1;θi,aj,dj)YijP(Yij=0;θi,aj,dj)1−Yij
其中,
P ( Y i j = 1 ; θ i , a j , d j ) = e x p ( a j θ i + d j ) 1 + e x p ( a j θ i + d j ) P(Y_{ij}=1;\theta_{i}, a_{j}, d_{j})=\frac{exp(a_{j}\theta_{i}+d_{j})}{1+exp(a_{j}\theta_{i}+d_{j})} P(Yij=1;θi,aj,dj)=1+exp(ajθi+dj)exp(ajθi+dj)
Note, 这个似然也可以写成是
L ( Y ; θ , a , d ) = ∏ i = 1 N ∏ j = 1 J e x p ( y i j ( a j θ i + d j ) ) 1 + e x p ( a j θ i + d j ) L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})=\prod_{i=1}^{N} \prod_{j=1}^{J}\frac{exp(y_{ij}(a_{j}\theta_{i}+d_{j}))}{1+exp(a_{j}\theta_{i}+d_{j})} L(Y;θ,a,d)=i=1∏Nj=1∏J1+exp(ajθi+dj)exp(yij(ajθi+dj)) -
EM估计具体计算过程
EM算法,也叫边际极大似然估计,marginal maximum likelihood estimation。基本想法就是把潜在变量(latent variable) θ \theta θ 积分掉之后的边际似然函数,求极大似然估计。
2pl的对数边际似然函数为,
l o g L ( Y ; a , d ) = l o g ∫ θ L ( Y ; θ , a , d ) g ( θ ) d θ logL(Y;\boldsymbol{a}, \boldsymbol{d})=log\int _{\boldsymbol{\theta}}L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})g(\boldsymbol{\theta})d\boldsymbol{\theta} logL(Y;a,d)=log∫θL(Y;θ,a,d)g(θ)dθ
= ∑ i = 1 N l o g ∫ ∏ j = 1 J e x p ( y i j ( a j θ i + d j ) ) 1 + e x p ( a j θ i + d j ) g ( θ i ) d θ i =\sum_{i=1}^{N}log\int\prod_{j=1}^{J}\frac{exp(y_{ij}(a_{j}\theta_{i}+d_{j}))}{1+exp(a_{j}\theta_{i}+d_{j})}g(\theta_{i})d\theta_{i} =i=1∑Nlog∫j=1∏J1+exp(ajθi+dj)exp(yij(ajθi+dj))g(θi)dθi
其中 g ( θ ) g(\boldsymbol{\theta}) g(θ) 是能力参数 θ \boldsymbol{\theta} θ 的先验分布。目标是,求 ( a ^ , d ^ ) = a r g m a x { l o g L ( Y ; a , d ) } . (\widehat \boldsymbol{a}, \widehat \boldsymbol{d})=argmax \left\lbrace logL(Y;\boldsymbol{a}, \boldsymbol{d})\right\rbrace. (a ,d )=argmax{logL(Y;a,d)}.对于这种最优化问题,一般常用的方法常用的方法有Newton,GD等方法。Newton方法是需要解方程 0 = ∂ l o g L ( Y ; a , d ) ∂ a j 0=\frac{\partial logL(Y;\boldsymbol{a}, \boldsymbol{d})}{\partial a_{j}} 0=∂aj∂logL(Y;a,d),除了一阶导数之外,还需要再求二阶导数。GD,梯度下降方法,只需要一阶导数,具体原理见下面wiki百科。
综上,一阶导数是必须要求的,然后上面的式子对 a j a_{j} aj求一阶偏导,
∂ l o g L ( Y ; a , d ) ∂ a j = ∂ ∂ a j l o g ∫ θ L ( Y ; θ , a , d ) g ( θ ) d θ \frac{\partial logL(Y;\boldsymbol{a}, \boldsymbol{d})}{\partial a_{j}}=\frac{\partial}{\partial a_{j}}log \int _{\boldsymbol{\theta}}L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})g(\boldsymbol{\theta})d\boldsymbol{\theta} ∂aj∂logL(Y;a,d)=∂aj∂log∫θL(Y;θ,a,d)g(θ)dθ
= 1 ∫ θ L ( Y ; θ , a , d ) g ( θ ) d θ ∫ θ ∂ ∂ a j L ( Y ; θ , a , d ) g ( θ ) d θ =\frac{1}{\int _{\boldsymbol{\theta}}L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})g(\boldsymbol{\theta})d\boldsymbol{\theta}}\int _{\boldsymbol{\theta}}\frac{\partial}{\partial a_{j}}L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})g(\boldsymbol{\theta})d\boldsymbol{\theta} =∫θL(Y;θ,a,d)g(θ)dθ1∫θ∂aj∂L(Y;θ,a,d)g(θ)dθ
= ∫ θ L ( Y ; θ , a , d ) g ( θ ) ∫ θ L ( Y ; θ , a , d ) g ( θ ) d θ ∂ ∂ a j l o g L ( Y ; θ , a , d ) d θ , = \int_{\boldsymbol{\theta}} \frac{L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})g(\boldsymbol{\theta})}{\int _{\boldsymbol{\theta}}L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})g(\boldsymbol{\theta})d\boldsymbol{\theta}}\frac{\partial}{\partial a_{j}}logL(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})d\boldsymbol{\theta}, =∫θ∫θL(Y;θ,a,d)g(θ)dθL(Y;θ,a,d)g(θ)∂aj∂logL(Y;θ,a,d)dθ,
= ∑ i = 1 N ∫ θ i ( y i j − e x p ( a j θ i + d j ) 1 + e x p ( a j θ i + d j ) ) θ i P ( θ i ∣ Y i . , a , d ) d θ i . =\sum_{i=1}^{N}\int_{\theta_{i}} (y_{ij}-\frac{exp(a_{j}\theta_{i}+d_{j})}{1+exp(a_{j}\theta_{i}+d_{j})})\theta_{i}P(\theta_{i}|Y_{i.},\boldsymbol{a},\boldsymbol{d})d{\theta_{i}}. =i=1∑N∫θi(yij−1+exp(ajθi+dj)exp(ajθi+dj))θiP(θi∣Yi.,a,d)dθi.
因为 L ( Y ; θ , a , d ) g ( θ ) ∫ θ L ( Y ; θ , a , d ) g ( θ ) d θ = P ( θ ∣ Y , a , d ) \frac{L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})g(\theta)}{\int _{\boldsymbol{\theta}}L(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})g(\theta)d\boldsymbol{\theta}}=P(\boldsymbol{\theta}|Y,\boldsymbol{a},\boldsymbol{d}) ∫θL(Y;θ,a,d)g(θ)dθL(Y;θ,a,d)g(θ)=P(θ∣Y,a,d) 是 θ \theta θ的联合后验分布,同时
∂ ∂ a j l o g L ( Y ; θ , a , d ) = ∂ ∂ a j ∑ i = 1 N ∑ j = 1 J y i j ( a j θ i + d j ) − l o g ( 1 + e x p ( a j θ i + d j ) ) \frac{\partial}{\partial a_{j}}logL(Y;\boldsymbol{\theta}, \boldsymbol{a}, \boldsymbol{d})=\frac{\partial}{\partial a_{j}}\sum_{i=1}^{N}\sum_{j=1}^{J}y_{ij}(a_{j}\theta_{i}+d_{j})-log(1+exp(a_{j}\theta_{i}+d_{j})) ∂aj∂logL(Y;θ,a,d)=∂aj∂i=1∑Nj=1∑Jyij(ajθi+dj)−log(1+exp(ajθi+dj))
= ∑ i = 1 N ( y i j − e x p ( a j θ i + d j ) 1 + e x p ( a j θ i + d j ) ) θ i . =\sum_{i=1}^{N}(y_{ij}-\frac{exp(a_{j}\theta_{i}+d_{j})}{1+exp(a_{j}\theta_{i}+d_{j})})\theta_{i}. =i=1∑N(yij−1+exp(ajθi+dj)exp(ajθi+dj))θi.
但是实际上,由于积分对于计算机来说是很庞大的计算量,所以在计算过程中,一般使用有限的节点的离散分布来逼近这个连续积分。具体做法如下,对所有人的 θ i \theta_{i} θi取区间[-4,4] 内的节点 X i k , k = 1 , 2 , … … , q X_{ik}, k=1,2,……,q Xik,k=1,2,……,q。假设先验密度服从标准正态分布,对于第 i i i个人的后验密度函数为,
P ( θ i = X i k ∣ Y i . , a , d ) = e x p ( ∑ j = 1 J y i j ( a j X i k + d j ) − X i k 2 2 ) ∏ j = 1 J ( 1 + e x p ( a j X i k + d j ) ) ∑ k = 1 q e x p ( ∑ j = 1 J y i j ( a j X i k + d j ) − X i k 2 2 ) ∏ j = 1 J ( 1 + e x p ( a j X i k + d j ) ) . P(\theta_{i}=X_{ik}|Y_{i.},\boldsymbol{a},\boldsymbol{d})=\frac{\frac{exp(\sum_{j=1}^{J}y_{ij}(a_{j}X_{ik}+d_{j})-\frac{X_{ik}^{2}}{2})}{\prod_{j=1}^{J}(1+exp(a_{j}X_{ik}+d_{j}))}}{\sum_{k=1}^{q}\frac{exp(\sum_{j=1}^{J}y_{ij}(a_{j}X_{ik}+d_{j})-\frac{X_{ik}^{2}}{2})}{\prod_{j=1}^{J}(1+exp(a_{j}X_{ik}+d_{j}))}}. P(θi=Xik∣Yi.,a,d)=∑k=1q∏j=1J(1+exp(ajXik+dj))exp(∑j=1Jyij(ajXik+dj)−2Xik2)∏j=1J(1+exp(ajXik+dj))exp(∑j=1Jyij(ajXik+dj)−2Xik2).
从而,
∂ l o g L ( Y ; a , d ) ∂ a j = ∑ k = 1 q ∑ i = 1 N ( y i j − e x p ( a j X i k + d j ) 1 + e x p ( a j X i k + d j ) ) X i k P ( θ i = X i k ∣ Y i . , a , d ) . \frac{\partial logL(Y;\boldsymbol{a}, \boldsymbol{d})}{\partial a_{j}}=\sum_{k=1}^{q}\sum_{i=1}^{N}(y_{ij}-\frac{exp(a_{j}X_{ik}+d_{j})}{1+exp(a_{j}X_{ik}+d_{j})})X_{ik}P(\theta_{i}=X_{ik}|Y_{i.},\boldsymbol{a},\boldsymbol{d}). ∂aj∂logL(Y;a,d)=k=1∑qi=1∑N(yij−1+exp(ajXik+dj)exp(ajXik+dj))XikP(θi=Xik∣Yi.,a,d).
以上这个方程就是在EM算法当中目标要求的边际似然函数,剩下的是利用最优化的方法来得到最优解。参数 d \boldsymbol{d} d 也是类似得到一阶导数。
- 具体的GD算法步骤如下,
1,initial values ( a ( 0 ) , d ( 0 ) ) (\boldsymbol{a}^{(0)},\boldsymbol{d}^{(0)}) (a(0),d(0));
2,posterior density P ( θ i = X i k ∣ Y i . , a , d ) P(\theta_{i}=X_{ik}|Y_{i.},\boldsymbol{a},\boldsymbol{d}) P(θi=Xik∣Yi.,a,d);
3,gradient ∂ l o g L ( Y ; a , d ) ∂ a j ∣ ( a j ( 0 ) , d j ( 0 ) ) \frac{\partial logL(Y;\boldsymbol{a}, \boldsymbol{d})}{\partial a_{j}}|_{(a_{j}^{(0)},d_{j}^{(0)})} ∂aj∂logL(Y;a,d)∣(aj(0),dj(0)) and ∂ l o g L ( Y ; a , d ) ∂ d j ∣ ( a j ( 0 ) , d j ( 0 ) ) \frac{\partial logL(Y;\boldsymbol{a}, \boldsymbol{d})}{\partial d_{j}}|_{(a_{j}^{(0)},d_{j}^{(0)})} ∂dj∂logL(Y;a,d)∣(aj(0),dj(0));
4,update ( a j , d j ) (a_{j},d_{j}) (aj,dj) by
a j ( 1 ) = a j ( 0 ) + s t e p s i z e ∗ ∂ l o g L ( Y ; a , d ) ∂ j ∣ ( a j ( 0 ) , d j ( 0 ) ) d j ( 1 ) = d j ( 0 ) + s t e p s i z e ∗ ∂ l o g L ( Y ; a , d ) ∂ d j ∣ ( a j ( 0 ) , d j ( 0 ) ) ; a_{j}^{(1)}=a_{j}^{(0)}+stepsize*\frac{\partial logL(Y;\boldsymbol{a}, \boldsymbol{d})}{\partial _{j}}|_{(a_{j}^{(0)},d_{j}^{(0)})}\\d_{j}^{(1)}=d_{j}^{(0)}+stepsize *\frac{\partial logL(Y;\boldsymbol{a}, \boldsymbol{d})}{\partial d_{j}}|_{(a_{j}^{(0)},d_{j}^{(0)})}; aj(1)=aj(0)+stepsize∗∂j∂logL(Y;a,d)∣(aj(0),dj(0))dj(1)=dj(0)+stepsize∗∂dj∂logL(Y;a,d)∣(aj(0),dj(0));
5,repeat until the tolerance, that is, the difference of the k t h th th and (k+1) t h th th step is under some values or satisfying other criteriors. - 模拟研究
- 生成模拟数据
假设 N = 2000 N=2000 N=2000, J = 20 J=20 J=20, a ∼ r u n i f ( J , 0 , 2 ) a\sim runif(J,0,2) a∼runif(J,0,2), d ∼ r u n i f ( J , − 1 , 1 ) d\sim runif(J,-1,1) d∼runif(J,−1,1), θ i ∼ r n o r m ( 1 , 0 , 1 ) \theta_{i}\sim rnorm(1,0,1) θi∼rnorm(1,0,1)。根据2pl模型生成数据,下面是R的code。
N <- 2000;J <- 20;
theta_true <- cbind(rep(1,N),rnorm(N));
a_true<-runif(J,0,2);d_true<-runif(J,-1,1);A_true<-cbind(d_true,a_true);
P_true<-1/(1+exp(-theta_true%*%t(A_true)));
response <- matrix(rbinom(N*J,1,P_true),nrow=N,ncol=J);#response
colnames(response)<-1:J;
以下是反应矩阵的前5行,也就是前5个人的20题的反应向量。

- 估计过程。
–R package “mirt”.
在R package “mirt” 中,提供了已有的函数mirt直接进行估计,详细的R包的introduction等见下面的链接和参考文献。以下是代码。
library(mirt);
aa<-mirt(response,1,verbose=FALSE);
bb <- cbind(A_true,coef(aa,simplify=TRUE)[[1]][,2],coef(aa,simplify=TRUE)[[1]][,1])[,1:4];
colnames(bb)<-c("d_true","a_true","d_estimator","a_estimator");
以下是输出结果,结果的average bias差不多是0.02503983。

–GD方法,自己编的code,如下。
#####my code####
#initial value
d_initial <- d_0 <- runif(J,-1,1);a_initial <- a_0 <- runif(J,0,2)
THETA_TUTA <- seq(-4,4,by=8/20);theta_tmp <- THETA_TUTA*THETA_TUTA/2
s_a <- a_0;s_d <- d_0
mm <- cbind(d_0,a_0)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);
xx<- sweep(exp(sweep(response%*%mm,2,theta_tmp,"-")), 2, apply(1+exp(mm),2,prod), "/");
log_lik_0 <- sum(log(rowSums(xx)));
theta_post <- xx/rowSums(xx);
yy <- 1/(1+exp(-mm));
for(j in 1:J){step_A <- step_d <- 1/200a_grad <- sum(response[,j]*(sweep(theta_post,2,THETA_TUTA,"*")))-sum(sweep(theta_post,2,yy[j,]*THETA_TUTA,"*"))a_tmp <- a_0[j]+a_grad*step_Aa_ttmp <- a_0;a_ttmp[j] <- a_tmp;mm_1 <- cbind(d_0,a_ttmp)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx_1<- sweep(exp(sweep(response%*%mm_1,2,theta_tmp,"-")), 2, apply(1+exp(mm_1),2,prod), "/");log_lik_a_1 <- sum(log(rowSums(xx_1)));while(log_lik_a_1<log_lik_0+step_A*a_grad*a_grad*0.3){step_A <- step_A*0.5a_tmp <- a_0[j]+a_grad*step_A;a_ttmp <- a_0;a_ttmp[j] <- a_tmp;mm_1 <- cbind(d_0,a_ttmp)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx_1<- sweep(exp(sweep(response%*%mm_1,2,theta_tmp,"-")), 2, apply(1+exp(mm_1),2,prod), "/");log_lik_a_1 <- sum(log(rowSums(xx_1)));}d_grad <- sum(response[,j]*theta_post)-sum(sweep(theta_post,2,yy[j,],"*"))d_tmp <- d_0[j]+d_grad*step_d;d_ttmp <- d_0;d_ttmp[j] <- d_tmp;mm_1 <- cbind(d_ttmp,a_0)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx_1<- sweep(exp(sweep(response%*%mm_1,2,theta_tmp,"-")), 2, apply(1+exp(mm_1),2,prod), "/");log_lik_d_1 <- sum(log(rowSums(xx_1)));while(log_lik_d_1<log_lik_0+step_d*d_grad*d_grad*0.2){step_d <- step_d*0.5d_tmp <- d_0[j]+d_grad*step_d;d_ttmp <- d_0;d_ttmp[j] <- d_tmp;mm_1 <- cbind(d_ttmp,a_0)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx_1<- sweep(exp(sweep(response%*%mm_1,2,theta_tmp,"-")), 2, apply(1+exp(mm_1),2,prod), "/");log_lik_d_1 <- sum(log(rowSums(xx_1)));}s_a[j] <- a_tmp;s_d[j] <- d_tmp
}
a_0 <- s_a;d_0 <- s_d
mm <- cbind(d_0,a_0)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);
xx<- sweep(exp(sweep(response%*%mm,2,theta_tmp,"-")), 2, apply(1+exp(mm),2,prod), "/");
log_lik_1 <- sum(log(rowSums(xx)));
eps <- log_lik_1-log_lik_0
while(eps>0.001){log_lik_0 <- log_lik_1;mm <- cbind(d_0,a_0)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx<- sweep(exp(sweep(response%*%mm,2,theta_tmp,"-")), 2, apply(1+exp(mm),2,prod), "/");theta_post <- xx/rowSums(xx);yy <- 1/(1+exp(-mm));for(j in 1:J){step_A <- step_d <- 1/200a_grad <- sum(response[,j]*(sweep(theta_post,2,THETA_TUTA,"*")))-sum(sweep(theta_post,2,yy[j,]*THETA_TUTA,"*"))a_tmp <- a_0[j]+a_grad*step_Aa_ttmp <- a_0;a_ttmp[j] <- a_tmp;mm_1 <- cbind(d_0,a_ttmp)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx_1<- sweep(exp(sweep(response%*%mm_1,2,theta_tmp,"-")), 2, apply(1+exp(mm_1),2,prod), "/");log_lik_a_1 <- sum(log(rowSums(xx_1)));while(log_lik_a_1<log_lik_0+step_A*a_grad*a_grad*0.3){step_A <- step_A*0.5a_tmp <- a_0[j]+a_grad*step_A;a_ttmp <- a_0;a_ttmp[j] <- a_tmp;mm_1 <- cbind(d_0,a_ttmp)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx_1<- sweep(exp(sweep(response%*%mm_1,2,theta_tmp,"-")), 2, apply(1+exp(mm_1),2,prod), "/");log_lik_a_1 <- sum(log(rowSums(xx_1)));}d_grad <- sum(response[,j]*theta_post)-sum(sweep(theta_post,2,yy[j,],"*"))d_tmp <- d_0[j]+d_grad*step_d;d_ttmp <- d_0;d_ttmp[j] <- d_tmp;mm_1 <- cbind(d_ttmp,a_0)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx_1<- sweep(exp(sweep(response%*%mm_1,2,theta_tmp,"-")), 2, apply(1+exp(mm_1),2,prod), "/");log_lik_d_1 <- sum(log(rowSums(xx_1)));while(log_lik_d_1<log_lik_0+step_d*d_grad*d_grad*0.2){step_d <- step_d*0.5d_tmp <- d_0[j]+d_grad*step_d;d_ttmp <- d_0;d_ttmp[j] <- d_tmp;mm_1 <- cbind(d_ttmp,a_0)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx_1<- sweep(exp(sweep(response%*%mm_1,2,theta_tmp,"-")), 2, apply(1+exp(mm_1),2,prod), "/");log_lik_d_1 <- sum(log(rowSums(xx_1)));}s_a[j] <- a_tmp;s_d[j] <- d_tmp}a_0 <- s_a;d_0 <- s_dmm <- cbind(d_0,a_0)%*%rbind(rep(1,length(THETA_TUTA)),THETA_TUTA);xx<- sweep(exp(sweep(response%*%mm,2,theta_tmp,"-")), 2, apply(1+exp(mm),2,prod), "/");log_lik_1 <- sum(log(rowSums(xx)));eps <- log_lik_1-log_lik_0
}
以下是输出结果,结果的average bias差不多是0.02554339,这组模拟数据也用结果与"mirt" package的结果相差不是很大。通过调节tolerance,结果应该大致一致。

- 关于simulation 的比较以及方法的各种性质的考量,应该多做一些replication,获得standard error以及mse等指标。这里没有再叙述。
https://zh.wikipedia.org/wiki/梯度下降法
https://zh.wikipedia.org/wiki/牛顿法
https://philchalmers.github.io/mirt/html/ltm_models_with_mirt.html
[1]: Baker, F. B., & Kim, S. H. (2004). Item response theory: Parameter estimation techniques. CRC Press.
[2]:Chalmers, R. P. (2012). mirt: A multidimensional item response theory package for the R environment. Journal of Statistical Software, 48(6), 1-29.