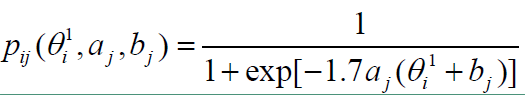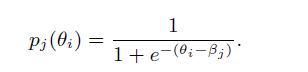2019独角兽企业重金招聘Python工程师标准>>> 
自适应学习之IRT简介
一、近端发展区(ZPD)
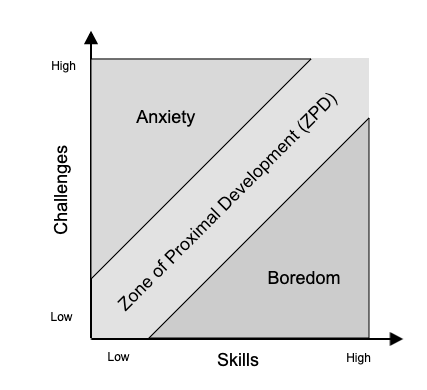
Zone of Proximal Development(ZPD)是由心理学家Vygotsky提出来的一种学习理论,是目前自适应学习常用的思考模型。他认为,能力高的学习者在学习难度低的知识时会感觉无聊,而能力低的人在学习难度高的知识时会感觉焦虑,他们只有在学习难度适中的知识时才会实现有效学习。这个难度适中的区域称为近端发展区(Zone of Proximal Development,简称ZPD)。
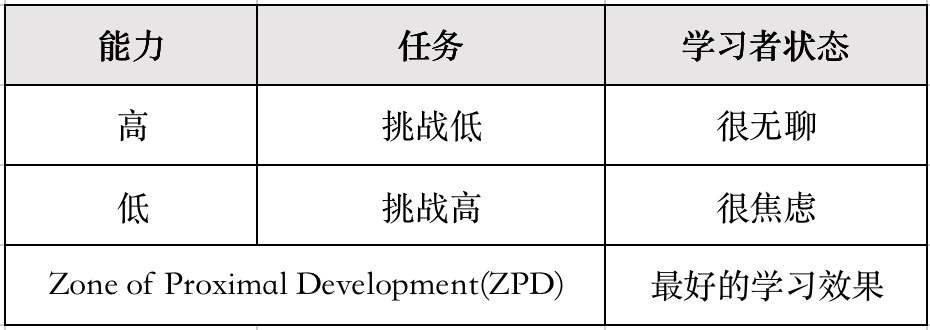
自适应系统持续测量学习者的能力高低,用算法来推导下一步任务,尽可能让学习者保持在ZPD区域內,让学习者在学习系统辅助下得到最好的学习效果。
那么,如何才能测量学习者的能力和任务难度的关系呢?这里介绍一种常见的理论 -- Item Response Theory,简称 IRT。
二、项目反应理论(IRT)
Item Response Theory (IRT)最早使用在心理学领域,目的是做能力评估。现在已广泛应用于教育行业,用于校准评估测试、潜在特征的评分等。下面介绍一下与之相关的Rasch模型和2P模型。
1. Rasch 模型
Rashch模型是IRT应用中使用最广泛的模型。假如我们有J个题目,分别是X1,X2,... , XJ。1表示学生回答正确,0表示学生回答错误。在Rashch模型里,学生i做对第j道题目的概率为:
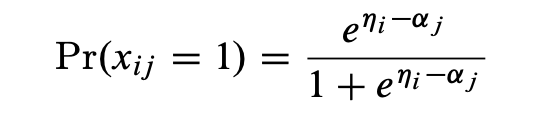
ηi表示学生i的学习能力
αj表示第j道题目的难度
实际上,IRT理论是个广泛的概念,不仅仅指学生和题目的关系。本文为了方便大家理解,仅用学生和题目举例。
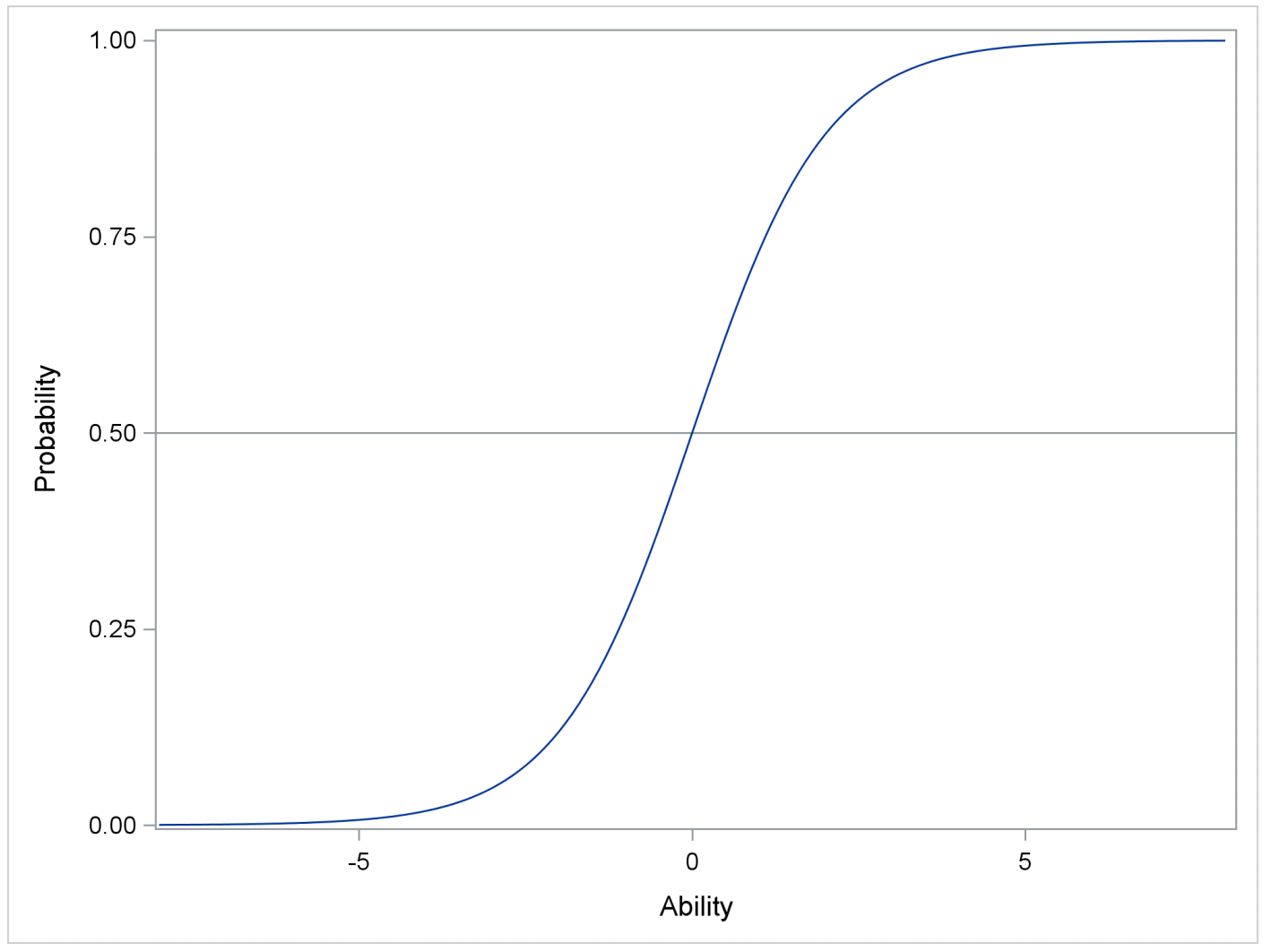
题目答对的概率取决于学生的能力和题目的难度。这个概率可以用下图来表示,这个图称为项目特征曲线(item characteristic curve ,简称ICC)。这个概率是一个单调递增的函数,这意味着,随着学生能力的增长,题目答对的概率也随之增长。当学生的能力与题目的难度相等时,带入公式可以得出P=1/(1+1)=0.5,即答对的概率是50%。当学生的能力高于题目的难度时,答对的概率就高于50%,反之则低于50%。这跟我们的认知是一致的。
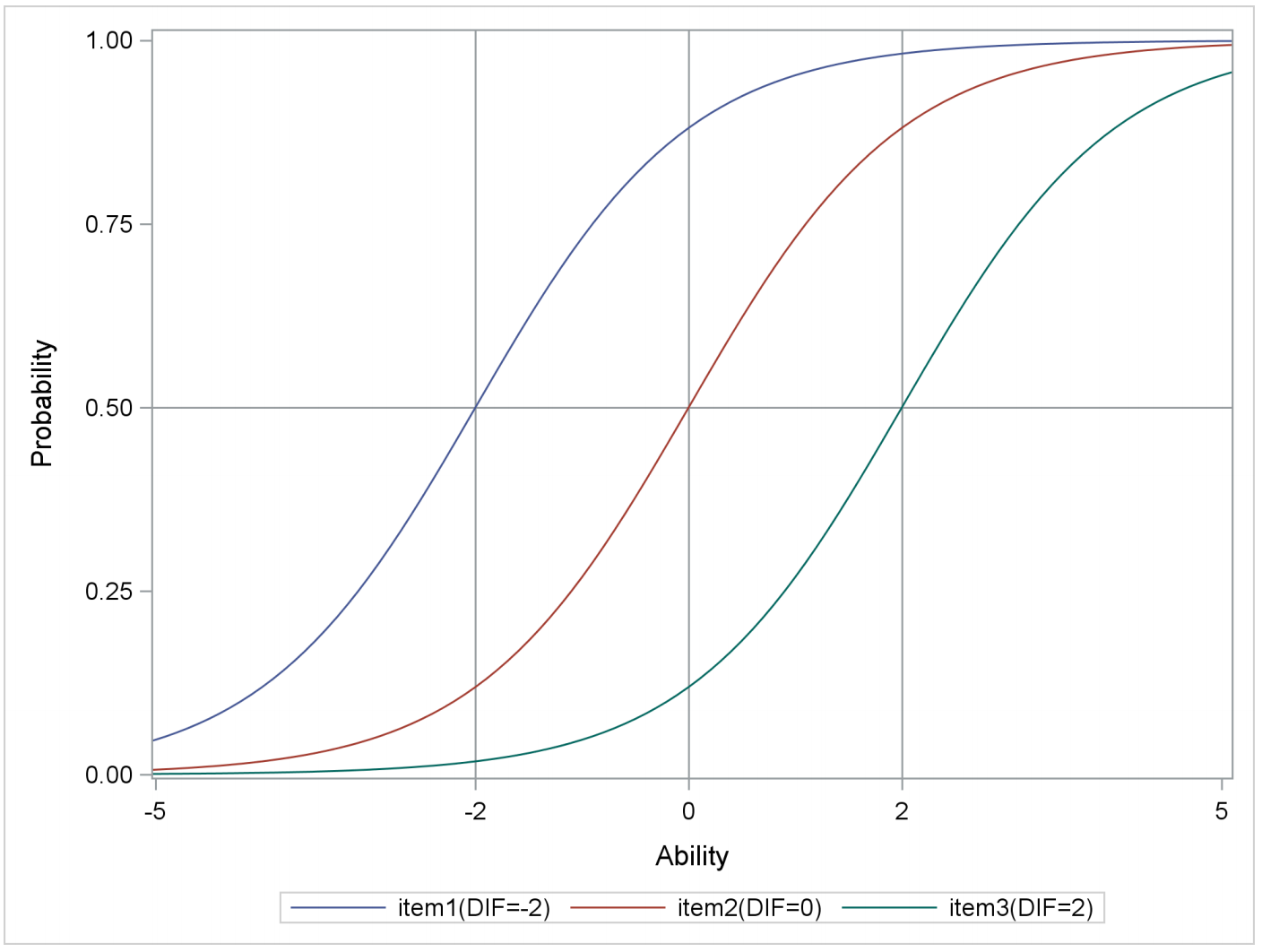
假如我们有3个题目,他们分别为简单题(难度为-2,蓝色曲线)、普通题(难度为0,红色曲线)和高难度题(难度为2,绿色曲线)。我们可以看到,曲线的位置是由题目的难度决定的。
假如有3类学生,分别为学渣(能力为-2)、普通学生(能力为0)和学霸(能力为2)。对于不同题目和不同学生的组合,根据Rasch模型的公式,可以计算他们答对的概率情况,结果如下表所示:
| 简单题 | 普通题 | 高难度题 | |
| 学渣 | 50% | 11.9% | 1.8% |
| 普通学生 | 88% | 50% | 11.9% |
| 学霸 | 98% | 88% | 50% |
从表中可以看出来,对于学渣,最好是给他们做简单题。因为他们答对普通题和高难度题的概率很低,很难从中学到知识。而对于学霸,则高难度题更适合他们。
适合他们的题目,即对应他们各自的ZPD区域。
2. 2P模型
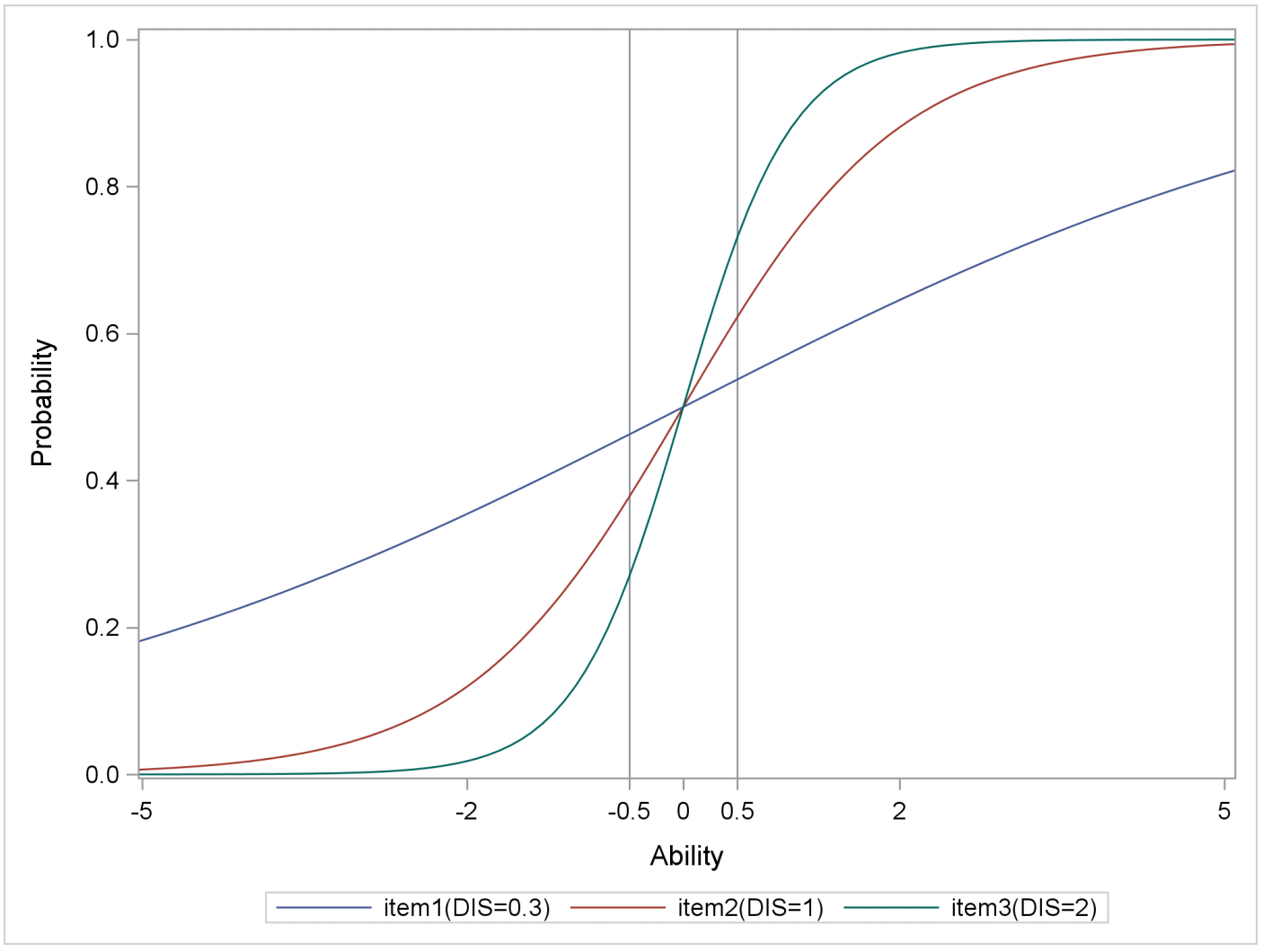
在Rasch模型中,所有的曲线,其形状都是一样的。实际上,这是不合理的。比如,有两道难度相同(比如难度等于2)的题目,一道是判断题,一道是选择题(4个选项)。对于判断题,即使学渣完全不知道怎么做,也有大约有50%概率能答对,而学霸也是50%左右的概率能答对。对于选择题,学渣大约有25%概率能答对,而学霸仍然是50%左右。因此,选择题比判断题能够更好的区分学霸和学渣,我们称它的区分度(discrimination)更高。2P模型(two-parameter model)就是在Rasch模型中引入了区分度的概念。
在2P模型中,学生i答对题目j的概率为:
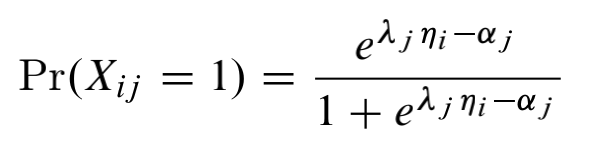
λj表示题目j的区分度
ηi表示学生i的学习能力
αj表示第j道题目的难度
下表是在不同难度题目、不同区分度(0.3,1,2)和不同类型学生组合情况下,学生答对题目概率统计表。
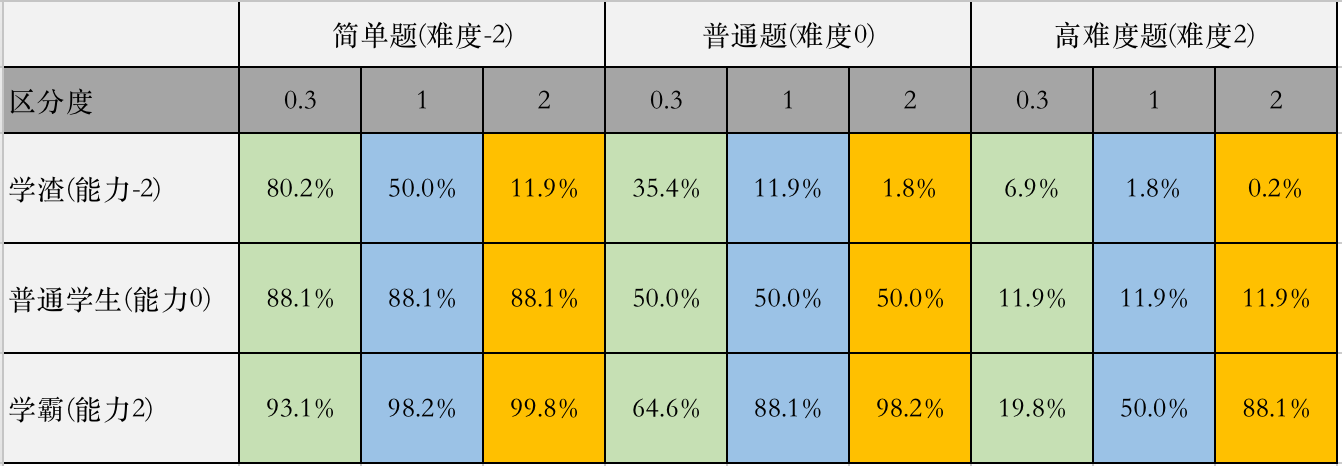
绿色部分是低区分度题目的结果,同样的题目,学渣、普通学生和学霸答对的概率区别不大。
橙色部分是高区分度题目的结果,同样的题目,学渣、普通学生和学霸答对的概率区别很大。
因此,我们更偏爱区分度高的题目,它能够更有效的识别学生能力。
下面是三个难度均为0的题目。他们的区分度分别是0.3,1和2。可以看到,不同的区分度分别对应不同的形状的曲线。区分度越高的题目,曲线在0点附近位置就越陡峭,斜率(slope)越大。