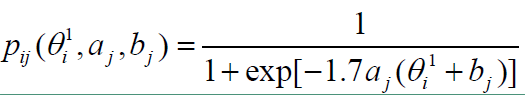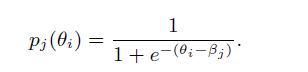写在前面:
本文在DKVMN的基础上结合项目IRT,加入了student ability network 和 difficulty network两个网络,增加深度知识追踪的可解释性
1 摘要
基于深度学习的知识追踪模型已被证明在不需要人工设计特征的情况下优于传统的知识追踪模型,但其参数和表示长期以来一直被批评为无法解释。在本文中,我们提出了 Deep-IRT,它是项目响应理论 (IRT) 模型和基于称为动态键值记忆网络 (DKVMN) 的深度神经网络架构的知识追踪模型的综合,用于进行深度学习基于可解释的知识追踪。具体来说,我们使用 DKVMN 模型来处理学生的学习轨迹,并随着时间的推移估计项目难度水平和学生能力。然后,我们使用 IRT 模型使用估计的学生能力和项目难度来估计学生正确回答项目的概率。实验表明,Deep-IRT 模型保留了 DKVMN 模型的性能,同时提供了对学生和项目的直接心理解释。
2 相关工作
2.1 项目反应理论(IRT)
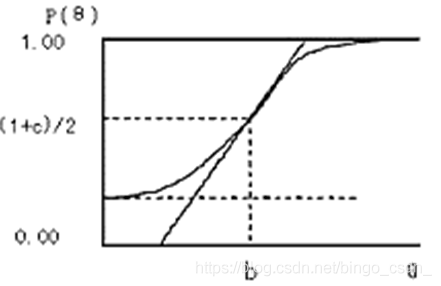
自 1950 年代以来,项目反应理论 (IRT) 一直用于教育测试环境。它根据学生的能力水平 θ 和项目的难度水平 β j \beta_j βj(在最简单的单参数 IRT1 中)输出学生在测试期间正确回答问题 j 的概率 P (a)。该概率由具有以下特征的项目响应函数定义: 如果学生的能力水平较高,可以以高准确率正确回答问题。另一方面,如果一个项目更难,学生正确回答该项目的概率较低。最常见的是,逻辑回归模型在 IRT 模型中用作项目响应函数:
P ( a ) = σ ( θ − β j ) = 1 1 + e x p ( − ( θ − β j ) ) (1) P(a)=\sigma(\theta-\beta_j)=\frac{1}{1+exp(-(\theta-\beta_j))}\tag{1} P(a)=σ(θ−βj)=1+exp(−(θ−βj))1(1)
除了估计概率 P (a) 之外,IRT 模型还被广泛用于估计学生能力 θ 和项目难度水平 β j \beta_j βj。然而,由于 IRT 模型最初是为教育测试环境设计的,因此该模型假设学生的能力在测试期间不会发生变化。因此,它不能直接应用于知识追踪任务,因为学生的知识状态会随着时间而变化。
2.2 基于因素分析(Factors Analysis )的知识追踪
在 2000 年代,学习因素分析 (learning factors analysis -LFA) 和性能因素分析 (performance factors analysis -PFA) 被提出来使用逻辑回归模型来处理知识追踪任务。两种模型都类似于 IRT 模型,但它们通过学习技能水平参数来估计学生正确回答问题的概率。 LF A 的公式如下:
P ( a ) = σ ( θ + ∑ j ∈ s k i l l s ( γ j N j − β j ) ) (2) P(a)=\sigma(\theta+\sum_{j\in skills}(\gamma_jN_j-\beta_j))\tag{2} P(a)=σ(θ+j∈skills∑(γjNj−βj))(2)
其中 σ(·) 是 sigmoid 函数,θ、 γ j \gamma_j γj 和 β j \beta_j βj 是模型参数, N j N_j Nj是模型的输入。与 IRT 模型类似,θ 和 β j \beta_j βj可以分别被认为是学生的能力和习题 j 的难度级别。 N j N_j Nj 表示学生对技能 j 的尝试次数,因此 γ j \gamma_j γj 可以解释为技能 j 的学习率。
LF A 模型出现后,Pavlik 等人认为学生的表现比学生的能力在处理 KT 任务中的影响更大,提出了 PFA 模型,它对学生的表现而不是学生的能力提供更高的敏感性 .具体来说,它丢弃了 LF A 模型中的参数 θ,并将输入 N j N_j Nj拆分为 S j S_j Sj和 F j F_j Fj,分别代表学生在技能 j 上的成功和失败尝试次数。 PFA 模型公式如下:
P ( a ) = σ ( ∑ j ∈ s k i l l s ( α j S j + ρ j F j − β j ) ) (3) P(a)=\sigma(\sum_{j\in skills}(\alpha _j S_j+\rho_jF_j-\beta_j))\tag{3} P(a)=σ(j∈skills∑(αjSj+ρjFj−βj))(3)
其中 α j \alpha_j αj和 ρ j \rho_j ρj 是新的模型参数。类似地, α j \alpha_j αj和 ρ j \rho_j ρj 都可以分别被认为是技能 j 应用成功和不成功时的学习率。与 IRT 模型类似,我们可以认为 PF A 模型将 α j S j + ρ j F j \alpha _j S_j+\rho_jF_j αjSj+ρjFj视为学生在技能 j 上的能力 θ,这样一个学生在不同的技能上可以有不同的能力水平。事实证明,PFA 模型的性能优于 LFA 模型 。
3 deep-IRT model
3.1 DKVMN工作机制
DKVMN的工作机制可以看我之前写的DKVMN论文的笔记,那个更为详细,这里就不再叙述了
3.2 学生能力和习题难度网络
当 DKVMN 模型接收到一个 KC q t q_t qt时,它会在影响期间形成特征向量 f t f_t ft。由于 f t f_t ft 是读取向量 r t r_t rt 和 KC 嵌入向量 k t k_t kt的串联,它包含学生在 q t q_t qt上的知识状态信息和 q t q_t qt 的嵌入信息。我们相信,通过神经网络进一步处理 f t f_t ft, f t f_t ft 可用于推断学生在 q t q_t qt上的能力。类似地,可以通过将 KC 嵌入向量 k t k_t kt 传递给神经网络来得出 q t q_t qt 的难度级别。
根据神经网络的用途,我们将这两个网络分别称为学生能力网络和难度网络。使用单个全连接层,公式如下:
θ t j = t a n h ( W θ f t + b θ ) (12) \theta _{tj}=tanh(W_\theta f_t +b_\theta)\tag{12} θtj=tanh(Wθft+bθ)(12)
β j = t a n h ( W β q t + b β ) (13) \beta_j=tanh(W_\beta q_t +b_\beta)\tag{13} βj=tanh(Wβqt+bβ)(13)
其中 θ t j \theta_{tj} θtj 和 β j \beta_j βj 可以分别解释为学生在时间 t 上 KC j 的能力和 KC j 的难度级别。我们使用tanh作为两个网络的激活函数,这样两个输出都被缩放到 (-1, 1) 范围内。然后,将这两个值传递给项目响应函数,以计算学生正确回答 KC j 的概率:
p t = σ ( 3.0 ∗ θ t j − β j ) (14) p_t=\sigma(3.0*\theta_{tj}-\beta_j)\tag{14} pt=σ(3.0∗θtj−βj)(14)
出于实际原因,学生能力网络的输出乘以 3.0 倍。例如,如果不按比例放大学生的能力,可以得到的最大值为 σ ( 1 − ( − 1 ) ) = σ ( 2 ) = 0.881 \sigma(1-(-1))=\sigma(2)=0.881 σ(1−(−1))=σ(2)=0.881
时间 t 的网络架构如下图 所示。需要注意的是,学生能力网络和 KC 难度网络可以应用于任何类型的神经网络。例如,这两个网络可以插入到 DKT 模型中,即 RNN,被隐藏层和输出层包围。通过同时使用 DKVMN 模型和 IRT 模型制定知识追踪任务,我们从两个世界中获得了最好的结果。该模型受益于深度学习技术的进步,因此它可以捕捉到人类难以设计的特征。另一方面,我们通过引入一个众所周知的心理测量模型来增强可解释性,该模型可以被许多人轻松理解。

4 实验部分
4.1 数据集
在实验中使用了四个公共数据集和一个专有数据集。对于公共数据集,我们使用了 Zhang 等人 [22] 提供的处理过的数据。这些数据集的信息是见表一

4.2 实验参数设置
我们使用它们的 ID 标签将输入 q t q_t qt和 ( q t , a t ) (q_t,a_t) (qt,at)输入到网络,其中 I D ( q t ) = q t ∈ 1 , 2 , … , Q ID(q_t)=q_t\in{1,2,\dots,Q} ID(qt)=qt∈1,2,…,Q和 I D ( q t , a t ) = q t + a t ∗ Q ∈ 1 , 2 , … , 2 Q ID(q_t,a_t)=q_t+a_t*Q\in{1,2,\dots,2Q} ID(qt,at)=qt+at∗Q∈1,2,…,2Q如果有 Q 个不同的 KC。 q t q_t qt和 ( q t , a t ) (q_t,a_t) (qt,at)的 ID 分别用于查找 KC 嵌入矩阵 A 和 KC 响应嵌入矩阵 B 中的嵌入向量。
最小化交叉熵损失函数学习模型参数,使用 Adam 优化学习模型,学习率为 0.003,batch size 为 32。
评价标准:AUC,ACC
4.3 实验结果
实验的模型性能如表 2 所示,相应的超参数如表 3 所示。此外,我们还将表 2 中的 PFA 模型的性能作为基准模型进行参考。


5 讨论
5.1 Going Deeper in Difficulty Level
为了评估从 Deep-IRT 模型估计的 KC 难度,我们将 FSAIF1toF3 数据集学习到的难度级别与其他四个来源进行了比较。我们使用专有数据集的原因是我们有出版商提供的个别问题的难度级别。每个问题都与 {1, 2, 3} 中的难度级别相关联,分别代表简单、中等和困难。

5.2 Going Deeper in Student Ability
如[20]所述,DKT模型存在两个问题。第一个是 DKT 模型无法重建观察到的输入。这意味着即使学生成功尝试,学生的估计表现也会下降,反之亦然。第二个问题是不同 KCs 的估计性能随着时间的推移并不一致。这意味着在模型影响期间,学生的掌握水平在已掌握和尚未掌握之间交替。这两种行为是不可取的,因此我们想检查这些问题是否存在于 Deep-IRT 模型中。
的估计性能随着时间的推移并不一致。这意味着在模型影响期间,学生的掌握水平在已掌握和尚未掌握之间交替。这两种行为是不可取的,因此我们想检查这些问题是否存在于 Deep-IRT 模型中。

写在最后
目前已经把Ante-hoc的具有可解释性文献大概过了一遍,主要分为两类,一类是添加注意力机制,如DKVMN。另外一类是自解释模型,该模型是结合某种可解释方法,提高一定的可解释性。可这两种和我想要做的可解释性不一样,我想做的是最后可以给出具体的学习路径或者知识的先后关系图。下面要继续学习近两年具有可解释的知识追踪文献。