【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
1 背景
在这一系列开始前我们就说过,简单的爬虫很容易,但是要完成一个高效健壮的爬虫不是一个简单的事情,这一系列我们已经明白了爬虫相关的如下核心知识点。
《正则表达式基础》
《Python3.X 爬虫实战(先爬起来嗨)》
《Python3.X 爬虫实战(静态下载器与解析器)》
基于上面这几篇其实我们把爬虫当作自己便利的开发工具来使用基本上是够了(譬如老板让你定期留意观察自己做的应用功能上线后的用户行为数据,方便开发把握功能潜在风险,这个其实我们就可以写个 Python 爬虫小程序去后台定期查,然后定期邮件发送到我的邮箱,这样就不用自己老记着这回事然后去上网页操作了),但是对于动态网页爬取我们还未探讨、对于爬取数据处理我们也没探讨、对于爬取性能问题我们也没探讨。。。我靠,还有很多东西等待我们去发掘,MLGB,那我们这一篇就先探讨下 python 爬虫的并发爬取,其实就是 Python 的并发,呜呜!
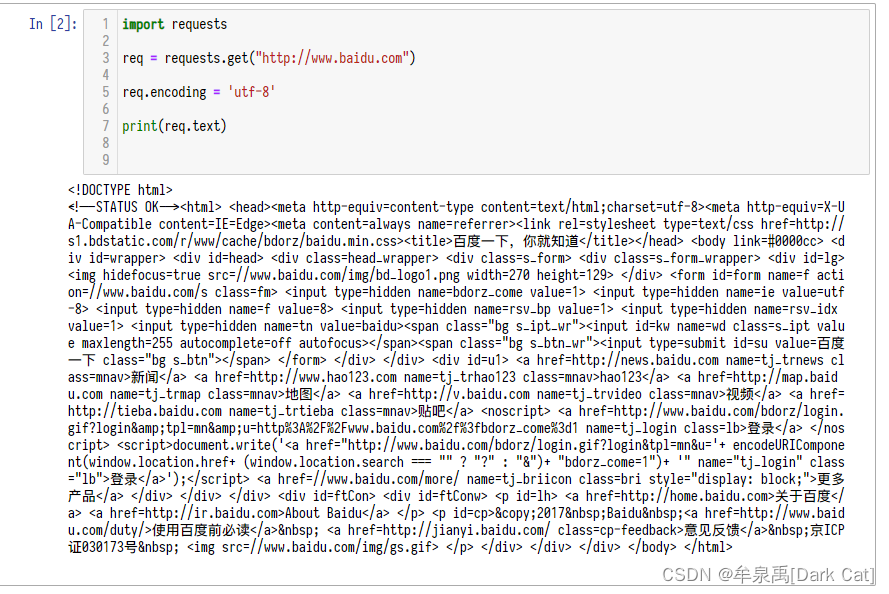
之所以讨论这个话题是为了解决《Python3.X 爬虫实战(静态下载器与解析器)》一文中 LXml 解析爬取美图录美女图片网站的效率问题,你会发现我们上一篇中那个程序的执行效率非常低,爬取完那些妹子图需要很就,因为他们是顺序的,加上我们还没有对妹子图网站进行全站爬取,如果要全站爬取那就是个相当恐怖的事情了,不信我们可以通过《Python3.X 爬虫实战(先爬起来嗨)》一文介绍的 site 方式查看这个站点有多少页面可以爬取,如下:
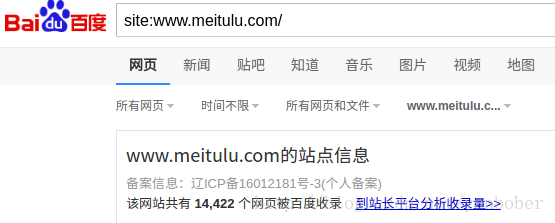
这还不算特别多,但我们已经无法忍受这么慢的爬取速度了,所以我们就要想办法解决这个问题,也就是这一篇要探讨的问题,不过首先你得具备 Python 并发编程的基础,如果还不 OK 可以看看知乎上 Python 之美的 Python 并发编程系列文章,讲的不错,或者去看看 Python 核心编程一书。
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
2 Python 3.X 并发铺垫
其实这一小节没必要存在的,但是为了补全就列出来了(注意:如果自己具备并发基础就直接移步 Part3 并发爬虫实战)。对于程序的进程、线程关系及区别的概念其实是不区分具体编程语言的,也就说如果我们过去在计算机基础、Unix 高级 C 语言编程、Java 编程、Android 编程等学习过进程与线程的概念,那么 Python 的并发也就好理解了,唯一区别是他们的语法和 API 名字及用法不同而已。
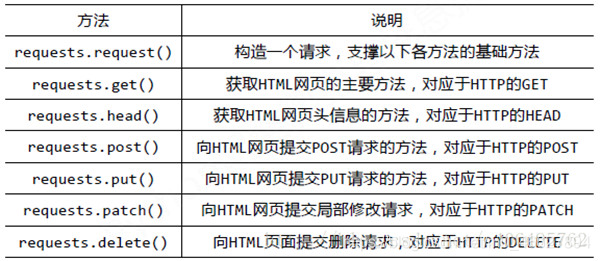
Python3 使用 POSIX 兼容的(pthreads)线程,提供了多个多线程编程模块,譬如 _thread、threading、Queue、concurrent.futures 包等,其中 _thread、threading 允许我们创建管理线程,主要区别就是 _thread (以前 Python 中的 thread,Python3 中已经不能再使用 thread 模块,为了兼容 Python3 将它重命名为 _thread 了)只提供了基本的线程及锁支持;而 threading 提供了更加牛逼的线程管理机制;Queue 为我们提供了一个用于多线程共享数据的队列;concurrent.futures包从 Python3.2 开始被纳入了标准库,其提供的ThreadPoolExecutor 和 ProcessPoolExecutor 是对 threading 和 multiprocessing 的高级抽象,暴露统一的接口来方便实现异步调用。
2-1 Python 3.X _thread 模块
这是个备受大家抛弃的 Python 并发模块,在 Python 低版本中叫 thread,高版本为了兼容叫 _thread,但是不推荐使用了,具体不推荐的原因大致如下:
- _thread 模块的同步原语只有一个,比较弱,threading 却有很多;
- _thread 模块之后出现了更加高级的 threading,你说你选哪个呢;
- 不支持守护线程等,使用 _thread 模块对于进程该何时结束基本无法控制(主线程结束后所有线程被没有任何警告和清理的情况下强制结束),而 threading 模块基本可以保证重要子线程结束后才退出主线程;
说到底就是因为我是个渣渣,驾驭不了 _thread 模块,哈哈,所以我无耻的选择了 threading 模块;多说无用,直接给段代码演示下吧,这段代码在各种语言的多线程中都是经典,没啥特殊的,如下:
[本实例完整源码点我获取 demo_thread.py]
import _thread
import time
'''
Python 3.X _thread 模块演示 Demo
当注释掉 self.lock.acquire() 和 self.lock.release() 后运行代码会发现最后的 count 为 467195 等随机值,并发问题。
当保留 self.lock.acquire() 和 self.lock.release() 后运行代码会发现最后的 count 为 1000000,锁机制保证了并发。
time.sleep(5) 就是为了解决 _thread 模块的诟病,注释掉的话子线程没机会执行了
'''
class ThreadTest(object):def __init__(self):self.count = 0self.lock = Nonedef runnable(self):self.lock.acquire()print('thread ident is '+str(_thread.get_ident())+', lock acquired!')for i in range(0, 100000):self.count += 1print('thread ident is ' + str(_thread.get_ident()) + ', pre lock release!')self.lock.release()def test(self):self.lock = _thread.allocate_lock()for i in range(0, 10):_thread.start_new_thread(self.runnable, ())if __name__ == '__main__':test = ThreadTest()test.test()print('thread is running...')time.sleep(5)print('test finish, count is:' + str(test.count))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
所以很直观的看见咯,确实值得唾弃,我们还是看看 threading 吧。
2-2 Python 3.X threading 模块
关于 threading 模块提供的对象其实我们可以直接看看 threading.py 源码的__all__定义,里面有具体列举,如下:
__all__ = ['get_ident', 'active_count', 'Condition', 'current_thread','enumerate', 'main_thread', 'TIMEOUT_MAX','Event', 'Lock', 'RLock', 'Semaphore', 'BoundedSemaphore', 'Thread','Barrier', 'BrokenBarrierError', 'Timer', 'ThreadError','setprofile', 'settrace', 'local', 'stack_size']
看了这个定义和官网 API 后顺手搜到这篇文章不错(点我查看),感兴趣的可以自己去琢磨下咯,下面我们先给出 threading 模块下 Thread 类的一般用法,如下:
[本实例完整源码点我获取 demo_threading.py]
import threading
from threading import Thread
import time
'''
Python 3.X threading 模块演示 Demothreading 的 Thread 类基本使用方式(继承重写 run 方法及直接传递方法)
'''
class NormalThread(Thread):'''重写类比 Java 的 Runnable 中 run 方法方式'''def __init__(self, name=None):Thread.__init__(self, name=name)self.counter = 0def run(self):print(self.getName() + ' thread is start!')self.do_customer_things()print(self.getName() + ' thread is end!')def do_customer_things(self):while self.counter < 10:time.sleep(1)print('do customer things counter is:'+str(self.counter))self.counter += 1def loop_runner(max_counter=5):'''直接被 Thread 调用方式'''print(threading.current_thread().getName() + " thread is start!")cur_counter = 0while cur_counter < max_counter:time.sleep(1)print('loop runner current counter is:' + str(cur_counter))cur_counter += 1print(threading.current_thread().getName() + " thread is end!")if __name__ == '__main__':print(threading.current_thread().getName() + " thread is start!")normal_thread = NormalThread("Normal Thread")normal_thread.start()loop_thread = Thread(target=loop_runner, args=(10,), name='LOOP THREAD')loop_thread.start()loop_thread.join()normal_thread.join()print(threading.current_thread().getName() + " thread is end!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
怎么样,最直接的感触就是再也不用像 _thread 那样让主线程预估结束时间等待子线程结束,使用 Thread 类以后直接可以使用 join 方式等待子线程结束,当然还有别的方式,自己可以琢磨;我们会发现其两种写法和 Java 线程非常类似,很棒,下面我们再给出简单的同步锁处理案例,如下:
[本实例完整源码点我获取 demo_threading_lock.py]
'''
Python 3.X threading 模块演示 Demothreading 锁同步机制
当注释掉 self.lock.acquire() 和 self.lock.release() 后运行代码会发现最后的 count 为 467195 等,并发问题。
当保留 self.lock.acquire() 和 self.lock.release() 后运行代码会发现最后的 count 为 1000000,锁机制保证了并发。
'''
import threading
from threading import Threadclass LockThread(Thread):count = 0def __init__(self, name=None, lock=None):Thread.__init__(self, name=name)self.lock = lockdef run(self):self.lock.acquire()print('thread is '+threading.current_thread().getName()+', lock acquired!')for i in range(0, 100000):LockThread.count += 1print('thread is '+threading.current_thread().getName()+', pre lock release!')self.lock.release()if __name__ == '__main__':threads = list()lock = threading.Lock()for i in range(0, 10):thread = LockThread(name=str(i), lock=lock)thread.start()threads.append(thread)for thread in threads:thread.join()print('Main Thread finish, LockThread.count is:'+str(LockThread.count))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
对于一般的并发同步使用 Lock 就足够了,简单吧,关于其他的锁机制(上面__all__ 的定义)自己可以参考其他资料进行学习,这里点到为止,下面我们再来看看爬虫中常用的线程优先级队列,如下:
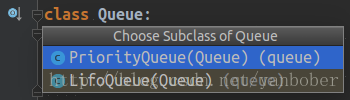
Python3 的 Queue 模块提供了同步、线程安全队列类,包括先入先出队列 Queue、后入先出队列 LifoQueue 和优先级队列 PriorityQueue,这些队列都实现了锁机制,可以在多线程中直接使用,也可以用这些队列来实现线程间的同步,下面给出一个简单但是经典的示例(生产消费者问题),如下:
[本实例完整源码点我获取 demo_threading_queue.py]
from queue import Queue
from random import randint
from threading import Thread
from time import sleep
'''
Python 3.X threading 与 Queue 结合演示 Demo
经典的并发生产消费者模型
'''class TestQueue(object):def __init__(self):self.queue = Queue(2)def writer(self):print('Producter start write to queue.')self.queue.put('key', block=1)print('Producter write to queue end. size is:'+str(self.queue.qsize()))def reader(self):value = self.queue.get(block=1)print('Consumer read from queue end. size is:'+str(self.queue.qsize()))def producter(self):for i in range(5):self.writer()sleep(randint(0, 3))def consumer(self):for i in range(5):self.reader()sleep(randint(2, 4))def go(self):print('TestQueue Start!')threads = []functions = [self.consumer, self.producter]for func in functions:thread = Thread(target=func, name=func.__name__)thread.start()threads.append(thread)for thread in threads:thread.join()print('TestQueue Done!')if __name__ == '__main__':TestQueue().go()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
可以看到,一般与爬虫相关常见和常用的 Python3 线程相关东西主要就上面这些,当然还有一些高端的用法和高端的线程类我们没有提到,这些需要我们自己去积累和依据自己爬虫需求选择合适的线程辅助类;这里我们篇幅有限不再展开,因为对于任何语言用好线程并发本来就是一个非常有深度的方向,涉及的问题也很多,但是对于一般业务来说上面的足矣。
2-3 Python 3.X 进程模块
上面我们介绍了 Python3 的 thread 并发相关基础,我们都知道除过多线程还有多进程,其内存空间划分等机制都是不一样的,这是在别的语言我们都知道的。然而在 Python 中如果我们想充分使用多核 CPU 资源,那就得使用多进程,Python 给我们提供了非常好用的多进程模块包 multiprocessing,其支持子进程、通信和共享数据等工具操作,非常棒。
下面先来看下 multiprocessing 的 Process 一般用法套路吧(其实完全类似 threading 用法,只不过含义和实质不同而已),如下:
[本实例完整源码点我获取 demo_multiprocessing.py]
import multiprocessing
import time
from multiprocessing import Process
'''
Python 3.X multiprocess 模块演示 Demo
其实完全类似 threading 用法,只不过含义和实质不同而已
multiprocess 的 Process 类基本使用方式(继承重写 run 方法及直接传递方法)
'''
class NormalProcess(Process):def __init__(self, name=None):Process.__init__(self, name=name)self.counter = 0def run(self):print(self.name + ' process is start!')self.do_customer_things()print(self.name + ' process is end!')def do_customer_things(self):while self.counter < 10:time.sleep(1)print('do customer things counter is:'+str(self.counter))self.counter += 1def loop_runner(max_counter=5):print(multiprocessing.current_process().name + " process is start!")cur_counter = 0while cur_counter < max_counter:time.sleep(1)print('loop runner current counter is:' + str(cur_counter))cur_counter += 1print(multiprocessing.current_process().name + " process is end!")if __name__ == '__main__':print(multiprocessing.current_process().name + " process is start!")print("cpu count:"+str(multiprocessing.cpu_count())+", active chiled count:"+str(len(multiprocessing.active_children())))normal_process = NormalProcess("NORMAL PROCESS")normal_process.start()loop_process = Process(target=loop_runner, args=(10,), name='LOOP PROCESS')loop_process.start()print("cpu count:" + str(multiprocessing.cpu_count()) + ", active chiled count:" + str(len(multiprocessing.active_children())))normal_process.join()loop_process.join()print(multiprocessing.current_process().name + " process is end!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
怎么样,给出的两种 Process 使用方式很像上面的 Thread,只是含义和原理及内存概念有了区别。有了这个基础我们一样可以来看看 Process 的并发锁和多进程数据共享机制使用(与 Thread 的内存区别,任何语言通用),如下:
[本实例完整源码点我获取 demo_multiprocessing_lock.py]
'''
Python 3.X multiprocess 模块演示 Demomultiprocess 锁同步机制及进程数据共享机制
当注释掉 self.lock.acquire() 和 self.lock.release() 后运行代码会发现最后的 count 为 467195 等,并发问题。
当保留 self.lock.acquire() 和 self.lock.release() 后运行代码会发现最后的 count 为 1000000,锁机制保证了并发。
'''
import multiprocessing
from multiprocessing import Processclass LockProcess(Process):def __init__(self, name=None, lock=None, m_count=None):Process.__init__(self, name=name)self.lock = lockself.m_count = m_countdef run(self):self.lock.acquire()print('process is '+multiprocessing.current_process().name+', lock acquired!')count = self.m_count.value;for i in range(0, 100000):count += 1self.m_count.value = countprint('process is '+multiprocessing.current_process().name+', pre lock release!')self.lock.release()if __name__ == '__main__':processes = list()lock = multiprocessing.Lock()m_count = multiprocessing.Manager().Value('count', 0)for i in range(0, 10):process = LockProcess(name=str(i), lock=lock, m_count=m_count)process.start()processes.append(process)for process in processes:process.join()print('Main Process finish, LockProcess.count is:' + str(m_count.value))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
哎呀呀,矫情一把,受不了自己,都和 threading 类似是一个套路,唯一区别都是以为线程和进程本质区别导致的,而使用方式却没区别,所以 multiprocessing 的 Queue 类似 threading 的,不再举例了,具体自己实战吧。
2-4 Python 3.X 并发池
从 Python 并发线程到并发进程一步一步走到这你会发现 Python 标准库给咱们提供的 _thread、threading 和 multiprocessing 模块是非常棒的,但是你有没有想过(在其他语言也会遇到,譬如 C\Java 等)在实际项目中大规模的频繁创建、销毁线程或者进程是一件非常消耗资源的事情,所以池的概念就这么诞生了(空间换时间)。好在 Python3.2 开始内置标准库为我们提供了 concurrent.futures 模块,模块包含了 ThreadPoolExecutor 和 ProcessPoolExecutor 两个类(其基类是 Executor 抽象类,不可直接使用),实现了对 threading 和 multiprocessing 的高级抽象,对编写线程池、进程池提供了直接的支持,我们只用将相应的 tasks 放入线程池、进程池中让其自动调度而不用自己去维护 Queue 来担心死锁问题。
先来看看线程池样例:
[本实例完整源码点我获取 demo_thread_pool_executor.py]
'''
Python 3.X ThreadPoolExecutor 模块演示 Demo
'''
import concurrent
from concurrent.futures import ThreadPoolExecutor
from urllib import requestclass TestThreadPoolExecutor(object):def __init__(self):self.urls = ['https://www.baidu.com/','http://blog.jobbole.com/','http://www.csdn.net/','https://juejin.im/','https://www.zhihu.com/']def get_web_content(self, url=None):print('start get web content from: '+url)try:headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"}req = request.Request(url, headers=headers)return request.urlopen(req).read().decode("utf-8")except BaseException as e:print(str(e))return Noneprint('get web content end from: ' + str(url))def runner(self):thread_pool = ThreadPoolExecutor(max_workers=2, thread_name_prefix='DEMO')futures = dict()for url in self.urls:future = thread_pool.submit(self.get_web_content, url)futures[future] = urlfor future in concurrent.futures.as_completed(futures):url = futures[future]try:data = future.result()except Exception as e:print('Run thread url ('+url+') error. '+str(e))else:print(url+'Request data ok. size='+str(len(data)))print('Finished!')if __name__ == '__main__':TestThreadPoolExecutor().runner()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
再来看看进程池实例,如下:
[本实例完整源码点我获取 demo_process_pool_executor.py]
'''
Python 3.X ProcessPoolExecutor 模块演示 Demo
'''
import concurrent
from concurrent.futures import ProcessPoolExecutor
from urllib import requestclass TestProcessPoolExecutor(object):def __init__(self):self.urls = ['https://www.baidu.com/','http://blog.jobbole.com/','http://www.csdn.net/','https://juejin.im/','https://www.zhihu.com/']def get_web_content(self, url=None):print('start get web content from: '+url)try:headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"}req = request.Request(url, headers=headers)return request.urlopen(req).read().decode("utf-8")except BaseException as e:print(str(e))return Noneprint('get web content end from: ' + str(url))def runner(self):process_pool = ProcessPoolExecutor(max_workers=4)futures = dict()for url in self.urls:future = process_pool.submit(self.get_web_content, url)futures[future] = urlfor future in concurrent.futures.as_completed(futures):url = futures[future]try:data = future.result()except Exception as e:print('Run process url ('+url+') error. '+str(e))else:print(url+'Request data ok. size='+str(len(data)))print('Finished!')if __name__ == '__main__':TestProcessPoolExecutor().runner()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
唉,任何编程语言都是互通的,真的是这样,你只要深入理解一门语言,其他的都很容易,要适应的只是语法;对于 Python 3 的并发其实还有很多知识点需要我们探索的,譬如异步 IO、各种特性锁等等,我们要依据自己的需求去选择使用合适的并发处理,只有这样才是最合适的,总之学习并发就一个套路—–实战观察思考。
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
3 并发爬虫实战
屌爆了吧,上面我们 BB 了那么多关于 Python 并发的东西(虽然很多没 BB 到,毕竟不是专门介绍 Python 3 并发的)就是为了特么的这个 Part 的实战爬虫例子,不然有啥意义呢,废话不多说了,我们之前写的爬虫都是单个主线程的,他们有个很要命的问题就是一旦一个链接爬取卡住不动了,其他就真的只能干瞪眼了,还有一个问题就是我的电脑这么牛逼为毛我的爬虫还是串行爬取那么慢,所以下面两个实例片段就是用来终结这两个诟病的。
3-1 多线程爬虫实战
啥都别和老夫说,上来就是干,上来就扔代码,别再告诉我用多线程演示了,直接上线程池,爬虫不多解释,具体看如下代码的注释或者自己跑一下就明白了。
[本实例完整源码点我获取 spider_multithread.py]
import os
from concurrent.futures import ThreadPoolExecutor
from urllib import request
import re
from urllib.parse import urljoin
from bs4 import BeautifulSoup
'''
使用单独并发线程池爬取解析及单独并发线程池存储解析结果示例
爬取百度百科Android词条简介及该词条链接词条的简介信息,将结果输出到当前目录下output目录
'''class CrawlThreadPool(object):'''启用最大并发线程数为5的线程池进行URL链接爬取及结果解析;最终通过crawl方法的complete_callback参数进行爬取解析结果回调'''def __init__(self):self.thread_pool = ThreadPoolExecutor(max_workers=5)def _request_parse_runnable(self, url):print('start get web content from: ' + url)try:headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"}req = request.Request(url, headers=headers)content = request.urlopen(req).read().decode("utf-8")soup = BeautifulSoup(content, "html.parser", from_encoding='utf-8')new_urls = set()links = soup.find_all("a", href=re.compile(r"/item/\w+"))for link in links:new_urls.add(urljoin(url, link["href"]))data = {"url": url, "new_urls": new_urls}data["title"] = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1").get_text()data["summary"] = soup.find("div", class_="lemma-summary").get_text()except BaseException as e:print(str(e))data = Nonereturn datadef crawl(self, url, complete_callback):future = self.thread_pool.submit(self._request_parse_runnable, url)future.add_done_callback(complete_callback)class OutPutThreadPool(object):'''启用最大并发线程数为5的线程池对上面爬取解析线程池结果进行并发处理存储;'''def __init__(self):self.thread_pool = ThreadPoolExecutor(max_workers=5)def _output_runnable(self, crawl_result):try:url = crawl_result['url']title = crawl_result['title']summary = crawl_result['summary']save_dir = 'output'print('start save %s as %s.txt.' % (url, title))if os.path.exists(save_dir) is False:os.makedirs(save_dir)save_file = save_dir + os.path.sep + title + '.txt'if os.path.exists(save_file):print('file %s is already exist!' % title)returnwith open(save_file, "w") as file_input:file_input.write(summary)except Exception as e:print('save file error.'+str(e))def save(self, crawl_result):self.thread_pool.submit(self._output_runnable, crawl_result)class CrawlManager(object):'''爬虫管理类,负责管理爬取解析线程池及存储线程池'''def __init__(self):self.crawl_pool = CrawlThreadPool()self.output_pool = OutPutThreadPool()def _crawl_future_callback(self, crawl_url_future):try:data = crawl_url_future.result()for new_url in data['new_urls']:self.start_runner(new_url)self.output_pool.save(data)except Exception as e:print('Run crawl url future thread error. '+str(e))def start_runner(self, url):self.crawl_pool.crawl(url, self._crawl_future_callback)if __name__ == '__main__':root_url = 'http://baike.baidu.com/item/Android'CrawlManager().start_runner(root_url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
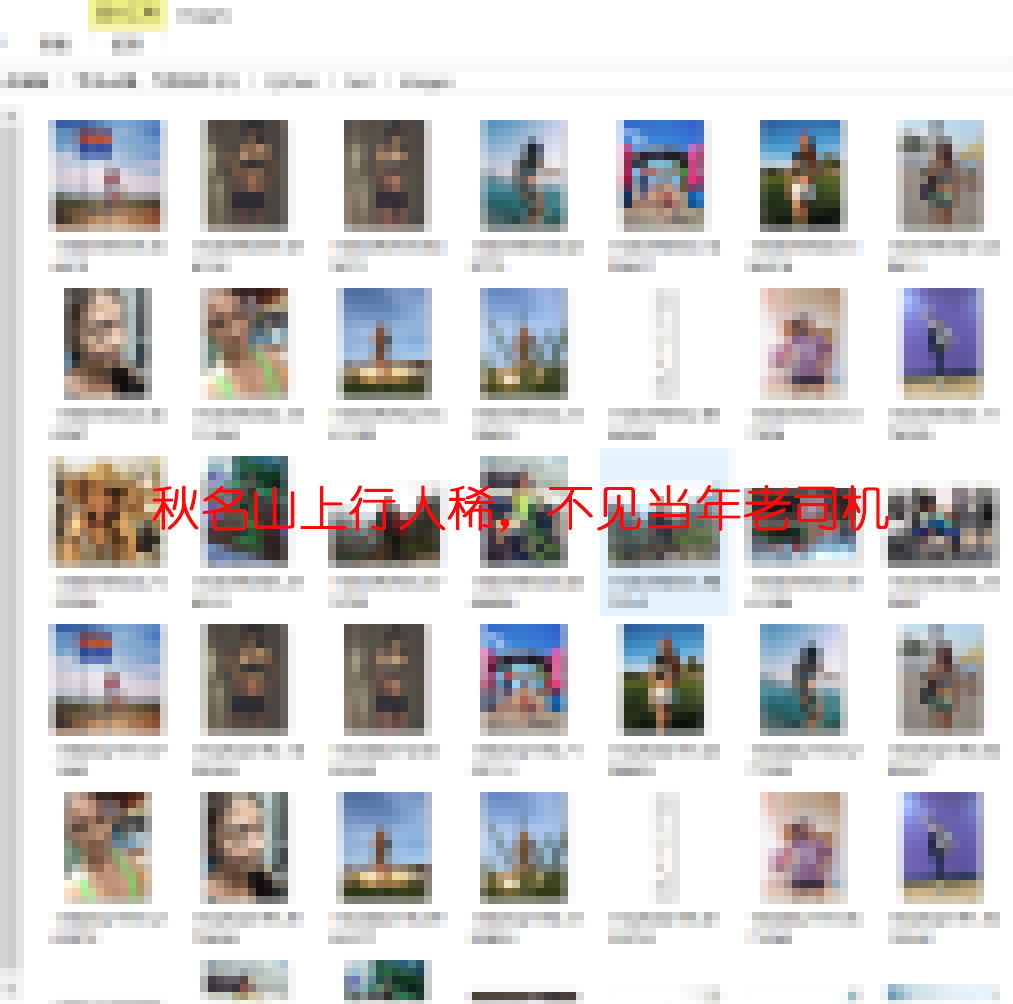
这效率比起该系列第一篇讲的百科爬虫简直高的不能再高了,嗖嗖的,输出结果部分截图如下:
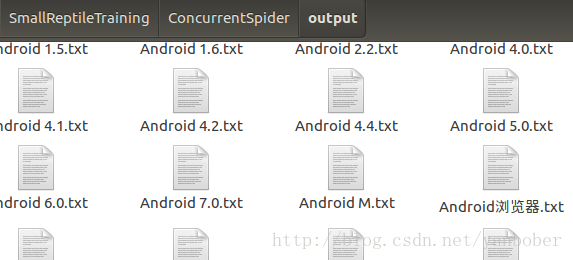
3-2 多进程爬虫实战
啥也不多说,看完多线程爬虫的牛逼效率自然就该看多进程爬虫的牛逼之处了,也一样,别给我说啥概念,上面说的足够多了,下面撸起袖子就是上代码,也别问是啥爬虫,看注释就行,如下:
[本实例完整源码点我获取 spider_multiprocess.py]
import os
from concurrent.futures import ProcessPoolExecutor
from urllib import request
import re
from urllib.parse import urljoin
from bs4 import BeautifulSoup
'''
使用进程池爬取解析及存储解析结果示例
爬取百度百科Android词条简介及该词条链接词条的简介信息,将结果输出到当前目录下output目录
'''class CrawlProcess(object):'''配合进程池进行URL链接爬取及结果解析;最终通过crawl方法的complete_callback参数进行爬取解析结果回调'''def _request_parse_runnable(self, url):print('start get web content from: ' + url)try:headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"}req = request.Request(url, headers=headers)content = request.urlopen(req).read().decode("utf-8")soup = BeautifulSoup(content, "html.parser", from_encoding='utf-8')new_urls = set()links = soup.find_all("a", href=re.compile(r"/item/\w+"))for link in links:new_urls.add(urljoin(url, link["href"]))data = {"url": url, "new_urls": new_urls}data["title"] = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1").get_text()data["summary"] = soup.find("div", class_="lemma-summary").get_text()except BaseException as e:print(str(e))data = Nonereturn datadef crawl(self, url, complete_callback, process_pool):future = process_pool.submit(self._request_parse_runnable, url)future.add_done_callback(complete_callback)class OutPutProcess(object):'''配合进程池对上面爬取解析进程结果进行进程池处理存储;'''def _output_runnable(self, crawl_result):try:url = crawl_result['url']title = crawl_result['title']summary = crawl_result['summary']save_dir = 'output'print('start save %s as %s.txt.' % (url, title))if os.path.exists(save_dir) is False:os.makedirs(save_dir)save_file = save_dir + os.path.sep + title + '.txt'if os.path.exists(save_file):print('file %s is already exist!' % title)return Nonewith open(save_file, "w") as file_input:file_input.write(summary)except Exception as e:print('save file error.'+str(e))return crawl_resultdef save(self, crawl_result, process_pool):process_pool.submit(self._output_runnable, crawl_result)class CrawlManager(object):'''爬虫管理类,进程池负责统一管理调度爬取解析及存储进程'''def __init__(self):self.crawl = CrawlProcess()self.output = OutPutProcess()self.crawl_pool = ProcessPoolExecutor(max_workers=8)self.crawl_deep = 100 self.crawl_cur_count = 0def _crawl_future_callback(self, crawl_url_future):try:data = crawl_url_future.result()self.output.save(data, self.crawl_pool)for new_url in data['new_urls']:self.start_runner(new_url)except Exception as e:print('Run crawl url future process error. '+str(e))def start_runner(self, url):if self.crawl_cur_count > self.crawl_deep:returnself.crawl_cur_count += 1self.crawl.crawl(url, self._crawl_future_callback, self.crawl_pool)if __name__ == '__main__':root_url = 'http://baike.baidu.com/item/Android'CrawlManager().start_runner(root_url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
唉,效果就不多说了,和上面线程池爬取效果类似,只是换为了进程池爬取而已。
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
5 并发爬虫总结
啥都不说,这一篇一下搞得有点不像在介绍并发爬虫,而成了 Python3 并发编程基础了,坑爹啊,无论怎样最后我们还是给出了两个基于 Python3 线程池、进程池的并发爬虫小案例,麻雀虽小,五脏俱全。虽然本篇对并发爬虫(Python3 并发)没有进行深入介绍,但是基本目的达到了,关于并发深入学习不是一两天的功夫,并发在大型项目中是个很有学问的东西,要走的路还有很长,不过有了这篇的铺垫我们就可以自己去摸索分布式爬虫的基本原理,其实就是多进程爬虫,还有就是我们可以自己去摸索下 Python 的异步 IO 机制,那才是核心,那也不是一两篇就能说明白的东西。
^-^当然咯,看到这如果发现对您有帮助的话不妨扫描二维码赏点买羽毛球的小钱(现在球也挺贵的),既是一种鼓励也是一种分享,谢谢!

【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】