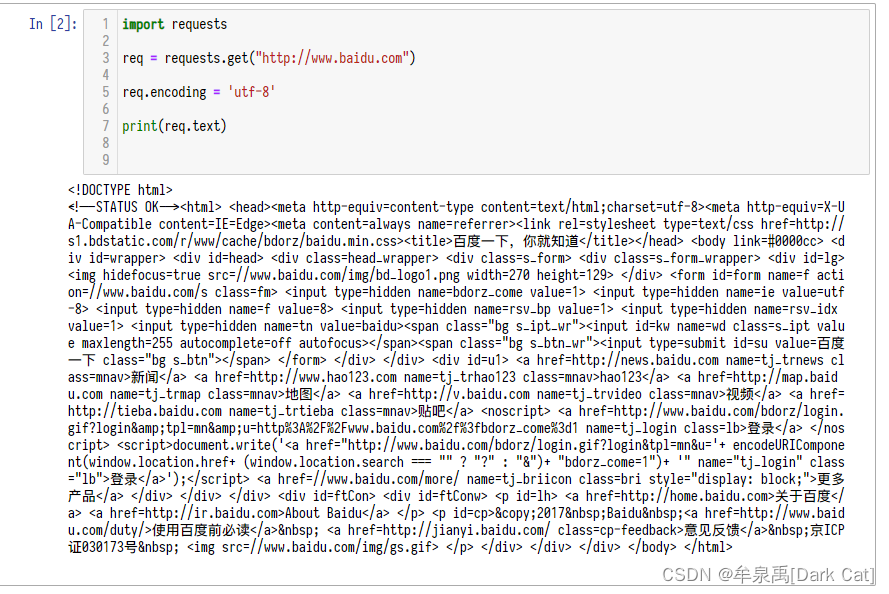
使用BeaufulSoup获取指定class时,结果是将我们所输入的字符串去做模糊匹配,因此会将所有包含的class结果输出,如下图:
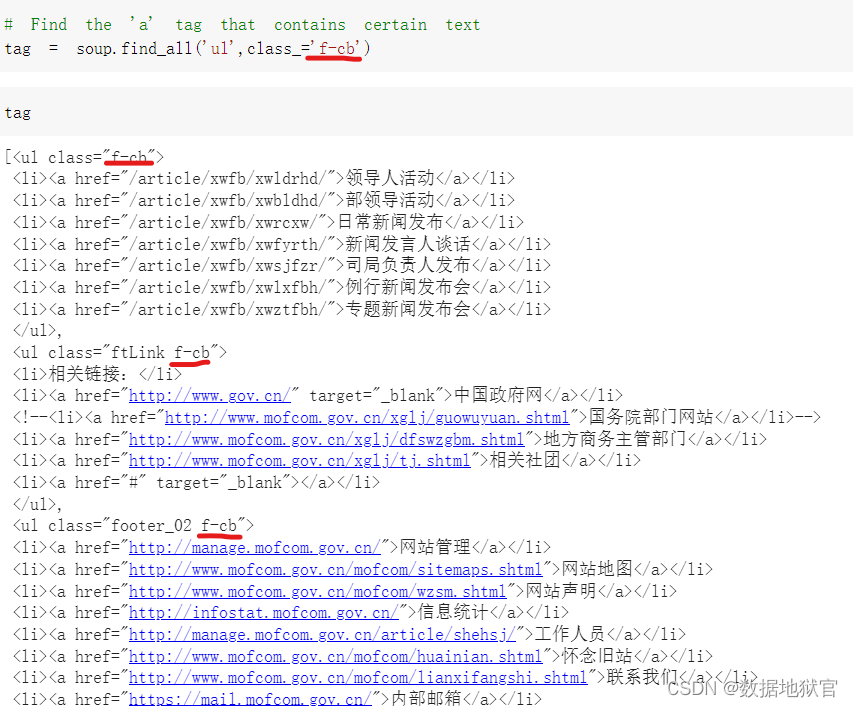
但我们所需要的可能是精确匹配的那一条,这个时候更换一下代码即可:
web_url = 'http://www.mofcom.gov.cn/article/ae/'
# Send a GET request to the URL and store the response
response = requests.get(web_url)
soup = BeautifulSoup(response.content, 'html.parser')#只更改这一条即可
tag = soup.find_all(lambda tag: tag.name == 'ul' and tag.get('class') == ['f-cb'])就会只输出这一条精准匹配的结果
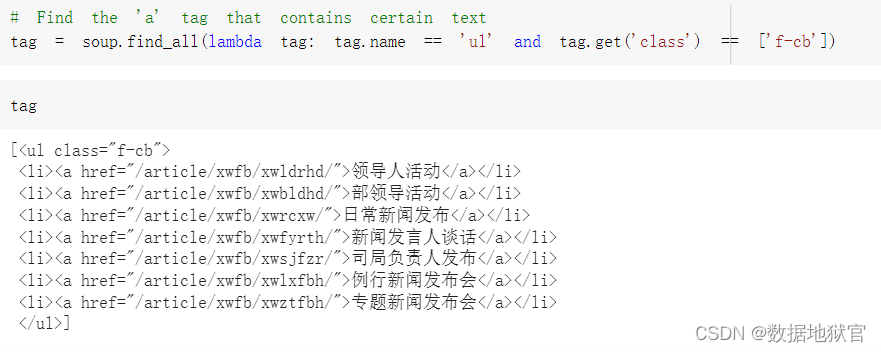
参考文献:
1.Beautifulsoups 有多个class值的标签精确匹配