爬虫基础
文章目录
- 爬虫基础
- 爬虫概述
- Session和Cookie简述
- 1. Session
- 2. Cookie
- 3.关于Session
- 参考资料
爬虫概述
简单来说,爬虫就是从网页上提取信息并保存的自动化程序。
-
爬虫程序的工作:
-
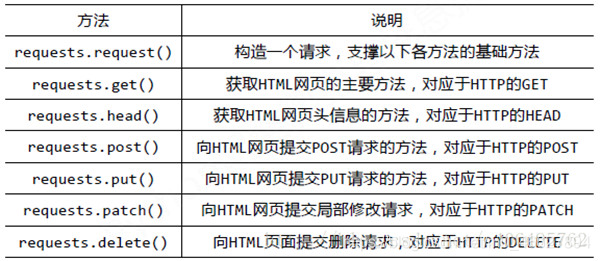
获取网页: 爬虫需要先获取网页信息,即网页源代码进行后续分析。通过Python的urllib,requests等库可以实现。
-
分析网页,提取目标信息: 获得网页源代码后,爬虫会对网页进行解析,进而提取出目标信息。
-
保存数据:将提取出的目标信息进行保存,以便以后使用。
-
Session和Cookie简述
当我们进入某一网站时,可能需要输入登录名和密码。当我们关闭登录过的网站后,再次进入该网页时,并不需要再次输入登录信息(登录名和密码等),这就是Session和Cookie配合作用的结果。
先介绍一些前置概念:
- 静态网页和动态网页:
什么是静态网页? 在网站设计中,使用纯粹的HTML格式编写的网页通常被称为“静态网页”。还有另外一种定义:静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页。
静态网页的优缺点:
优点:加载速度快,编写简单。
缺点:可维护性差,不能根据URL灵活变换显示的内容。
- 什么是动态网页?是指跟静态网页相对的一种网页编程技术。其与静态网页的主要区别是:允许用户与服务后台之间进行数据交互。
- 动态网页的优缺点:
优点:灵活性更强,功能更丰富。(可以动态解析URL中参数的变化,进而呈现不同的内容。)
缺点:①在访问速度上不占优势。②在搜索引擎收录方面不占优势。
注意: 区分一个网页是“动态”还是“静态”,并不是根据其呈现的内容是否具有动感(轮播图,滚动字幕等),而是根据网页是否能与后台数据库进行交互进行数据传递来判断。
无状态HTTP:
HTTP的无状态是指:HTTP协议对事物处理没有记忆能力,或者说服务器不知道客户端是什么状态。
比如:我们登录一个网站,那么我们此时的登录状态便是“登录中”。由于无状态HTTP的特性,当我们再次请求网站时,服务器不知道我们是否登录,所以还要在请求信息中包含我们的登录相关信息,这会导致某些信息多次重复发送。
因此,用于保持HTTP连接状态的技术出现了,分别时
Session和Cookie。
1. Session
Session,中文称之为会话。其本义是指有始有终的一系列动作、消息。例如:打电话时,从拿起电话拨号到挂断电话之间的一系列过程可以成为一个Session。
Session对象用于存储用户Session的所需属性及配置信息。相当于Session对象保存了当前会话的状态。
Session存储在服务器。当用户发送请求到服务器时,如果没有相应的Session对象,那么服务器会新建一个Session对象。
2. Cookie
Cookie,有时也用其复数形式 Cookies。类型为“小型文本文件”,是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息 。
- 用户状态维持
当用户第一次请求服务器时,服务器会返回一个响应头中带有
Set-Cookie字段的响应给客户端,这个字段用于标记用户。客户端会把Cookie保存起来,当下一次向该服务器发送请求时,将保存的Cookie放到请求头中传给服务器。服务器在第一次响应客户端请求时,创建了响应的
Session。客户端的Cookie中保存了对应Session的ID。服务端解析客户端发送来的Cookie可以定位到对应的Session,以此来获取客户端状态。
Cookie的属性结构
以
Google Chrome浏览器为例,进入一个网页(比如:知乎)。按下F12进入开发者模式。左侧Storage项中的Cookies子项中包含了Cookie的详细信息。

Name:
Cookie的名称。创建后不可更改。Value:
Cookie的值。
Domain:指定可以访问的域名。如:设置为.zhihu.com,表示所有以zhihu.com结尾的域名都可访问。
Path:Cookie的使用路径。
Max-Age:Cookie失效的时间,单位为秒。如果为负数,则表示浏览器关闭后就失效。Size:
Cookie的大小
HTTP:略
Secure:略
Cookie的有效时间,有字段中的Max-Age/Expires决定。
3.关于Session
当用户关闭浏览器后,位于服务端的对应的Session不会立刻消失,只有当服务器设定的Session有效时间耗尽后,Session才会由服务器删除,以节省存储空间。
参考资料
- https://baike.baidu.com/item/%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050#6
- https://baike.baidu.com/item/%E9%9D%99%E6%80%81%E7%BD%91%E9%A1%B5/6327183
- https://baike.baidu.com/item/cookie/1119
- Python3网络爬虫开发实战(崔庆才 著)