很多朋友学习Python都是先从爬虫开始,其原因不外两方面:
其一Python对爬虫支持度较好,类库众多,其二语法简单,入门容易,所以两者形影相随,不离不弃。

要使用python语言做爬虫,首先需要学习一下python的基础知识,然后补充学习HTML、CSS、JS、Ajax等相关的知识。
01 如何去学习?
可以按照三步走来理解:获取数据——解析数据——存储数据;

爬虫的第一个步骤就是对所要爬取的网页进行请求,以获取其相应返回的结果,然后再使用一些方法,对响应内容解析,提取想要的内容资源,最后,将提取出来的资源保存起来。
第一步:确定URL;
在爬取的时候内容往往很多,需要注意看一下关键字变化时链接的变化,网页的动静态、日期等。
第二步:发送请求;
建议从建议从requests+Xpath 开始,requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。
第三步:解析网页;
请求资源成功后,需要定位返回的整个网页的源代码,对数据进行清洗。
第四步:保存数据; 整理好数据后保存
爬虫流程个人经验总结大致的3点:
(1)请求数据
请求的数据会有几种可能:
1)很简单的html页面,直接requests就可以请求成功
2)js渲染的页面 (这种页面超多)requests请求一堆js数据 ,模块 selenium (代码基于浏览器运行)
3)需要登录才能获取用的cookie 请求登录
4)json数据,这个就稍微有点难度
(2)数据处理
数据处理会有几种可能:
1)请求的数据是简单的,html结构页面–直接BS4解析就好了
2)请求的数据是json,导入json模块进行解析
3)请求的数据是简单的js渲染的html页面
其实就是js拼写的html,只要把其他无用的数据匹配掉,用正则找到剩下想要的html文本就好了,然后BS4解析。
3)写数据
open方法进行文件打开里面的参数进行文件格式设置,读写文件、编码格式操作。
with open(“XXX.xxx”,“a”,encoding=“utf-8”) as f :f.write(’’‘写入的数据’’’)
文件格式我用过的就是txt、csv 、xml 大部分文本格式都支持的;
-
a–是创建文件 每次写都是重新创建
-
w–是追加
-
a–是读数据
encoding="utf-8"这句话 不加encoding= 在windows系统下会报编码错误;
如果数据量太大就写入到数据库;
了解完爬虫工作的基本流程,大概也可以知道爬虫需要掌握哪些技能基础了。
抓取数据是不是得掌握数据类型?网页解析得懂点网页知识吧?保存数据,文件读写能力、数据库得了解吧?
02 Python基础部分
如果你只是想简单写一些爬虫,那基础语法就够了,想学得更溜一点或者是应用到工作当中的话,最好系统的去学一遍Python,完整的知识体系很重要。
先过一遍最基本的Python知识:
-
常量与变量
-
常用的数据结构:list tuple set dict的基本操作
-
条件控制语句、判断、循环语句
-
字符串
-
正则表达式
-
熟悉各类函数
进阶部分:
-
面对对象编程:类的实现、属性定义、实例、多重继承、slf的理解与使用
-
网络编程
-
Linux基本操作
-
Python文件处理:读写解析
-
Python多进程与线程高并发编程
-
爬虫框架scrapy
-
分布式爬虫大规模抓取

Python模块实现爬虫:
-
urllib3、requests、lxml、bs4 模块大体作用讲解
-
使用requests模块 get 方式获取静态页面数据
-
使用requests模块 post 方式获取静态页面数据
-
使用requests模块获取 ajax 动态页面数据
-
使用requests模块模拟登录网站
-
使用Tesseract进行验证码识别
这里,列了一些python中与爬虫相关的库和框架:
-
urllib
-
Requests
-
Beautiful Soup
-
Xpath语法与lxml库
-
PhantomJS
-
Selenium
-
PyQuery
-
Scrapy
…

好处就是不用自己造轮子,大量的库拿过来就可以用,网上的资料也比较多。
入门书籍的话推荐这本:《Python编程从入门到实践》
非常经典的一门入门书籍,我学Python那会儿也用的这本,包括基础知识和项目两部分,书中内容讲解比较详细精简,每个小结都附带有”动手试一试”环节,不会很枯燥。

03 网页基本知识
① HTTP:超文本传输协议
② HTTPS:HTTP+SSL(安全套接字层)
③ 理解网站的POST GET的一些相关概念,JS的一些基本内容,方便理解动态网页
进行爬虫学习,要懂得网页, 一窍不通肯定不行,HTML中有网页大量的信息,爬虫主要抓取和解析网页的HTML。
HTML(Hyper Text Markup Language)为超文本标记语言,简单来讲,就是一种用于构建网页的编程语言。
一般情况下,网页头部分会定义HTML文档的编码以及网页的标题,而网页体部分则决定着一个网页中的正文内容。
也不用全部都学,但HTTP & HTTPS、网络协议、网络结构(HTML语法、html标签、数据、css样式、js等等什么的)这些还是得知道。
TCP/IP协议、HTTP协议

这些知识能够让你了解在网络请求和网络传输上的基本原理,了解就行,能够帮助今后写爬虫的时候理解爬虫的逻辑。

04 应对反爬
如果网站没有设置反爬措施的话,当然这是 不可能的!反爬和反反爬永远是同时存在的。
大型的网站一般都会设有反爬,掌握一些常用的反爬虫技巧爬取一般的网站问题不大。
常用的反爬技巧:
-
控制ip访问频率
-
字体反加密
-
禁止cookie
-
验证码OCR处理
-
用户代理池技术
……
应对反爬处理手段:
-
控制IP访问次数频率,增加时间间隔
-
Cookie池保存与处理
-
用户代理池技术
-
字体反加密
-
验证码OCR处理
-
抓包
……
个人觉得反爬无外乎:同一ip访问次数、同一用户,即cookie的访问频率/次数
如果说你的IP和用户数是无穷的,那获取数据的方式压根就不用愁,有各种方法可以获取,但实际上不太可能。
IP可以用IP池来解决,但注册的话一个手机号只能注册一个账号,且绑定了手机号,网站对注册这一块还是比较严的。
如果是碰到了最严重的反爬,用固定的访问频率依然不能抓取到你想要的有效数据,那就放弃吧,没要折腾了。
强制登陆+限制同一用户的访问频率/次数,是最严重的反爬。
我一般下面这三个用得比较多:
-
不断添加新的cookie
-
降级访问频率
-
搭建ip池
因为我一般需要爬取的数据都比较简单,所以这几种方法基本可以应付反爬了。
顺便提一句:爬虫攻击网站,这个新手尤其注意!
主要是无限制的向服务器发送请求,造成网站服务器崩溃,就算你没有其他的目的,单纯搞着玩玩,但这跟黑客攻击没有任何区别。
所以还是要注意一下,友好爬虫,别把自己坑进去了!
另外很多人担心的一点:
爬虫本身是不违法的,也没有必要谈爬色变!
但是爬虫作为一门技术,用在什么地方?该怎么用?自己心里还是要有点底。切忌被一时的赚大钱和盲目跟风的好奇心,让自己爬进了狱子里。
robots协议相关说明:

05 爬取路线选择
- 静态网页:
静态网页以及少量表单交互的网站可以使用如下的技术路线:
requests + BeautifulSoup + select css选择器
requests + BeautifulSoup + find_all 进行信息提取
requests + lxml/etree + xpath 表达式
requests + lxml/html/fromstring + xpath 表达式
- 动态网页:
简单动态网页,需要有点击或者提交的可以参考selenium + phantomJS组合使用。

06 爬虫进阶
爬虫框架Scrapy
学到这里一般的爬虫已经不是问题了,但碰到更复杂的情况下,scrapy框架的作用就出来了,能非常方便的解决问题。
Scrapy框架构造

Scrapy可以让爬虫实现爬虫工程化、模块化,除了它的功能非常强大之外,还有强大的selector 能够方便地解析 response,便捷地构建request。
当你学会scrapy框架后,就可以自己去搭建一些爬虫框架了。
分布式爬虫
分布式爬虫通俗的讲就是多台机器多个 spider 对多个 url 的同时处理问题,分布式的方式可以极大提高程序的抓取效率。
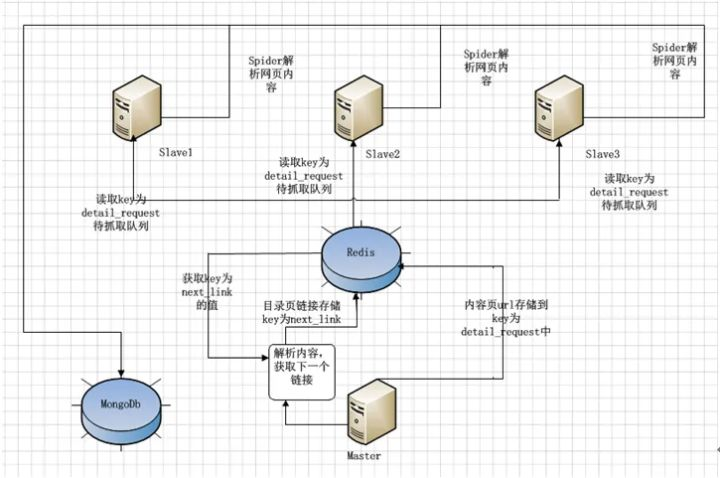
听来虽然很懵,其实也是利用多线程的原理让多个爬虫同时工作,当你掌握分布式爬虫,实现大规模并发采集后,自动化数据获取会更便利。
爬虫学习的书籍可以去看看这本:《python网络爬虫开发实战》

这本书涵盖面较广,爬虫入门到一些比较高级的比如验证码识别、分布式爬虫、专用框架都写得很详细。
所以学完它满足一些基本需求不成问题了,比如批量下载图片、手机app抓包等等。
当你每个步骤都能做到很优秀的时候,你应该考虑如何使你的爬虫达到效率最高,也就是所谓的爬虫策略问题。
爬虫策略学习不是一朝一夕的事情,建议多看看一些比较优秀的爬虫的设计方案。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你,干货内容包括:
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python学习开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python入门学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉Python实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉全套PDF电子书👈
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

👉Python副业兼职学习路线👈

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
读者福利:CSDN大礼包:《Python小白从入门到精通全套学习资料》免费分享 安全链接免费领取