Python 爬虫教程(更新中)
目录
1. 简介
2. 注意
3. xpath+selenium
4. xpath+scarpy(更新中)
5. icrawler 【借助更加便捷操作的pip包】
1. 简介
爬虫主要有2种方式:API(报文)-静态、模拟鼠标点击形式-动态;
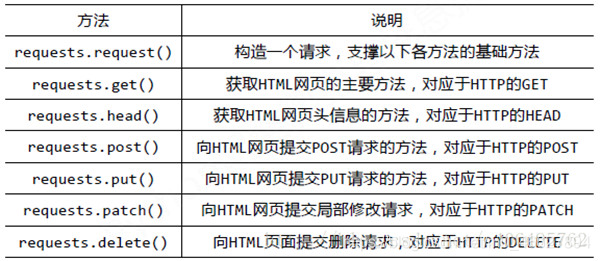
Xpath + Scrapy(API 静态 爬取-直接post get) or Xpath + selenium(点击 动态 爬取-模拟)
Xpath风格可以获取所有的内容,所有的网站都是按照 tree 的形式,那么xpath可以逐层(有条理)分析,再结合各个框架进行分析爬取数据;xpath也可以用re beautifulsoup解析,但xpath更好,xpath教程(百度一下很多);
selenium只是点击形式,因此对应很多header参数可不需要,对于不懂互联网底层原理的人也是比较容易上手的,当然前提是你掌握一点html知识即可!而scrapy则需要很多参数进行设置,进行post get分析
xpath一般在浏览器中使用:F12,点击左上角小箭头,查看对应的html标签,然后在console中输入$x('')查看
【记住:如果用小按钮点击不到的,采用右击->检查!!!】
进一步,对于异步加载ajax,通过network点击你想要操作的,然后可以看到相应的信息(百度一下F12对应的信息介绍)
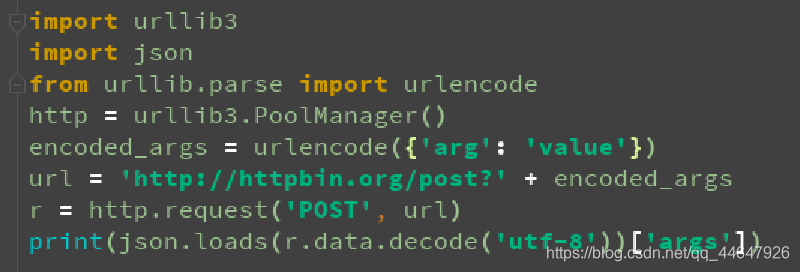
对于iframe等内嵌网页,爬虫也是2种方式获取内容:(1)selenium browser.switch_to.frame();(2)BeautifulSoup+requests 先获取当前页的内容,然后获取想要的iframe的链接,再次get-post请求内容进行解析。

2. 注意
(1)断点续爬;(2)代理(淘宝);(3)sleep一段时间继续;。。。
3. xpath+selenium
(1) 百度图片爬虫
'''
注释:@author is leilei百度图片爬虫,采用selenium模拟鼠标点击形式1. 将要搜索的文本表示成list2. 打开百度图片官网,输入文本,搜索3. 逐条下载对应的图片
注:本代码支持断点续爬!
'''import os
import uuid
import time
import random
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys # 键盘类def send_param_to_baidu(name, browser):''':param name: str:param browser: webdriver.Chrome 实际应该是全局变量的:return: 将要输入的 关键字 输入百度图片'''# 采用id进行xpath选择,id一般唯一inputs = browser.find_element_by_xpath('//input[@id="kw"]')inputs.clear()inputs.send_keys(name)time.sleep(1)inputs.send_keys(Keys.ENTER)time.sleep(1)returndef download_baidu_images(save_path, img_num, browser):''' 此函数应在:param save_path: 下载路径 str:param img_num: 下载图片数量 int:param browser: webdriver.Chrome:return:'''if not os.path.exists(save_path):os.makedirs(save_path)img_link = browser.find_elements_by_xpath('//li/div[@class="imgbox"]/a/img[@class="main_img img-hover"]')img_link[2].click()# 切换窗口windows = browser.window_handlesbrowser.switch_to.window(windows[-1]) # 切换到图像界面time.sleep(random.random())for i in range(img_num):img_link_ = browser.find_element_by_xpath('//div/img[@class="currentImg"]')src_link = img_link_.get_attribute('src')print(src_link)# 保存图片,使用urlibimg_name = uuid.uuid4()urllib.request.urlretrieve(src_link, os.path.join(save_path, str(img_name) + '.jpg'))# 关闭图像界面,并切换到外观界面time.sleep(random.random())# 点击下一张图片browser.find_element_by_xpath('//span[@class="img-next"]').click()time.sleep(random.random())# 关闭当前窗口,并选择之前的窗口browser.close()browser.switch_to.window(windows[0])returndef main(names, save_root, img_num=[1000,], continue_num=0, is_open_chrome=False):''':param names: list str:param save_root: str:param img_num: int list or int:param continue_num: int 断点续爬开始索引:param is_open_chrome: 爬虫是否打开浏览器爬取图像 bool default=False:return:'''options = webdriver.ChromeOptions()# 设置是否打开浏览器if not is_open_chrome:options.add_argument('--headless') # 不打开浏览器else:prefs = {"profile.managed_default_content_settings.images": 2} # 禁止图像加载options.add_experimental_option("prefs", prefs)# 欺骗反爬虫,浏览器可以打开,但是没有内容options.add_argument("--disable-blink-features=AutomationControlled")browser = webdriver.Chrome(chrome_options=options)browser.maximize_window()browser.get(r'https://image.baidu.com/')time.sleep(random.random())assert type(names) == list, "names参数必须是字符串列表"assert continue_num <= len(names), "中断续爬点需要小于爬虫任务数量"if type(img_num) == int:img_num = [img_num] * len(names)print(img_num)elif type(img_num) == list:print(img_num)else:print("None, img_num 必须是int list or int")returnfor i in range(continue_num, len(names)):name = names[i]save_path = os.path.join(save_root, str(names.index(name))) # 以索引作为文件夹名称send_param_to_baidu(name, browser)download_baidu_images(save_path=save_path, img_num=img_num[i], browser=browser)# 全部关闭browser.quit()returnif __name__=="__main__":# main(names=['施工人员穿反光衣', '反光衣',],\# save_root=r'F:\Reflective_vests',\# img_num=500)main(names=['森林积雪', '道路积雪', '建筑积雪', '山上积雪', '草原下雪', '小区积雪', '雪人堆', '蓝天白云下的建筑道路积雪'],\save_root=r'F:\DataSets\snow\positive',\img_num=[300, 300, 300, 100, 100, 100, 50, 50],\continue_num=7)######################################################################
4. xpath+scarpy(更新中)
scrapy有比较严格的格式要求,按照要求来做,即可。
英文最新版本:2.3版本;(尽量去看英文教程)
5. icrawler 【借助更加便捷操作的pip包】
'''底层肯定是scrapy静态报文,谷歌引擎不可以,百度最快,bing速度有点慢!直接pip install icrawlergithub 搜索即可若想搜索多个关键词,可以遍历for循环;同时icrawler也可对图像链接list、txt直接遍历: UrlListCrawler
'''
from icrawler.builtin import GoogleImageCrawler
from icrawler.builtin import BaiduImageCrawler
from icrawler.builtin import BingImageCrawler
# storage字典格式'root_dir': 保存路径
crawler = BaiduImageCrawler(storage={'root_dir': r'F:\temp\cat'})
crawler.crawl(keyword='cat', max_num=10)