Author:baiyucraft
BLog: baiyucraft’s Home
IDE:PyCharm
其实对于Python,一直想去学习,但一直没有足够的的时候去研究,这次趁疫情在家的时间,对于Python好好的研究研究。算是作为自己对于Python3以及Python爬虫的学习笔记,对于以后有一个很好的回顾 。
希望能和大家一起交流,一起进步!!!
一、初步准备
1.Python3开发环境的搭建
官网下载Python3:https://www.python.org/downloads/windows,一般就下载executable installer的版本,x86是32位的电脑,x86-64是64位电脑
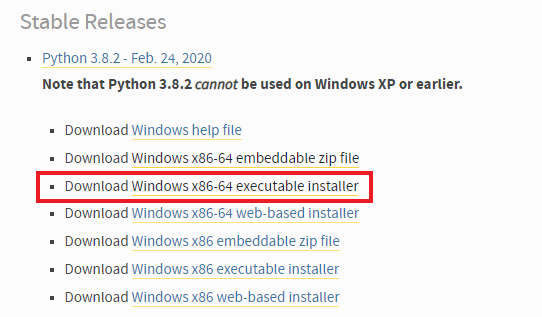
最新的稳定版的Python版本是3.8.2,由于自己电脑上的Python是以前装的,所以在这不阐述如何安装,如果不会安装可以看菜鸟教程的教程:https://www.runoob.com/python3/python3-install.html
2.IDE的安装
原来是想用VS Code来作为IDE的,毕竟写前端开发的时候就是用的VS Code,而且VS Code也有Python插件支持,但是用了以后发现并不是那么的好用。特别是在用Pylint作为代码检查工具时,导入第三方库时需要配置文件,特别麻烦。
于是自己就选择了PyCharm,作为JetBrains公司打造的Python IDE,使用的体验还是非常不错的,官网下载链接:http://www.jetbrains.com/pycharm/download,具体的安装过程在这也不做阐述
3.Python3基础知识学习
1) 菜鸟教程的Python3教程文档:https://www.runoob.com/python3
如果曾经学过一门编程语言,完全可以通过菜鸟教程的Python3教程来完成自学。
2) 鱼C工作室的Python教程视频:http://www.fishc.com
小甲鱼老师的Python零基础教学对于新手还是比较友好的
二、网络爬虫的基本认识
网络爬虫又叫网页蜘蛛,原来以为英文名应该叫web spider,没想到在百度百科将其定义为web crawler,具体的解释可以看百度百科,太过复杂,作为初学者的我们也看不懂,那从最简单的开始分析。
众所周知,我们打开浏览器都需要在地址栏输入网址的,这个网址就是一个URL,例如:https://www.baidu.com,这就是个URL,那么URL的定义是什么呢?
全称统一资源定位系统URL(Uniform Recourse Locater),是因特网的万维网服务程序程序上用于指定信息位置的表示方法。常见的URL协议有ftp(文本传输协议),http(超文本传输协议)等等。而我们一般的Python网络爬虫所针对的就是http。对于http协议,它的一般格式如下:
http:// <host>:<port>/<path>?<searchpart>
URL的格式由部分构成:
1) 协议:一般有两种,一种是http,一种是https,百度用的就是https协议,具体区别自行百度
2) host:表示主机名,百度的主机名就是www.baidu.com
3) port:表示端口号,一般来说是80端口,若是80端口可以省略
4) path:表示主机资源的具体位置,和磁盘地址类似的概念
了解了URL的概念,我们就开始网络爬虫的简单实例练习
三、Python简单爬虫实例
在Python3中,有个叫urllib的处理包,这个包集合了用于URL的模块,如下所示:
urllib 是一个收集了多个用到 URL 的模块的包:
urllib.request 打开和读取 URL
urllib.error 包含 urllib.request 抛出的异常
urllib.parse 用于解析 URL
urllib.robotparser 用于解析 robots.txt 文件
我们用到的就是其中的urllib.request这个库,首先我们得导入库(下面给出两种导入库的方式):
# -*- codeing: UTF-8 -*- #规定编码方式
import urllib.request #使用该库时:urllib.request.函数名()
from urllib import request #使用该库时:request.函数名()
导入库后要运用库的接口函数了,我们使用的urllib.request.urlopen()这个函数,通过这个函数可以模拟浏览器打开网站的行为,读取并打印网站信息
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
我们可以带看到urlopen的第一个参数是url,于是我们可以写出最简单的爬虫程序
# -*- codeing: UTF-8 -*- #规定编码方式
from urllib import request #使用该库时:request.函数名()if __name__ == '__main__': #相当于主函数,不写也可以res = request.urlopen('http://fanyi.youdao.com') #有道翻译的界面html = res.read()print(html)
将该程序命名为test.py,在PyCharm中运行,得到如下结果:
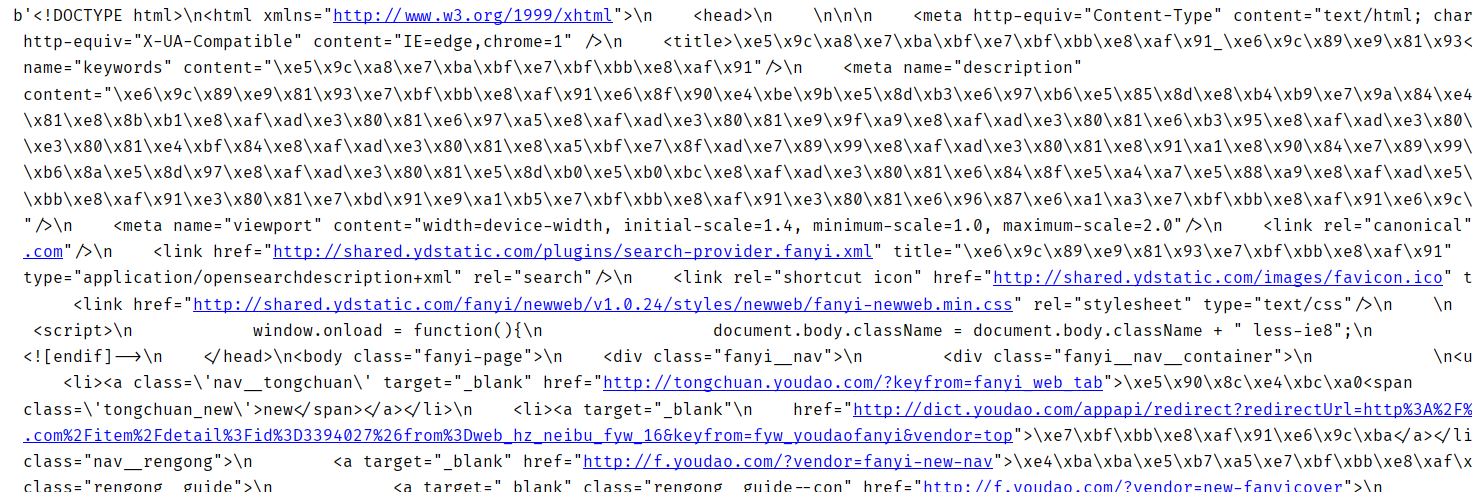
这时候就奇怪了,明明程序并没有报错,为啥是一堆奇怪的代码,有过HTML基础的会觉得这个样式和我们的HTML文本差不多
其实是urlopen返回的是是一个类文件对象,我们read()方法来获取网页的所有内容,但是这个内容是bytes类型的,我们可以发现在输出值的开头有b‘开头,代表数据类型是bytes,这时候需要对数据进行编码,编码的方法是decode()
# -*- codeing: UTF-8 -*- #规定编码方式
from urllib import request #使用该库时:request.函数名()if __name__ == '__main__': #相当于主函数,不写也可以res = request.urlopen('http://fanyi.youdao.com') #有道翻译的界面html = res.read()html_t = html.deprint(html_t)
这时候我们可以看到输出的值就为规范的HTML文档:

这就是浏览器所接受到的信息,只不过我们的浏览器在接收到这个信息的时候,对于这些信息进行了处理,转换成图形界面信息供我们来浏览,这些代码我们其实也可以在浏览器中看到,在浏览器界面按f12可以调出浏览器的开发者工具,以百度为例子,下图是谷歌浏览器的开发者工具:
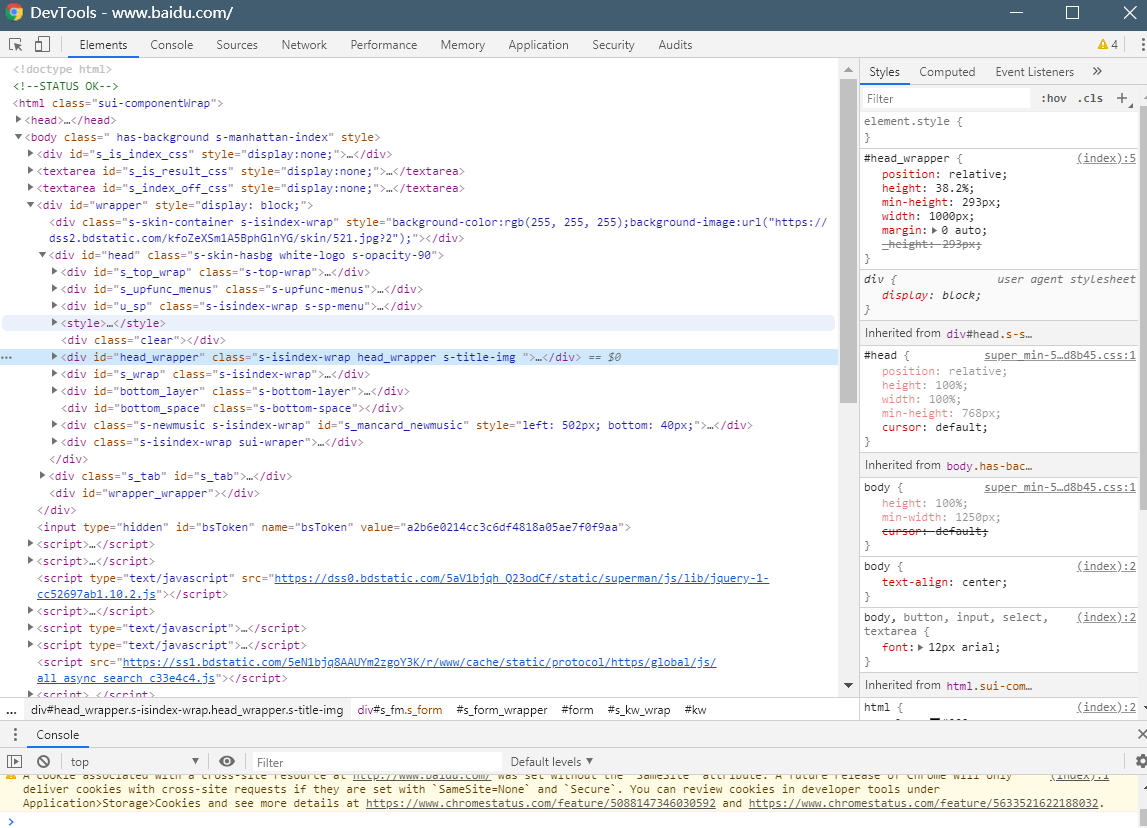
我们可以在本地对于这些信息进行改写,当然这个不会影响服务器中的数据
通过这个工具,我们可以看出这个网页的编码方式,从哪里能看出来呢?
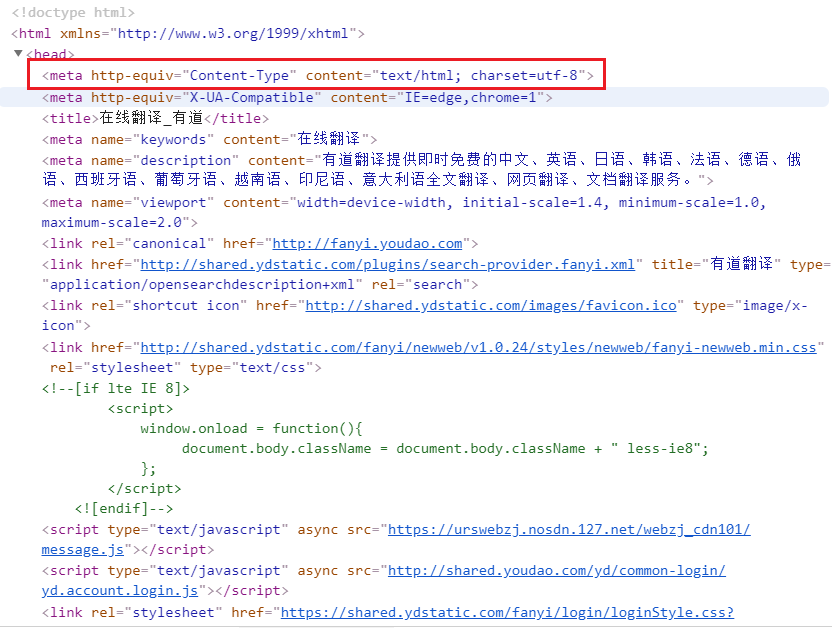
可以看到在<meta>标签里有个charser='utf-8',这就是我们decode('utf-8')的由来
理解了这些内容,我们第一次的学习就这样愉快结束了!!!