Python爬虫(三)
一、ajax请求豆瓣电影第一页
# get请求
# 获取豆瓣电影的第一页数据并保存
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers = {'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}# 请求对象的定制
request =urllib.request.Request(url=url,headers=headers)
# 获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
# 数据下载到本地
# open方法默认情况下使用gbk编码,若想保存汉字,则需要在open方法中指定编码格式为utf-8
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)fp = open('douban.json','w',encoding='utf-8')
fp.write(content)
# 这两行等价于
with open('douban1.json','w',encoding='utf-8') as fp:fp.write(content)

二、ajax请求豆瓣电影前十页
# 豆瓣电影前十页
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=0&limit=20# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=20&limit=20# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=40&limit=20# page 1 2 3 4
# start 0 20 40 60 start = (page - 1) * 20
import urllib.parse
def create_request(page):base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'data = {'start' : (page - 1)*20,'limit' : 20 ,}data = urllib.parse.urlencode(data)url = base_url + dataprint(url)headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'}
# 1.请求对象的定制
# request = urllib.request.Request()# 程序入口
if __name__ == '__main__':start_page = int(input('请输入起始页码'))end_page = int(input('请输入结束页码'))for page in range (start_page , end_page + 1):# 每一页都有请求对象的定制create_request(page)# print(page)

完整案例:
import urllib.parse
import urllib.request
def create_request(page):base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'data = {'start' : (page - 1)*20,'limit' : 20 ,}data = urllib.parse.urlencode(data)url = base_url + dataprint(url)headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'}# 1.请求对象的定制request = urllib.request.Request(url = url , headers = headers)return request
def get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return content
def down_load(page,content):with open('douban_' + str(page)+'.json' ,'w',encoding='utf-8') as fp:fp.write(content)
# 程序入口
if __name__ == '__main__':start_page = int(input('请输入起始页码'))end_page = int(input('请输入结束页码'))for page in range (start_page , end_page + 1):# 每一页都有请求对象的定制request = create_request(page)# 2.获取响应的数据content = get_content(request)# 3.下载数据down_load(page,content)# print(page)
三、ajax的post请求肯德基官网
# 第一页
# https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 黄山
# pid:
# pageIndex: 1
# pageSize: 10# 第二页
# https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 黄山
# pid:
# pageIndex: 2
# pageSize: 10import urllib.request
import urllib.parse
def creat_request(page):base_url = 'https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'data = {'cname': '黄山','pid': '','pageIndex': page,'pageSize': '10'}data = urllib.parse.urlencode(data).encode('utf-8')headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'}request = urllib.request.Request(url=base_url,headers=headers,data=data)return request
def get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return content
def down_load(page,content):with open('kfc_'+str(page)+'.json','w',encoding='utf-8') as fp:fp.write(content)
if __name__ == '__main__':start_page = int(input('请输入起始页'))end_page = int(input('请输入结束页'))for page in range(start_page,end_page + 1):# 请求对象定制request = creat_request(page)# 获取网页源码content = get_content(request)# 下载down_load(page,content)

四、urllib异常
URLErrorHTTPError
-
HTTPError类是URLError类的子类
-
导入包urllib.error.HTTPError urllib.error.URLError(或者直接导入urllib.error)
-
http错误:http错误是针对浏览器无法链接到服务器而增加出来的错误提示,引导并告诉浏览器该页是哪里出现问题。
-
通过urllib发送请求的时候,有可能会发送失败,若想要代码更加健壮,可以通过try-except 进行捕获,异常有两类,URLErrorHttpError
import urllib.request
import urllib.error
url = ‘https://blog.csdn.net/sulixu/article/details/1198189491’
headers = {
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44’
}
try:
request = urllib.request.Request(url=url ,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode(‘utf-8’)
print(content)
except urllib.error.HTTPError:
print(‘系统正在升级’)
except urllib.error.URLError:
print(‘系统还在升级…’)
五、微博的cookie登录
# 个人信息页面是utf-8,但还是报编码错误,由于是没有进入到个人信息页面,网页拦截到登录页面
# 而登录页面并非utf-8编码import urllib.request
url = 'https://weibo.com/u/6574284471'
headers = {# ':authority':' weibo.com',# ':method':' GET',# ':path':' /u/6574284471',# ':scheme':' https','accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',# 'accept-encoding':' gzip, deflate, br','accept-language':' zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control':' max-age=0','cookie: XSRF-TOKEN=6ma7fyurg-D7srMvPHSBXnd7; PC_TOKEN=c80929a33d; SUB=_2A25Pt6gfDeRhGeBL7FYT-CrIzD2IHXVsxJ7XrDV8PUNbmtANLU_ikW9NRsq_VXzy15yBjKrXXuLy01cvv2Vl9GaI; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWh0duRqerzYUFYCVXfeaq95JpX5KzhUgL.FoqfS0BE1hBXS022dJLoIp-LxKqL1K-LBoMLxKnLBK2L12xA9cqt; ALF=1687489486; SSOLoginState=1655953487; _s_tentry=weibo.com; Apache=4088119873839.28.1655954158255; SINAGLOBAL=4088119873839.28.1655954158255; ULV=1655954158291:1:1:1:4088119873839.28.1655954158255':'; WBPSESS=jKyskQ8JC9Xst5B1mV_fu6PgU8yZ2Wz8GqZ7KvsizlaQYIWJEyF7NSFv2ZP4uCpwz4tKG2BL44ACE6phIx2TUnD3W1v9mxLa_MQC4u4f2UaPhXf55kpgp85_A2VrDQjuAtgDgiAhD-DP14cuzq0UDA==',#referer 判断当前路径是不是由上一个路径进来的,一般情况下,制作用于图片防盗链'referer: https':'//weibo.com/newlogin?tabtype=weibo&gid=102803&openLoginLayer=0&url=https%3A%2F%2Fweibo.com%2F','sec-ch-ua':' " Not A;Brand";v="99", "Chromium";v="102", "Microsoft Edge";v="102"','sec-ch-ua-mobile':' ?0','sec-ch-ua-platform':' "Windows"','sec-fetch-dest':' document','sec-fetch-mode':' navigate','sec-fetch-site':' same-origin','sec-fetch-user':' ?1','upgrade-insecure-requests':' 1','user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44',
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen((request))
# 获取响应的数据
content = response.read().decode('utf-8')
# print(content)
# 将数据保存到本地
with open('file/weibo.html','w',encoding='utf-8') as fp:fp.write(content)
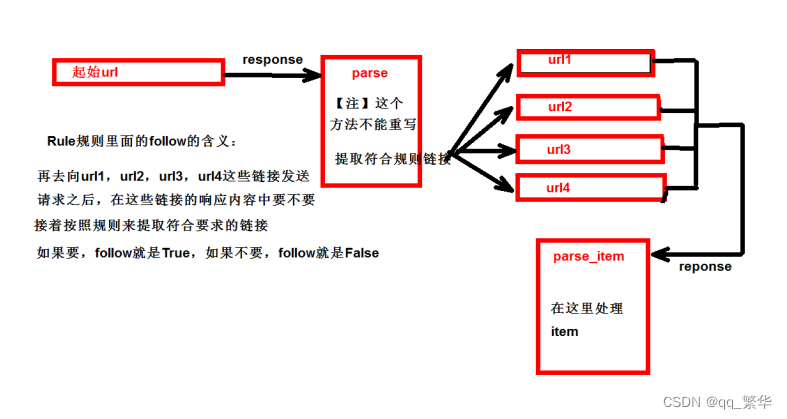
六、Handler处理器的基本使用
作用:
urllib.request.urlopen(url)—>无法定制请求头
request = urllib.request.Request(url=url,headers=headers,data=data)—>可以定制请求头
Handler—>定制更高级的请求头(随着业务逻辑的拓展,请求对象的定制已经满足不了我们的需求,例如:动态Cookie和代理不能使用请求对象的定制i)
# 需求:使用handler访问百度获取网页源码
import urllib.request
url = 'http://www.baidu.com'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
request = urllib.request.Request(url=url,headers=headers)
# handler build_opener open
# (1) 获取handler对象
handler = urllib.request.HTTPHandler()
# (2) 获取opener对象
opener = urllib.request.build_opener(handler)
# (3) 调用open方法
response = opener = open(request)
content = response.read().decode('utf-8')
print(content)
七、代理服务器
在快代理https://free.kuaidaili.com/free/获取免费IP和端口号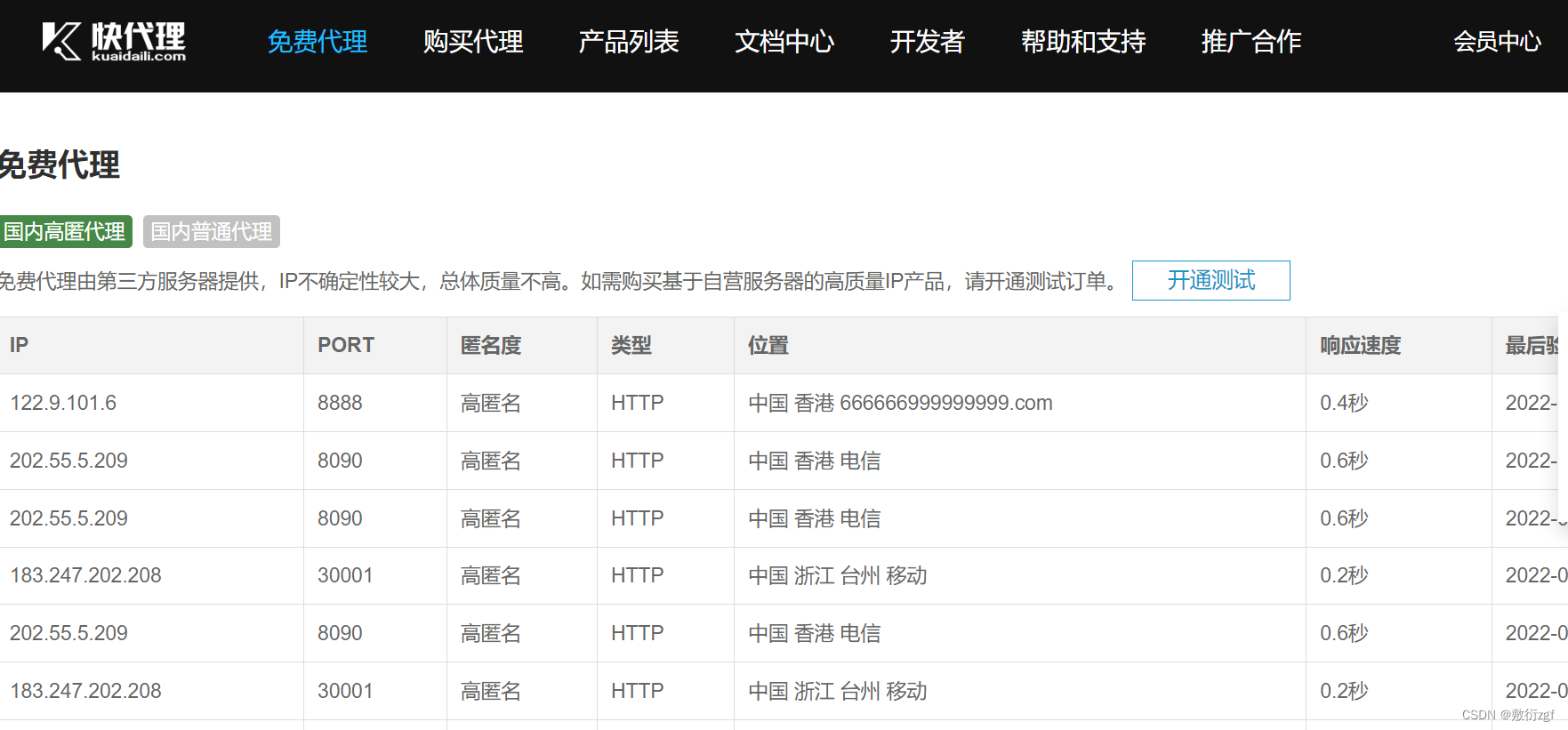
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
request = urllib.request.Request(url=url,headers=headers)
# response = urllib.request.urlopen(request)
# handler builder_open open
posix = {'http': '103.37.141.69:80'
}
handler = urllib.request.ProxyHandler(proxies = posix)
opener = urllib.request.build_opener(handler)
response = opener.open(request)content = response.read().decode('utf-8')
with open('file/daili.html','w',encoding='utf-8') as fp:fp.write(content)
八、代理池
import urllib.request
import random
url = 'http://www.baidu.com/s?wd=ip'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
proxies_pool = [{ 'http': '103.37.141.69:8011' },{ 'http': '103.37.141.69:8022' },{ 'http': '103.37.141.69:8033' }
]
proxies = random.choice(proxies_pool) //随机选择IP地址
# print(proxies)
request = urllib.request.Request(url=url,headers=headers)
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('file/daili.html','w',encoding='utf-8') as fp:fp.write(content)
九、xpath插件
1.安装xpath插件:https://www.aliyundrive.com/s/YCtumb2D2J3 提取码: o4t2
2.安装lxml库
pip install lxml -i https://pypi.douban.com/simple
3.案例解析xpath
①解析本地文件 etree.parse
## 解析xpath 帮助用户获取网页部分源码的一种方式
from lxml import etree
# 一、解析本地文件 etree.parse
tree = etree.parse('file/xpath解析本地文件.html')
# print(tree)
# tree.xpath('xpath路径')# 1.查找ul下面的li
# //:查找所有子孙节点,不考虑层级关系
# /:找直接子节点
# li_list = tree.xpath('//body/ul/li')
# print(li_list)
# 判断列表长度
# print(len(li_list))# 2.查找所有有id属性的li标签
# li_list = tree.xpath('//ul/li[@id]')# text()可以获取标签中的内容
# li_list = tree.xpath('//ul/li[@id]/text()')
# 查找id为l1的li标签 注意添加引号
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# 查找到id为l1的li标签的class的属性值
# li_list = tree.xpath('//ul/li[@id="l1"]/@class')
# 模糊查询 id中包含l的标签
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')# 查询id的至以l开头的li标签
# li_list = tree.xpath('//ul/li[starts-with(@id,"l")]/text()')
# 查询id为l1和class为c1的 逻辑运算
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text() ')
print(len(li_list))
print(li_list)
②服务器响应的数据 response.read().decode(‘utf-8’) etree.HTML()
import urllib.request
url = 'http://www.baidu.com/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 解析网页源码 来获取想要的数据
from lxml import etree
# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的数据 xpath的返回值是一个列表类型的数据
result = tree.xpath('//input[@id ="su"]/@value')[0]
print(result)
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦