问题背景:
-
随着利率市场化改革推进,银行业整体面临息差收窄的压力,不少银行将中间业务收入作为新的利润增长点。其中,以招商银行为代表的一批大型股份制银行,更是将大财富管理模式做到了极致,中间收入占比的增加既有利于银行利润的稳定健康增长,也有利于扩大银行的品牌影响力,建造属于自己品牌的私域流量。
-
银行客户经理,是为银行创造中间收入的主力军。但是,以笔者在银行的从业经验来看,一名客户经理名下管户人数往往多达千人,而每人每个工作日可拨打的有效电话只有20个左右,毫无目的的从千人之中寻找产品的目标客户无异于大海捞针。因此,在客群管理方面,提前预测产品的潜在购买客户对于减轻客户经理工作压力,提升工作效率意义巨大。
文章概述
- 本文将先对营销结果进行数据探索性分析,理清客户的分布情况,以及客户的各个特征对于是否购买存款产品的影响。之后用XGboost对数据集做训练,建模,评估。最终将基于模型和探索性分析结果,给出可采取的精准营销措施。
文章目录
- 问题背景:
- 文章概述
- 数据说明
- 模型部分
- 数据和库的导入
- 数据清洗
- 分析结果
- 数据探索性分析
- 各个数值型特征的分布分析:
- 年龄的分布情况
- 收支情况分布
- 联系日期的分布
- 联系时长的分布情况
- 距离上次联系天数的分布
- 小结:
- 探索不同变量对是否购买存款的影响
- 工作情况会否影响是否存款?
- 分析结果:
- 猜想:
- 婚姻状况会否影响存款购买
- 分析结果:
- 猜想:
- 教育水平会否影响存款购买
- 分析结果
- 猜想
- 债务,房贷,个贷会否影响存款购买
- 分析结果:
- 猜想:
- 聊天时长对购买的影响
- 分析结果
- 猜想
- 分析结果:
- 猜想:
- 分析结果:
- 年龄的影响
- 分析结果
- 猜想
- 潜在客户预测模型建立
- 预测前的数据处理
- 模型训练
- 模型结果
- 总结
数据说明
- 因数据敏感性问题,在本文中,笔者以葡萄牙银行机构的营销电话记录作为数据源
:
DataCastle-数据科学创新与实践平台
| 标签 | 说明 |
|---|---|
| index | 行的索引 |
| age | 年龄 |
| job | 职业 |
| marital | 婚姻状况 |
| education | 受教育程度 |
| default | 是否有违约信用 |
| balance | 收支情况 |
| housing | 是否有住房贷款 |
| loan | 是否有个人贷款 |
| contact | 联系方式 |
| day | 上一次联系的日期 |
| month | 上一次联系的月份 |
| duration | 上一次联系的持续时间,以秒为单位 |
| campaign | 活动期间联系客户的次数 |
| pdays | 距离上一次联系过了多少天 |
| previous | 在此次活动之前同该客户的联系数量 |
| poutcome | 上一次营销活动的结果 |
| y | 客户是否订阅了定期存款 |
模型部分
数据和库的导入
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as snsfrom sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.metrics import roc_auc_score, f1_score, precision_score, recall_score, accuracy_score, auc, roc_curveimport optunaimport xgboost as xgb
warnings.filterwarnings('ignore')
data = pd.read_csv(r'./bank/bank-full.csv')
数据清洗
- 查看数据样式
data.head()

data.info()

我们看到这里的数据和特征名存在一些特殊字符,先将这些特殊符号去除。
data = data.rename(columns=lambda x: x.replace("'","").replace('"','')).replace(" ","")
for col in data.select_dtypes( 'object').columns:data[col] = data[col].apply(lambda x:x.replace("'","").replace('""','').replace('"',''))
同时将index和age分开:
data['index,age'] = data['index,age'].str.split(',',expand=True)[1]
data.rename(columns={'index,age':'age'},inplace=True)
data_clean = data.copy()
data_clean.age = data_clean.age.astype('int8')
data_clean.head()

font = {'family':'SimHei','size':'15'}
plt.rc('font',**font)
plt.rc('axes',unicode_minus='False')
plt.figure(figsize = (10,5))
corr_matrix = data_clean.corr()
sns.heatmap(corr_matrix, cmap='RdBu', annot=True, vmin=-1, vmax=1)
plt.title('各变量相关系数')
plt.show()
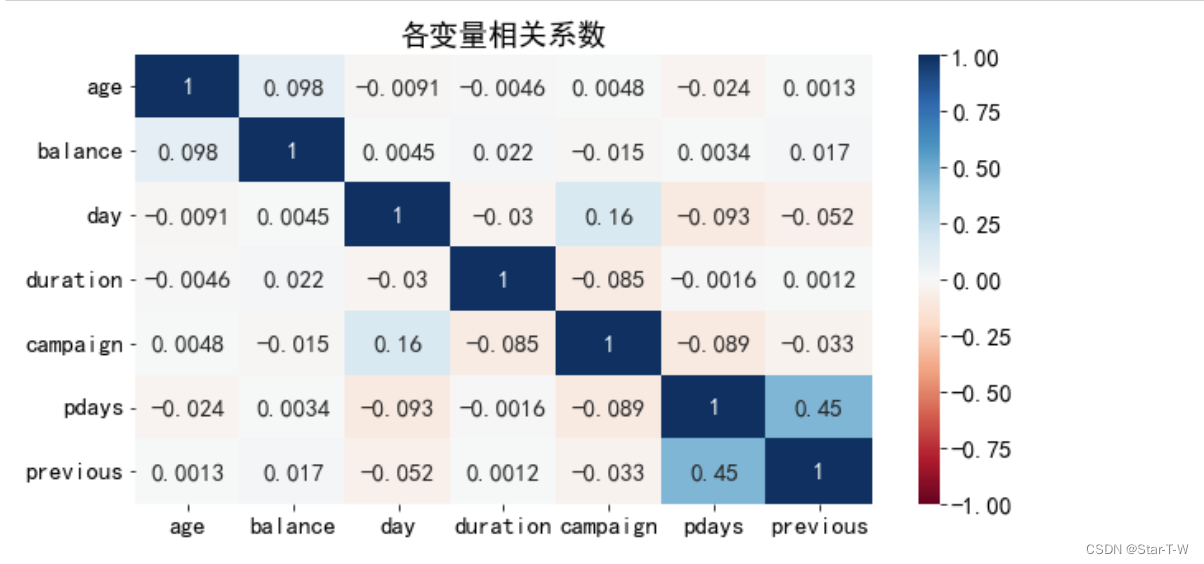
分析结果
- 从协方差矩阵来看,仅有pdays和previous之间有较强的相关性,直接的意思是越久没联系的客户,过去联系的次数越多。出现这一情况可能是由于当下银行更多的将精力放在挖掘新客户上。而对于其他特征,仅从协方差矩阵很难得到什么实质信息。
数据探索性分析
在这一部分,笔者将对各个特征的分布情况,以及各个特征对于用户是否购买的影响情况两方面着手进行探索性分析。
定义分布直方图绘图函数方便后续分析:
def dist_plot(data, col, title):fig, ax = plt.subplots(2, 1, sharex=True, figsize=(8,5),gridspec_kw={"height_ratios": (.2, .8)})ax[0].set_title(title,fontsize=18)sns.boxplot(x=col, data=data, ax=ax[0],color = "#1D8EF5")ax[0].set(yticks=[])sns.histplot(x=col, data=data, ax=ax[1],color = "#33AAFF", edgecolor="#1D1EA2")ax[1].set_xlabel(col, fontsize=16)plt.axvline(data[col].mean(), color='darkgreen', linestyle='--',linewidth=2.2, label='mean=' + str(np.round(data[col].mean(),1)) )plt.axvline(data[col].median(), color='red', linestyle='--',linewidth=2.2, label='median='+ str(np.round(data[col].median(),1)) )plt.axvline(data[col].mode()[0], color='purple', linestyle='--',linewidth=2.2, label='mode='+ str(np.round(data[col].mode()[0],1)) )plt.legend(bbox_to_anchor=(1, 1.03), ncol=1, fontsize=17, fancybox=True, shadow=True, frameon=True)plt.tight_layout()plt.show()
各个数值型特征的分布分析:
年龄的分布情况
dist_plot(data_clean,'age','年龄的分布分析')
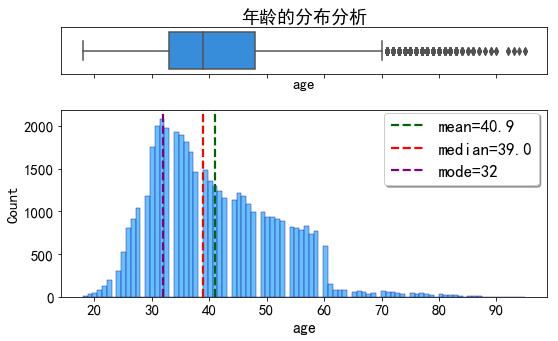
客户年龄集中在32岁,整体呈现右偏态分布。
收支情况分布
dist_plot(data_clean,'balance','收支的分布分析')

客户的收支情况呈现出明显的长尾分布。
联系日期的分布
dist_plot(data_clean,'day','日期的分布分析')
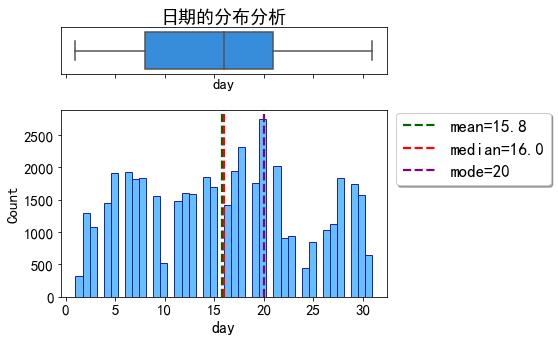
客户经理的发出联系的时间基本集中在月中。
联系时长的分布情况
dist_plot(data_clean,'duration','联系时长的分布分析')
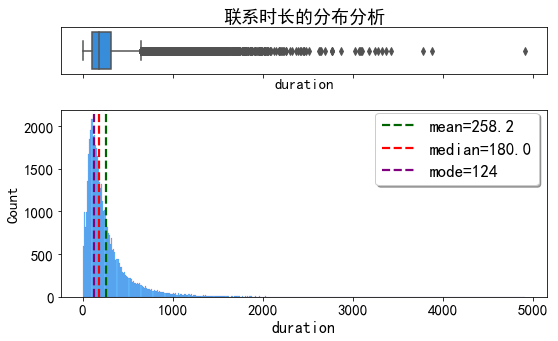
典型的长尾分布,大多数客户的联系时长在2分钟左右。
距离上次联系天数的分布
dist_plot(data_clean,'pdays','距上次联系天数的分布分析')
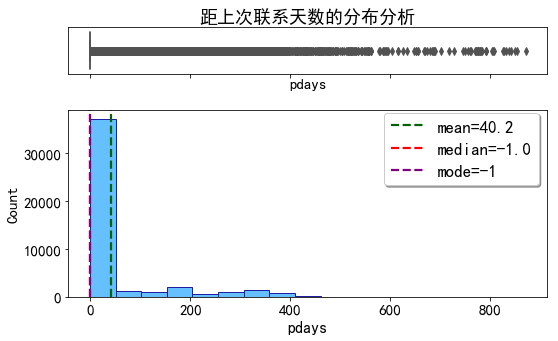
- 可以看到这里大量出现了-1,此处的-1为从未联系过的新客户,即在本次活动中,有大量客户是以前从未联系过的。这一现象符合之前协方差矩阵分析中得到的结论:银行在本次活动中以新客户为重点营销目标。
给这些新客户单独加上标签,方便后续进行分析。
data_clean['new_customer'] = data.pdays.apply(lambda x : 1 if x == -1 else 0)
小结:
- 从以上数据分布分析中,我们了解到该行客户的年龄集中在32岁,并且大部分客户账面余额为0,本次活动中客户经理们集中对新客户开展营销。
探索不同变量对是否购买存款的影响
在这一部分,笔者将探索每一个特征对于是否购买存款的影响。
定义一个饼图绘制函数方便后续绘图分析
def pie_plot(data,col,title,figsize = (20,20),height = 4,width = 4):plt.figure(figsize = figsize)plt.suptitle(title)row = data_clean[col].unique().tolist()length = len(row)for i in range(length):plt.subplot(width,height,i+1).set_title(row[i])plt.pie( data[data_clean[col] == row[i]].y.value_counts(),labels = ['no','yes'],explode = [0,0.2],colors = ['#66CCCC','#FF6666'],autopct = '%.2f%%' )
plt.show()
工作情况会否影响是否存款?
pie_plot(data_clean,'job','不同工作下的存款购买占比')

分析结果:
- 无固定收入的群体,包括学生,退休人员,失业人员的存款购买意愿最高。在选择存款销售对象时可以优先考虑这些群体。高收入人群,包括经理,管理者的存款认购意愿要高于低收入人群,包括服务员,家庭主妇和蓝领。
猜想:
- 从笔者的业务经验理解,高收入人群在日常开销外有更多的可支配资产,而低收入人群则需要更多的流动性去满足日常开支,因此对于存款的认购意愿也不高。
婚姻状况会否影响存款购买
pie_plot(data_clean,'marital','不同婚姻状况下的存款购买占比')

分析结果:
- 不同婚姻状况下,单身群体的存款意愿高于已婚和离婚的。
猜想:
- 一方面可能是由于单身群体只需要照顾自己,其满足日常开支后剩余的流动性要大于已婚和离婚人士,因此愿意将一部分流动性转化为存款。
- 另一方面可能是由于单身群体需要有存款积蓄为今后结婚做储备,所以其存款意愿较高。
教育水平会否影响存款购买
pie_plot(data_clean,'education','不同教育水平下的存款购买占比')
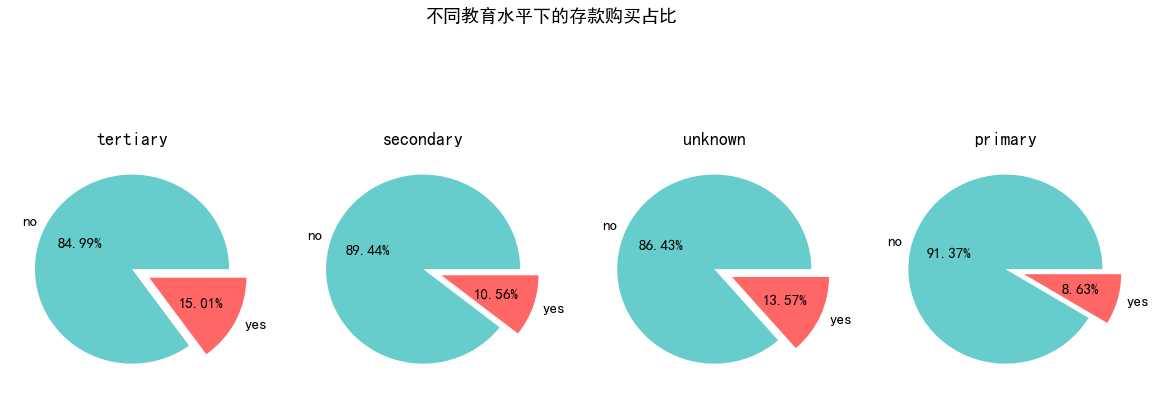
分析结果
- 存款意愿随着教育水平(小学水平,中学水平,高中水平)的升高而上升
猜想
- 更高教育水平的客户可能有着更好的理财投资观念,从而对存款的接受度会更高一些。
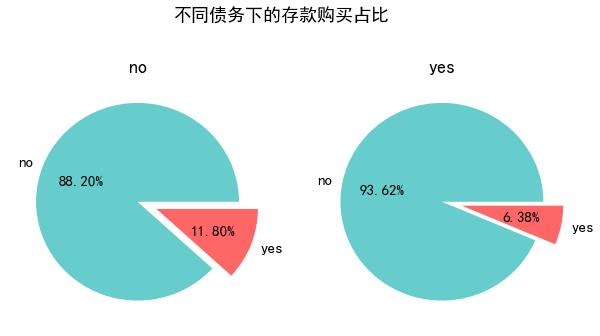
债务,房贷,个贷会否影响存款购买
pie_plot(data_clean,'default','不同债务下的存款购买占比',(10,10),height = 2, width = 2)
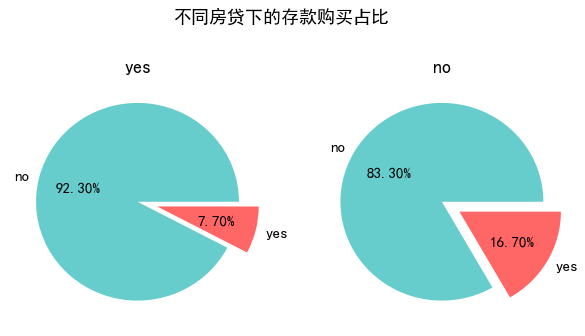
pie_plot(data_clean,'housing','不同房贷下的存款购买占比',(10,10),height = 2, width = 2)
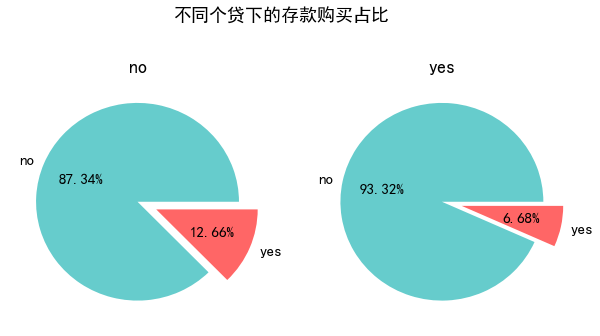
pie_plot(data_clean,'loan','不同个贷下的存款购买占比',(10,10),height = 2, width = 2)
分析结果:
- 有负债的客户群体存款意愿显著低于无负债的客户群体。
猜想:
- 有负债的群体需要流动性去偿还利息,然而存款的利息收入显然无法抵补负债利息支出,因此存款对于有负债的群体吸引力会小很多。
聊天时长对购买的影响
-
在电话营销环节,时长越长的电话,营销人员和客户的博弈机会越多,也就更有可能吸引客户购买产品。
-
所以,我们也需要考虑时长对于营销成功性的影响。在对于时长的探索中,笔者将先观察时长是否会对营销成功率产生影响。如果有影响,笔者会尝试探索如何提升联系时长。
-
对联系时长进行分桶,以25%,50%,75%为节点将联系时长分为四桶,分别是
[0,103],[103,180],[180.319],[319,4918](单位:秒),并且将各个桶标记为useless(无效电话),useful(有效电话),good(优良电话),excellent(卓越电话)
data_clean.duration.describe()

data_clean['duration_label'] = pd.qcut(data_clean.duration,4,labels=['useless','useful','good','excellent'])
pie_plot(data_clean,'duration_label','时长影响')

分析结果
- 拨打的无效电话中仅有1%的客户愿意购买存款,而随着联系时长的增加,愿意购买存款的客户比率显著性升高。
猜想
- 以笔者的从业经验出发,客户经理的日常营销中有两个因素会显著影响电话时长。其一是客户当下是否繁忙,其二是客户与客户经理的信任度如何。
- 大部分客户在客户经理还未说明来意时就直接挂断,这也就构成了无效电话极低的营销成功率。如果在客户空闲的时候拨打电话,客户经理就会有机会向客户介绍产品,其中一部分客户并未与客户经理建立信任关系,即便听完了产品的介绍,也没有选择购买,这就构成了上图的有效电话部分。另一部分客户早先就和客户经理建立的不错的信任度,此时所聊的内容并不只是产品本身,还包含了朋友间的问候,这部分客户将有很大的意愿购买相关产品,这也就构成了优良电话和卓越电话的部分。
- 因为本次数据的数据集仅包含了本次活动内同客户的联系,也就很难量化客户与客户经理的信任度关系。因此笔者在这里将提升时长的重点放在客户是否繁忙上。
绘制客户从周一到周日的电话时长分布情况
data_clean['date'] = '2011'+'-' + data_clean.month +'-'+ data_clean.day.astype('string')
data_clean['date'] = pd.to_datetime(data_clean['date'])
data_clean['weekday'] = data_clean['date'].dt.weekdayplt.plot(data_clean.groupby('weekday').mean('duration')['duration'])
plt.title('电话时长在一周内的分布')
plt.xlabel('day of week')
plt.ylabel('duration')
plt.show()
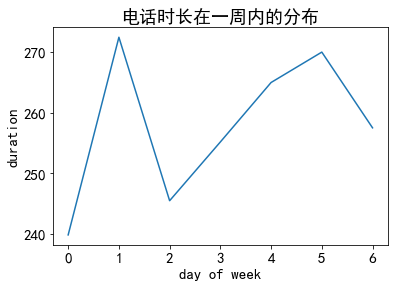
这里横轴的0代表周日
分析结果:
- 客户在周一相对空闲,周二明显降低,周三到周五稳步提升,双休日开始下降。
猜想:
- 工作日尽量避开周二联系重要客户
进一步地,观察不同工作情况的联系时长变化
plt.figure(figsize = (20,20))
plt.suptitle('不同工作下的电话时长在一周内的分布')
row = data_clean['job'].unique()for i in range(len(row)):plt.subplot(4,3,i+1).set_title(row[i])plt.plot(data_clean[data_clean['job'] ==row[i]] .groupby('weekday').median('duration')['duration'])plt.show()
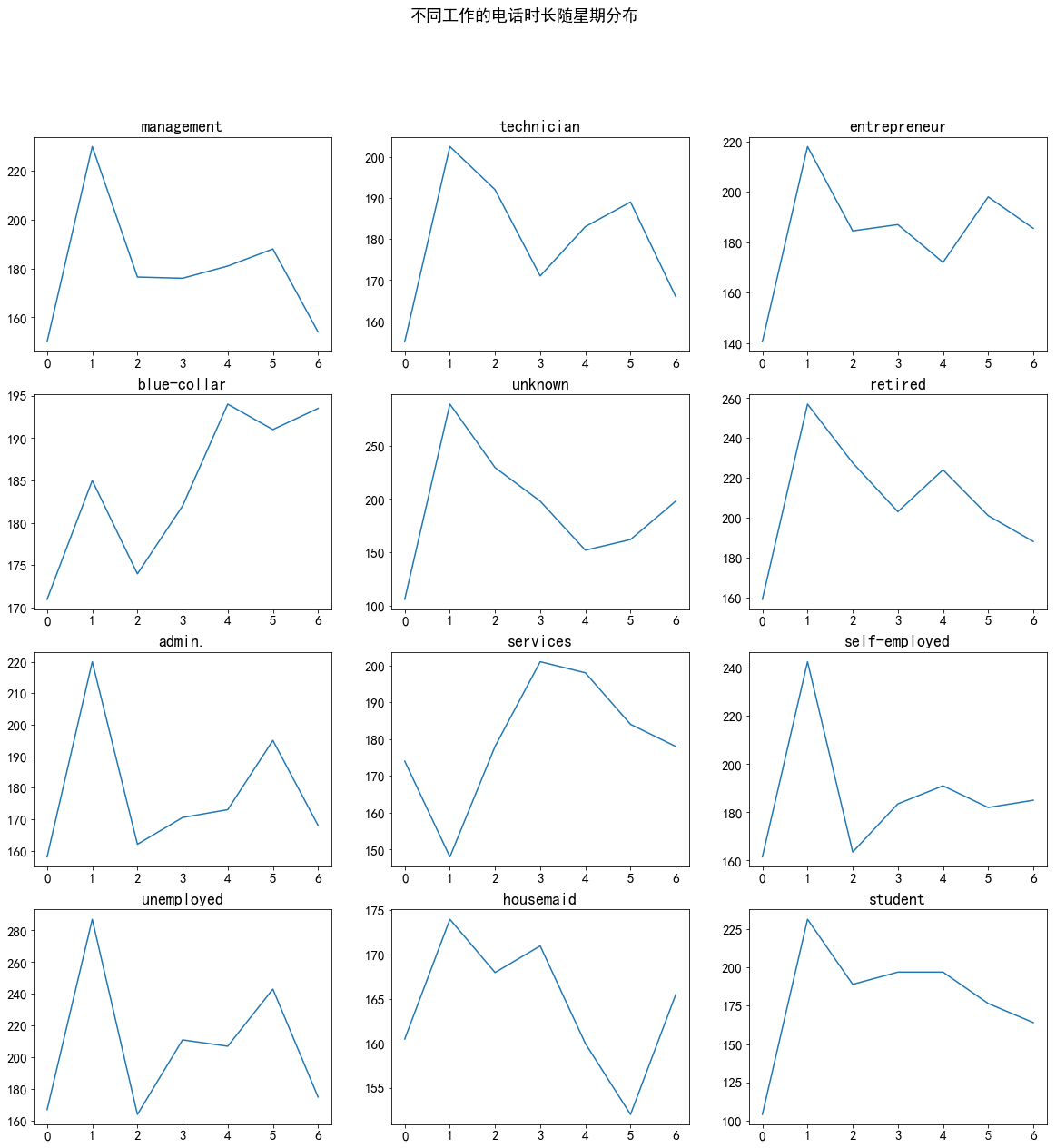
分析结果:
- 除家庭主妇外所有工种的客户在周日的联系时长均达到最低。除了服务员和蓝领以外的所有工种在周一的联系时长达到最长,之后在周二下降,周三周四周五维持相对稳定。蓝领和服务员在周三周四的联系时长最长。
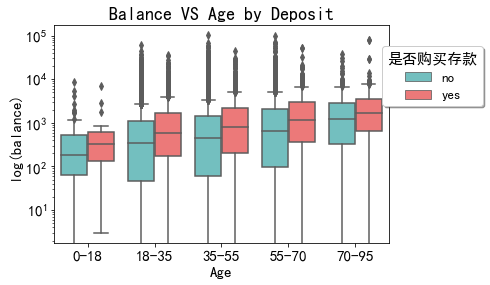
年龄的影响
data_clean['age_cate'] = pd.cut(data_clean['age'], bins=[0, 20, 35, 55, 70, float('Inf')], labels=['0-18','18-35', '35-55', '55-70', '70-95'])
plt.figure(figsize=(6,4))
sns.boxplot(x='age_cate', y='balance', hue='y', data=data_clean, palette=palette)
plt.ylabel('log(balance)')
plt.xlabel('Age')
plt.title('Balance VS Age by Deposit')
plt.yscale('log')
plt.legend(bbox_to_anchor=(1.3, 0.6), title='是否购买存款', loc = 'lower right', fontsize=13, fancybox=True, shadow=True, frameon=True)
plt.show()
pie_plot(data_clean,'age_cate','不同年龄段的用户购买存款情况')
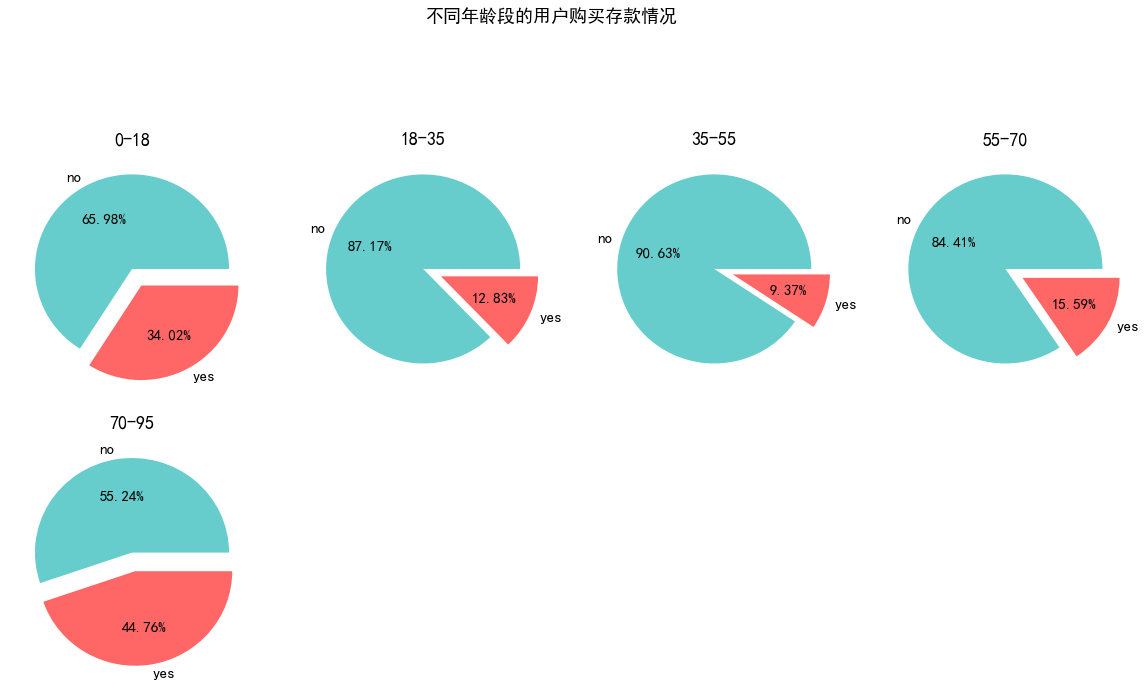
分析结果
- 55岁之前的客户存款意愿随着年龄增大而下降,55岁之后的客户存款意愿则随着年龄增大明显上升。其中35-55岁的客户存款意愿最低。
猜想
- 小于18岁的客户基本由学生组成,消费水平低,可用于存款的资金比例更多。18之后随着结婚等生活压力的增加,日常开支升高,流动性需求升高,导致存款意愿降低。55岁退休之后,消费水平和收入同时下降,需要有稳定性更强的资金来保证生活,因此存款意愿再次升高。
潜在客户预测模型建立
- 在这一部分,笔者将对数据进行特征工程处理,包括非数值变量的编码,异常值的处理。并用XGboost对处理后的数据进行模型训练,评估和预测。
预测前的数据处理
data_ml = data_clean.replace(['yes','no'], [1,0])
feature_category = data_ml.select_dtypes('object').columns
data_ml.job.value_counts()

工作特征做独热编码,unknown字段用nan代替
data_clean['job'] = data_clean['job'].replace('unknown', np.nan)
data_ml.age_cate.value_counts()

年龄分桶做序列编码
code = {}
age_encode = {'0-18':0,'18-35':1,'35-55':2,'55-70':3,'70-95':4}
code['age_cate'] = age_encode
data_ml['age_cate'] = data_ml['age_cate'].map(code['age_cate'])
data_ml['marital'].value_counts()

婚姻状况做序列编码
code['marital'] = {'single':0,'married':1,'divorced':2}
data_ml['marital'] = data_ml['marital'].map(code['marital'])
data_ml['education'].value_counts()

教育水平做序列编码
code['education'] = {'primary':0,'secondary':1,'tertiary':2, 'unknown':np.nan}
data_ml['education'] = data_ml['education'].map(code['education'])
data_ml['contact'].value_counts()

联系方式做序列编码,unknown用nan代替
code['contact'] = {'telephone':0,'cellular':1, 'unknown':np.nan}
data_ml['contact'] = data_ml['contact'].map(code['contact'])
data_ml['month'].value_counts()

月份做序列编码
code['month']={'jan':0,'feb':1,'mar':2,'apr':3,'may':4,'jun':5,'jul':6,'aug':7,'sep':8,'oct':9,'nov':10,'dec':11}
data_ml['month'] = data_ml['month'].map(code['month'])
data_ml['poutcome'].value_counts()

大多数客户在上一次活动中没有联系过,因此将unknown用nan代替。other字段意义不明,这里做删去处理。
data_ml['poutcome'] = data_ml[data_ml['poutcome']!='other']['poutcome']
data_ml['poutcome'] = data_ml['poutcome'].replace('unknown',np.nan)
data_ml.isnull().sum()

模型训练
删去无关特征
data_ml = data_ml.drop(['duration_label','duration','date','day','month'],axis = 1)
data_ml_encoded = pd.get_dummies(data_ml, drop_first=True)
X = data_ml_encoded.drop('y', axis=1)
y = data_ml_encoded['y']
训练集,验证集,测试集分离
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, stratify=y, random_state= 666)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size = 0.15, stratify=y_train, random_state= 666)
定义目标函数为预测准确率
def objective(trial, X_train=X_train, X_val=X_val, y_train=y_train, y_val=y_val):param = {'objective' : 'binary:logistic','eval_metric' : 'auc','lambda': trial.suggest_loguniform('lambda', 1e-3, 10.0),'alpha': trial.suggest_loguniform('alpha', 1e-3, 10.0),'colsample_bytree': trial.suggest_float('colsample_bytree', 0.1,1),'subsample': trial.suggest_categorical('subsample', [0.4,0.5,0.6,0.7,0.8,1.0]),'learning_rate': trial.suggest_loguniform('learning_rate', 1e-2,0.5),'n_estimators': trial.suggest_categorical('n_estimators', [1000,1500,2000,2500,3000,3500]),'max_depth': trial.suggest_int('max_depth', 3,10),'min_child_weight': trial.suggest_int('min_child_weight', 1, 20),}model = xgb.XGBClassifier(**param,use_label_encoder=False) model.fit(X_train, y_train, eval_set=[(X_val, y_val)], early_stopping_rounds=100, verbose=False,) preds = model.predict(X_val)score = accuracy_score(y_val, preds)return score
用optuna最大化预测准确率的方式调参
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=50)print("已完成训练次数: ", len(study.trials))
print("最佳结果:")
trial = study.best_trialprint(" Value: {}".format(trial.value))
print(" Params: ")hp = study.best_paramsfor key, value in trial.params.items():print(" {}: {}".format(key, value))
模型拟合
xgb_model = xgb.XGBClassifier(**hp)
xgb_model.fit(X_train, y_train, eval_set=[(X_val, y_val)], early_stopping_rounds=100, verbose=0)
y_pred_xgb = xgb_model.predict(X_test)
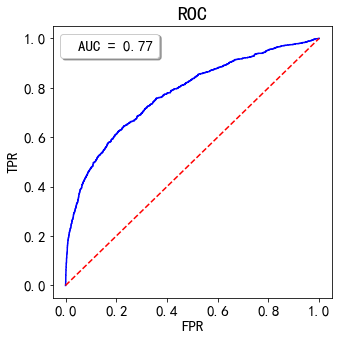
绘制ROC并计算AUC
plt.figure(figsize = (5, 5))probs = xgb_model.predict_proba(X_test)
preds = probs[:,1]
fpr, tpr, _ = roc_curve(y_test, preds)
roc_auc = auc(fprxgb, tprxgb)plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.plot([0, 1], [0, 1],'r--')
plt.title('ROC',fontsize=20)
plt.ylabel('TPR',fontsize=15)
plt.xlabel('FPR',fontsize=15)
plt.legend(loc = 'opper right', fontsize=15, fancybox=True, shadow=True, frameon=True,handlelength=0)
plt.show()
根据混淆矩阵观察训练结果
confusion_matrix(y_pred_xgb,y_test)

模型结果
- 从混淆矩阵中看出,当新进入9043个客户时,我们预测其中有1058个客户有存款购买意愿,有192个客户预测正确,查准率达到
192/(77+192) = 71.4%。
总结
-
对于新的一批客户,可以用本模型先进行预测,将预测出的购买意愿高的客户作为重点客户对待。在活动前夕,由客户经理对这批客户做提前触达,建立起双方的信任度,为日后的营销工作打好基础。
-
客群的联系优先级顺序上,首先联系无负债客群,客群内部按照工作为失业人员,低收入群体,高收入群体以及学历从高到低的顺序进行客户意愿排摸。
-
在同客户联系的过程中,可根据前文中不同工作的客户在一周内联系时长折现图,选择客户经理当天的目标营销客户,重点在于提高同客户的联系时长。