电商潜在客户识别
前言
1、任务描述
此数据集仅用于学习客户细分概念,也称为市场篮子分析。我将以最简单的形式使用无监督的ML技术(KMeans聚类算法)来演示这一点。
通过超市商场会员卡信息,我们可以得到一些关于客户的基本数据,如客户ID、年龄、性别、年收入和支出得分。其中,支出得分是商场根据客户行为和购买数据等为用户计算出来的综合得分。
我们想要进一步的了解客户,比如哪一类客户是我们的目标客户,这样就可以给营销团队提供一些有价值的东西,并相应地规划策略。
2、潜在客户识别概述
在任何有交易的领域,尤其是电商、零售、金融、生活服务这类有深厚的数据积累的行业,识别潜在客户可以进一步的降低营销成本,缩短营销周期和提高转化率,因此潜在客户的识别非常关键。基于潜在客户识别的数据驱动策略可以直接面向目标客户,因此,客户细分是客户智能领域的一个核心应用。
我们通通过聚类来实现用户分类,将根据不同的属性(可能是购买习惯或行为习惯)将人们划分成不同的类别,打上不同的标签。这是一个无监督学习的应用,机器学习模型试图将相似的数据点聚集在一起,使得簇内距离最小,簇间距离最大。使这些人群相互之间是有差别的,同一个人群的行为和属性又尽可能的相似。
3、分析目标
在精准营销中,我们不仅要聚焦核心用户的需求,为我们的核心用户提供好的产品和服务,还需要聚焦潜在用户的挖掘以及强关联用户向核心用户的转化,这样可以实现销售规模进一步扩大。我们的目标就是识别出潜在的用户,为后续潜在用户的深入分析奠定基础,以设计专门针对该类人群的活动,开拓该类人群聚集的广告投放渠道,或者加强覆盖该类人群渠道的营销力度等。
在这里,我们使用的数据集包含了人们在商场的购买属性。数据集很简单,有5个特征,即客户ID、年龄、性别、信用评分和收入。我们需要从200条电商交易数据集中识别出目标用户和潜在用户。这对我们企业进一步实现精准营销落地有很大的价值和意义。
一、数据准备与数据预处理
1、导入包和库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN
# 自定义可视化样式
sns.set_palette("Reds")
sns.set(style="white", color_codes=True)
plt.style.use('seaborn')
mycmap = plt.get_cmap('gnuplot2')
plt.style.context('dark_background')
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
2、读取数据
df = pd.read_csv('Mall_Customers.csv')
df.head()
| CustomerID | Gender | Age | Annual Income (k$) | Spending Score (1-100) | |
|---|---|---|---|---|---|
| 0 | 1 | Male | 19 | 15 | 39 |
| 1 | 2 | Male | 21 | 15 | 81 |
| 2 | 3 | Female | 20 | 16 | 6 |
| 3 | 4 | Female | 23 | 16 | 77 |
| 4 | 5 | Female | 31 | 17 | 40 |
3、查看空值情况
df.isna().sum()
CustomerID 0
Gender 0
Age 0
Annual Income (k$) 0
Spending Score (1-100) 0
dtype: int64
二、数据探索
1、查看数据集是否平衡
print(df["Gender"].value_counts())
sns.countplot(x= df['Gender'])
Female 112
Male 88
Name: Gender, dtype: int64<AxesSubplot:xlabel='Gender', ylabel='count'>
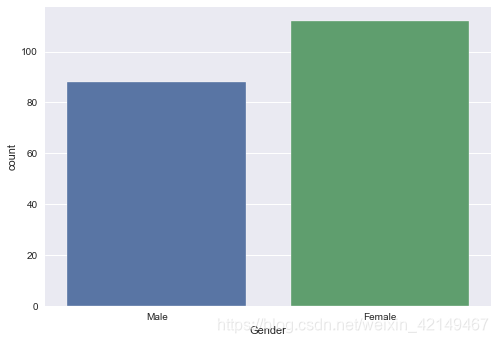
数据集基本是平衡的,因为男性和女差距并不大。
2、显示各种特征排列的成对图
sns.pairplot(df)
<seaborn.axisgrid.PairGrid at 0x7fc244fcc0d0>
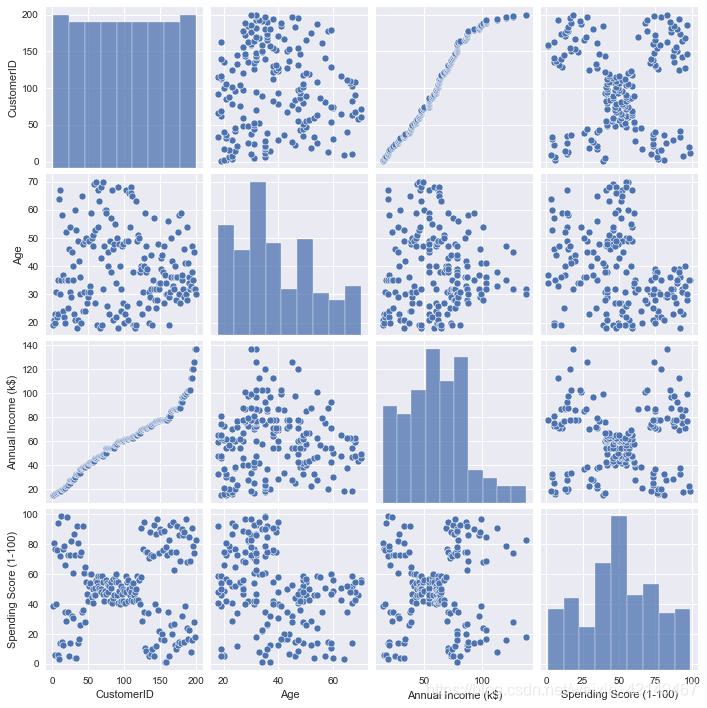
最后一行可以比较清楚的展示出来数据的分群
3、查看特征间的核密度
(1)消费分数和年龄的核密度图
g = sns.jointplot(x = df['Age'], y = df['Spending Score (1-100)'], kind="kde",thresh=0,shade=True,height=7, space=0,cmap= mycmap,color = "b")
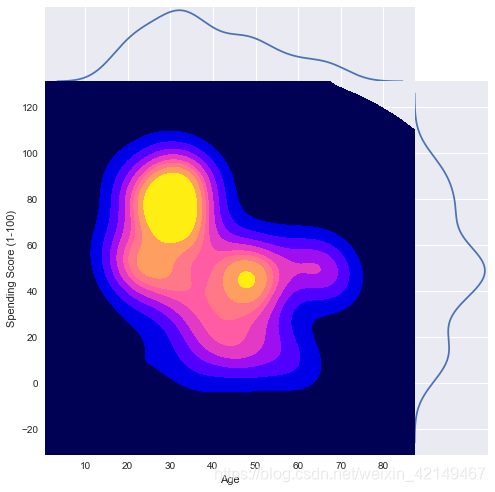
如果你仔细观察这幅图,那么,你会发现核心区域密度非常高。也许,在不同的年龄段有两种不同的消费习惯。
(2)支出得分与年收入的核密度图
g = sns.jointplot(x = df['Annual Income (k$)'], y = df['Spending Score (1-100)'], kind="kde",thresh=0,shade=True,height=7, space=0,cmap= mycmap,color = "b")
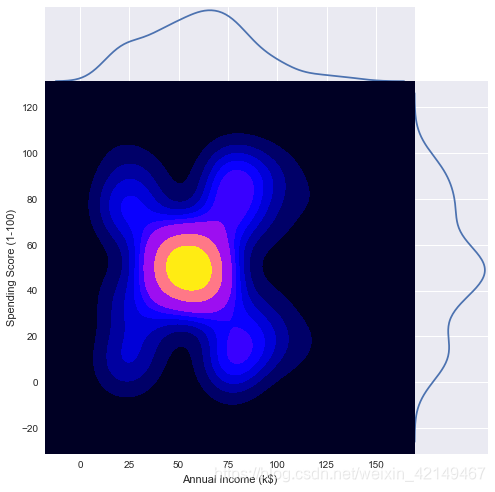
这里,在年收入与支出分数之间,有一个密度非常高的区域在中间。以及其他四个用户显示不同模式的区域。这可能是因为顾客的购买力不同,消费习惯也不同。观察结果中可以破译的五组是:
-
低收入和高消费习惯
-
低收入和低消费习惯
-
中等收入和中等消费习惯
-
高收入和高消费习惯
-
高收入低消费习惯
(3)年收入和年龄的核密度图
g = sns.jointplot(x = df['Annual Income (k$)'], y = df['Age'], kind="kde",thresh=0,shade=True,height=7, space=0,cmap= mycmap,color = "b")
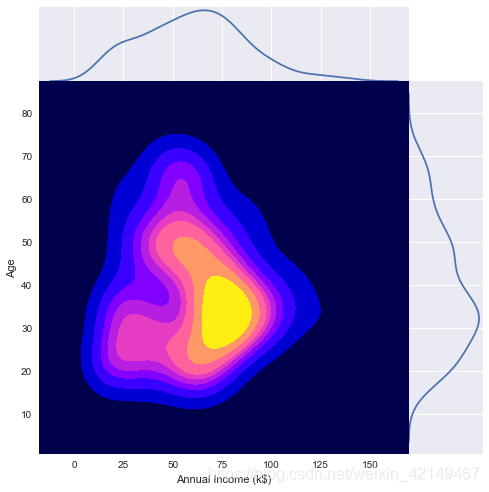
30多岁的人平均收入约为8万美元
如果我们比较一下年收入超过10万的人,就会发现男性在30岁出头时的收入超过10万,而女性则在40岁左右,这也许是由于男女之间的收入差距。
sns.relplot(x="Age", y="Annual Income (k$)", hue="Gender",sizes=(40, 400), alpha=.5, palette="muted",height=6, data=df)
<seaborn.axisgrid.FacetGrid at 0x7fc2466bd940>
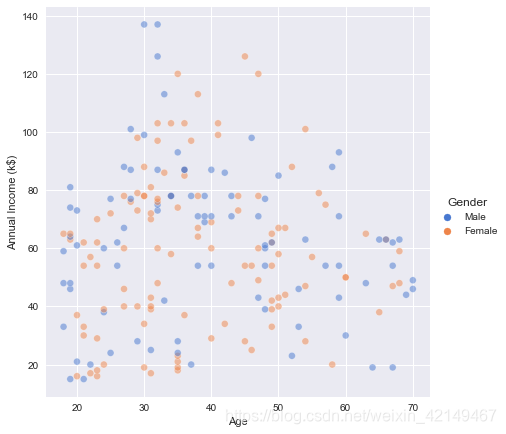
4、深入探索性别与各特征间的关系
(1)编码性别(0-1)
df['Gender']= df['Gender'].map({'Male':1,'Female':0})
(2)不同性别消费得分的方框图
ax = sns.boxplot(x="Gender", y="Spending Score (1-100)", hue="Gender", data=df, palette="Set3")
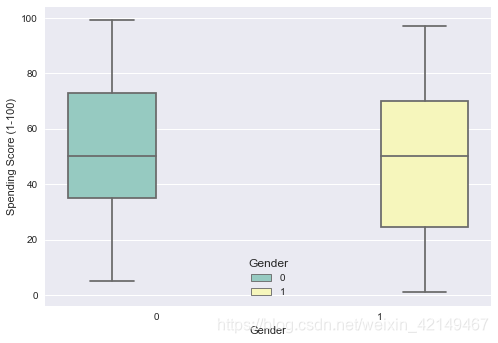
女性的平均消费得分略高于男性。(男性->1和女性->0)
(3)男女年收入
sns.catplot(x="Gender", y="Annual Income (k$)", hue="Gender",kind="violin", split=False, data=df,palette='inferno')
<seaborn.axisgrid.FacetGrid at 0x7fc246aaa280>
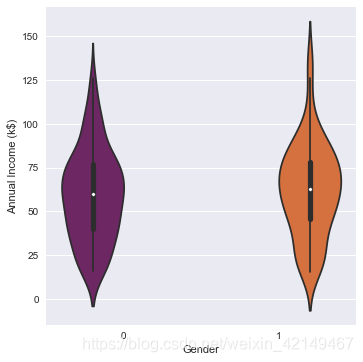
注意图中的凸起部分,它显示了平均值。因此,男性的平均收入低于女性。
5、查看特征分布
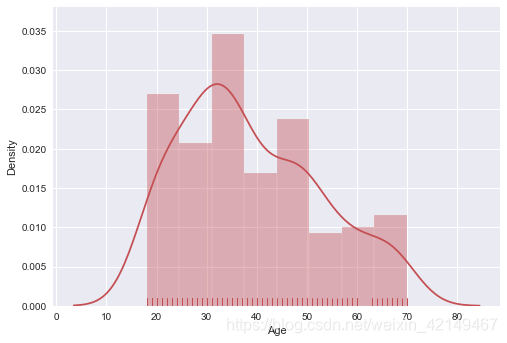
(1)用户年龄分布
根据我们的数据,大多数人都不到45岁。
sns.distplot(df['Age'],kde=True,rug = True,color = "r" )
<AxesSubplot:xlabel='Age', ylabel='Density'>
(2)支出得分分布
sns.distplot(df['Spending Score (1-100)'], hist=True, rug=True,color ="r")
<AxesSubplot:xlabel='Spending Score (1-100)', ylabel='Density'>
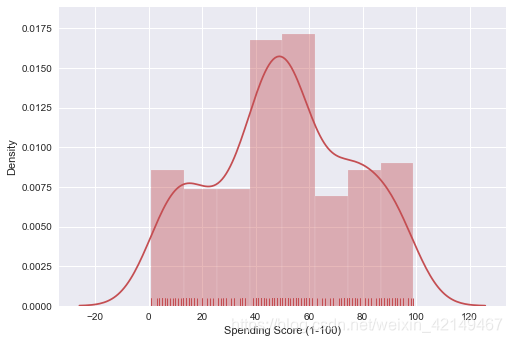
对于大多数客户来说,消费得分中心在40到60分之间。
6、特征相关性分析
sns.heatmap(df.corr(), annot=True,cmap='inferno_r')
<AxesSubplot:>
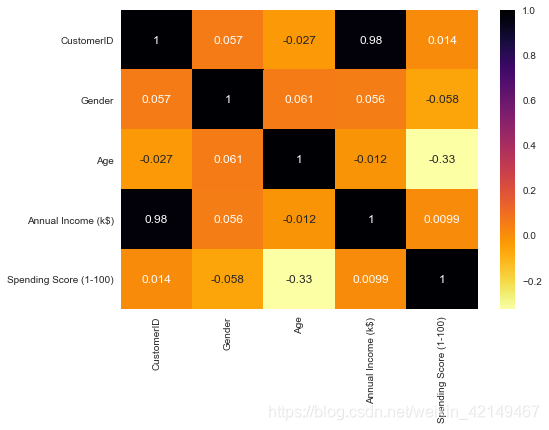
年收入与性别呈正相关。而且,年收入与支出得分呈正相关!
三、基于Kmeans的客户细分
1、Kmeans简介
Kmeans算法:
-
是一种迭代算法,它试图将数据集划分为Kpre定义的不同的非重叠子组(簇),其中每个数据点只属于一个组。
-
它试图使集群内的数据点尽可能相似,同时也尽可能保持集群的不同(远)。
-
它将数据点分配给一个簇,使得数据点和簇形心之间的平方距离之和(属于该簇的所有数据点的算术平均值)最小。
-
我们在簇内的变化越小,数据点在同一簇内的同质性(相似性)就越高。
from sklearn.cluster import KMeans
可以使用StandardScaler来缩放特性,但是在这个数据集中不需要它,因为值已经在相同的范围内。
2、构建Kmeans聚类模型
(1)使用sklearn的Kmeans方法
def kmeans(X, n_clusters):#ss = StandardScaler()#X = ss.fit_transform(X)km = KMeans(n_clusters=n_clusters)km.fit(X)y_pred = km.predict(X)return y_preddef plot_clusters(algo_name, y_pred, x_label,y_label):plt.scatter(X[:,0], X[:,1],c=y_pred,cmap='Paired')plt.title(algo_name)plt.xlabel(x_label)plt.ylabel(y_label)
(2)在Kmeans中找到“K”的正确值:
在选择k值时,传统方法中使用肘部图较多,可以选择下降最快的转折点为最佳k值,但是有时候,有些时没有明确的转折点,我们只能选择其他可行的方法。另外一个健壮的方法是使用轮廓分数,选择轮廓最大的点可以帮助我们确定最佳k值。
轮廓系数1、使用每个样本的平均簇内距离(a)和平均最近簇距离(b)计算轮廓系数。样本的轮廓系数为
(b - a) / max(a, b)2、请注意,仅当标签数为:2 <= n_labels <= n_samples - 1时,b是样本与样本不属于的最近簇之间的距离。
X=df.iloc[:,3:].to_numpy()silhouette_scores ={}
for k in range(2,10):y_pred = kmeans(X,k)silhouette_scores[k]= silhouette_score(X,y_pred)
silhouette_scores
{2: 0.2968969162503008,3: 0.46761358158775435,4: 0.4931963109249047,5: 0.553931997444648,6: 0.5379675585622219,7: 0.5281944387251989,8: 0.4558493609925033,9: 0.461684164916706}
由于K=5时轮廓得分最大,所以最好将数据分为5个子组
(3)当k=5时聚类的结果
y_pred= kmeans(X,5)
plot_clusters("KMeans",y_pred,"Annual Income(k$)","Spending Score")
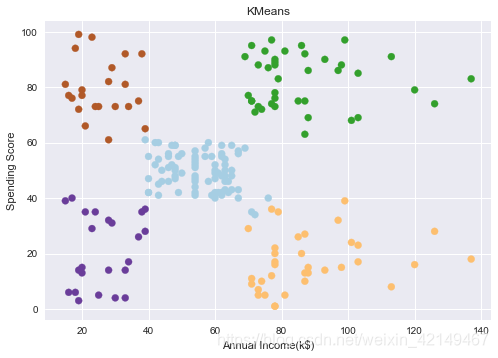
根据上述的客户细分,我们可以制定具体的营销策略,以便将产品销售给目标受众,例如:
- 黄色点的客户的年收入比较高。然而,他们他们消费并不高。也许这类用户并不是吝啬鬼,而是因为这类用户并不是我们产品的忠实用户。这类用户我们称其为潜在客户,我们在精准营销工作中,就有一部分工作是将潜在用户转化为强相关用户或核心用户,以及将强相关用户转化为核心用户。这类用户恰巧是我们需要聚焦的“潜在用户群体-目标群体”转化群体,我们不得不投入更多的努力让这类用户更多的为我们的产品买单。
- 绿色点的人群是每个销售人员都想瞄准的目标客户,因为他们不仅有极强的消费能力,还有极强的消费欲望。
- 棕色人群是那些非常依赖信用卡的人,他们的收入很低,但却挥霍无度,因此称为拖欠还款的几率更高。