【Python应用】寻找社交网络中的目标用户
日后的更新:由于是很久以前的课程设计项目,完整的源码已经不见了,关键的网页数据获取和解析的部分代码我在文章中已经贴出来了,但写的也不够好,如果想参考爬取知乎的同学,推荐去看慕课网的《python分布式爬虫打造搜索引擎》,其中有对编写知乎爬虫的视频讲解,虽然已经过去了不短的时间,知乎的反爬策略可能有变,但还是有参考价值的。
对于爬虫动态代理池的构建,推荐qiyeboy/IPProxyPool这个开源项目,安装的时候可能有点麻烦,见到错误提示缺少哪个包手动pip install就好了。
以下是正文:
这是我们学校的软件工程课程设计的题目,要求自行编写爬虫或者利用开放的API获取新浪微博、知乎等社交网站的用户信息,利用数据挖掘的相关算法进行分析, 从大规模的用户群体中, 分别找出其中具有海淘或母婴购物意向的用户。
在具体实现方面我选择了知乎作为目标的社交网站,通过Python编写数据爬虫与进行数据的分析,通过数据建立用户特征向量,将已知具有母婴购物倾向的用户与未知购物倾向的用户的特征向量进行对比,进而寻找出具有母婴购物倾向的用户。
###目录
文章目录
- ###目录
- @[toc]
- 编程前简单的分析
- 选定需要获取的信息
- 爬虫的大致结构
文章目录
- ###目录
- @[toc]
- 编程前简单的分析
- 选定需要获取的信息
- 爬虫的大致结构
编程前简单的分析
###选择知乎的原因
知乎的个人详情页与问题详情页不需要登陆也能访问,免除了模拟登陆的步骤。
在知乎无论是问题描述还是个人信息内,标签的使用频繁,能给后续的文本处理与分析带来极大地方便。
不足之处:知乎专业化程度较高,其在生活化气息不如新浪微博等社交网站。
选定需要获取的信息
从个人信息页面与问题详情页面分析我们的爬虫应该爬取的信息:
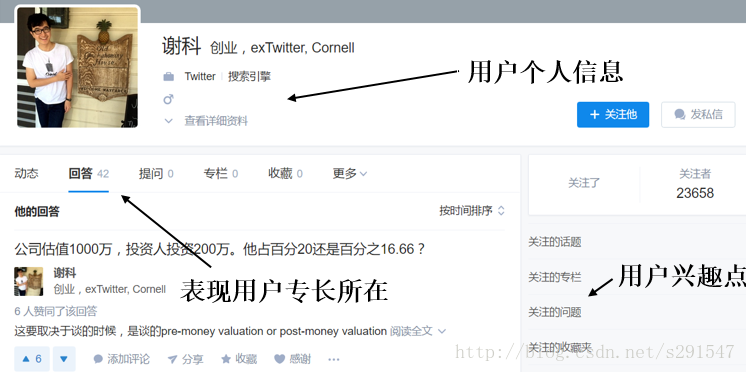

来逐项考虑每项信息对我们项目的意义:
-
用户的基本信息——昵称、居住地、教育程度等,一般考虑并不会对是否具有母婴购物倾向具有决定性的影响。
-
用户关注的话题、问题、专栏——关注的话题能最直观的展现用户的喜好、关注点所在,专栏与话题有重叠,关注的问题数量不同用户间可能会差距较大。
-
用户的回答,专栏——可以反映用户的特长,不能反映用户的兴趣点。
-
用户的提问——可能能反映用户的某种需求。问题tag能对问题进行有效概括。
综上,我决定对每个用户提取其关注的话题与所提的问题、问题的tag来建立用户特征向量。
##爬虫的编写
爬虫选择了使用Python编写,主要使用了其中的requests, beautifulsoup等库。
###一些难点与解决方法
爬虫实现过程中遇到的一些阻碍与大体解决方法如下
-
直接爬虫访问知乎遇到了500错误,结合chrome的开发者工具与fiddle网络分析工具,分析对知乎进行访问的网络请求,在爬虫头部加入了伪造的请求头。
-
前端知识较为缺乏,对HTML的DOM树结构了解不够深入,对beautifulsoup库不能很好的利用,对一些内容的爬取还需结合正则表达式来操作。
-
在获取母婴用品话题的关注用户的时候无法绕过登陆过程,而且需要对动态的网页内容进行爬取,此时只能通过selenium+chrome的组合自动填入登陆表单信息与下拉滚动条获取用户id,手动点击验证码的方式完成(现在知乎的登陆验证是点击图中的倒立文字,完全自动化的爬虫想必很难处理)。
-
对于知乎会限制固定ip访问频率的问题,通过在网上批量购买ip代理地址、建立ip代理池解决,但ip代理池的更新还没能做到自动化。
-
对于单个爬虫爬取效率太低的问题,由于爬虫完整运行一次的时间主要由网络延迟决定,所以使用python的多线程编程爬虫提高爬取效率。
-
爬取的数据同步存储到mysql数据库中,使用python的pymysql库对数据库进行操作。
爬虫的大致结构
爬虫工作分为三个阶段:第一阶段为随机获取一定数量的用户id,第二阶段为获取一定数量已知具有母婴购物倾向的用户id,第三阶段为根据已经获取的用户id去获取用户的个人信息与提问详情。
-
第一阶段的工作中,以随机的一位用户作为种子用户,获取其关注的20位用户id,对这20位用户再获取其每个人关注的20位用户,如此循环,预计获取8000位用户作为未知购物倾向的用户组,将用户id写入数据库中。
-
第二阶段的工作中,前往知乎“母婴用品”话题关注者页面,获取页面下1500名关注者,作为已知具有母婴购物倾向的用户的用户组,同样将用户id写入数据库中。
-
第三阶段的工作中,通过数据库中的用户id,获取其关注的话题列表与已经提问的问题的标签列表。
其中第三阶段,也是爬虫主要阶段的主要代码如下:
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import requests
import re
import pymysql
import threading
import queue
import time#用于保存用户uid在数据库中序号的队列
q = queue.Queue(maxsize=3000)conn_0 = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root',db='zhihu', charset='utf8')cursor_0 = conn_0.cursor()
#将未读取过的用户入列
sql_0 = 'SELECT order_number from infant_userid where is_read = 0'
cursor_0.execute(sql_0)
conn_0.commit()
for r in cursor_0:r = re.sub("\D", "", str(r))print(r)q.put(r)class zhihu():def __init__(self):# 连接数据库self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='', passwd='',db='zhihu', charset='utf8')self.main_url = 'https://www.zhihu.com/people/'self.answers_url = '/answers'self.topics_url = '/following/topics?page='self.asks_url = '/asks?page='self.question_url = 'https://www.zhihu.com/question/'self.headers = {"Host": "www.zhihu.com","Referer": "https://www.zhihu.com/",'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}def get_userinfo(self, user_token, proxies):# 获取用户名字url1 = self.main_url + user_tokencontent = requests.get(url1, headers=self.headers, proxies=proxies).content#print(content.text)pattern = re.compile(r'<span class="ProfileHeader-name">(.+?)</span>')try:name_temp = pattern.findall(content.text)except:#除去僵尸用户,即未登陆无法查看信息的用户sql1 = "delete from infant_userid where token_id = '"+user_token+"'"self.cursor.execute(sql1)self.conn.commit()print(user_token+" is a ghost!!")passelse:print(name_temp)name = name_temp[0]print(name)# 获取用户关注的话题url2 = self.main_url + user_token + self.topics_url# print("fetching userinfo...")n = 1 # 话题的页数count = 21all_topics = [] # 用于存放话题的列表while count > 20:content = requests.get(url2 + str(n), headers=self.headers, proxies=proxies)pattern = re.compile(r'"name":"(.+?)"')topics = pattern.findall(content.text)all_topics = all_topics + topicsn = n + 1count = len(topics)all_topics = list(set(all_topics)) # 去重topics_str = ";".join(all_topics) # 转字符串print(topics_str)# 链接数据库sql2 = "INSERT INTO infant_users (tokenID,username,topics) VALUES ('" + user_token + "','" + name + "','" + topics_str + "')"self.cursor.execute(sql2)# print(sql)self.get_question(user_token, proxies)def get_question(self, user_token, proxies):# 获取用户的提问url = self.main_url + user_token + self.asks_url#print(url)#print("fetching questions...")n = 1 # pagequestion_count = 20while question_count > 19:content = requests.get(url + str(n), headers=self.headers, proxies=proxies)pattern = re.compile(r'"http://www.zhihu.com/api/v4/questions/(.+?)"')question_tokens = pattern.findall(content.text)# print(question_tokens)for question_token in question_tokens:#print(question_token)url2 = self.question_url + question_tokencontent2 = requests.get(url2, headers=self.headers, proxies=proxies).contentsoup = BeautifulSoup(content2, 'lxml')try:title = soup.find('h1', attrs={'class', 'QuestionHeader-title'})except:#问题未登陆无法访问的情况print('question is empty')passelse:title = title.get_text()print(title)sql_tags = []tags = soup.find_all('span', attrs={'class', 'Tag-content'})for tag in tags:tag = tag.get_text()sql_tags.append(tag)# print(sql_tags)tags_str = ";".join(sql_tags) # 转字符串# 操作mysqlsql1 = "INSERT INTO infant_questions (questionsID,question,tags,askerID) VALUES ('" + question_token + "','" + title + "','" + tags_str + "','" + user_token + "')"# print(sql1)self.cursor.execute(sql1)# time.sleep(0.5)# 页面计数加一n = n + 1question_count = len(question_tokens)# print(count)#print("fetch questions done")def run(self):count = 0while count < 100:if not (q.empty()):user_num = q.get()print(user_num)self.cursor = self.conn.cursor()sql = "SELECT token_id FROM infant_userid WHERE order_number='" + str(user_num) + "'"self.cursor.execute(sql)self.conn.commit()try:user_token = self.cursor.fetchone()[0]except:print("获取用户名出错,重试中...")passelse:print("feching the no." + str(user_num) + " user: " + user_token + "...")# 代理,还需手动填入proxies_pool = [{'https': 'https://210.43.38.251:8998'}, {'https': 'https://111.155.116.247:8123'}]proxies_num = 1proxies = []#try:self.get_userinfo(user_token, proxies)#except:#print("发生错误,重试中...")#q.put(user_num)#pass#else:sql2 = "UPDATE infant_userid SET is_read=1 where token_id='" + str(user_token) + "'"self.cursor.execute(sql2)self.conn.commit()count += 1print(count)print("fetch done")self.cursor.close()if __name__ == "__main__":#定时重启的主线程for i in range(1, 10):#线程列表thread = []for i in range(0, 1):z = zhihu()t = threading.Thread(target=z.run, args=())#设为守护进程t.setDaemon(True)thread.append(t)for i in range(0, 1):thread[i].start()for i in range(0, 1):thread[i].join()time.sleep(1200)
程序运行时间过长爬取的效率会下降,将主线程设置为定时重启也不行,不知道是哪里出了问题。…
最终爬取的数据在数据库中预览的效果如下:


数据库与表的结构就不贴出来了,并不是什么复杂的结构。
##数据的处理
###初步处理
-
筛选:剔除无法访问的用户后,得到7792位未知购物倾向用户信息,1209位已知具有母婴购物倾向用户信息。母婴用户下有1141条问题记录,未知倾向用户下有16924条问题记录。
-
分词:对每个用户关注的话题、问题使用结巴分词进行分词处理。分词过程中整合网络上的停用词表,构建更为全面的停用词表。
-
生成待分析文本:将每个用户分词后信息导出到一个txt文件,以用户的id作为文件名。未知与已知用户分别置于两个不同文件夹内。
这样每个用户就有了一个描述该用户的txt文件,下一步将基于这个txt文件的内容计算用户的特征向量。
###进一步处理
-
首先计算已知母婴购物倾向用户的特征向量:计算每个词的卡方统计量,挑选出其中CHI>0.1的词语作为特征向量,然后计算每个词语的TF-IDF值作为特征向量的权重,其乘积便为带权重的特征向量。
CHI值的计算公式:
TF-IDF值的计算公式:
-
建立未知购物倾向用户词表,计算每个词的特征向量值后写入数据库,对每个未知购物倾向用户的分词后文档进行处理,从数据库中查询每个词的特征向量值构成该用户的特征向量。
-
计算已知具有母婴购物倾向的用户与未知用户的特征向量夹角余弦值,若计算结果大于0.5则认为该未知用户同样具有母婴购物倾向。


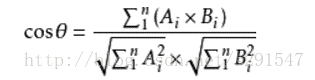
##结果
###程序运行的结果
程序运行情况如图:

此时程序运行了25分钟,处理了500+位用户的数据,约占总数的6%,从搜索结果栏可以发现,程序已经寻找出了三位潜在的具有母婴购物倾向的用户。
如果运行的时间足够长的话,可以从7792位用户中把所有具有母婴购物倾向的用户寻找出来(懒啊…)。
###小小的总结
当然,从运行结果就能看出缺点:程序太慢,效率太低了…建立未知购物倾向用户的特征向量与余弦夹角的计算都需要很多时间。实际上以上分析的方法都只是简单的对包含用户信息的文本进行相似度的比较,其中“计算结果大于0.5则认为该未知用户同样具有母婴购物倾向”也没有任何根据,完全只是为了方便而私人划定的标准,对于获得的“潜在用户”也没有任何校验准确性的方法,整套分析的方法可以说是漏洞百出(这点在课程设计答辩的时候已经被老师指出了),所以这篇文章并不具备任何作为实际参考的意义,仅仅是作为个人python程序练手项目的一次总结与记录。
期间也想要放弃,虽然掉入了一个又一个的坑,但还是勉勉强强爬了出来…

在实际编程的工作中遇到的困难比文中提及的要多,例如数据库操作上的困难(去重)、代理设置上的疑问(http与https只差)、手贱删掉已经爬好的用户数据等…虽然其中大多数是低级错误,但一脚一个坑也算是能让我长点记性吧…
###参考资料
-
TF-IDF与余弦相似性的应用(一):自动提取关键词 -阮一峰的网络日志
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html -
简单之美|使用libsvm实现文本分类
http://shiyanjun.cn/archives/548.html -
Word2—寻找社交新浪微博中的目标用户
http://www.cnblogs.com/caimuqing/p/5662526.html -
Beautifulsoup, requests, pymysql, selenium等python3库的参考文档,博客。