看到知乎上的一个问题“如何向深度学习模型中加入先验知识?”,觉得这是一个很好的问题,恰好自己在这方面有一些心得,今天拿出来和大家聊一聊。
说这个问题有趣,是因为提问者一定是对DNN的“智能”程度不满意了:DNN不是号称自己“万能函数模拟器”吗?这么明显不过的pattern, dnn怎么就学不到呢?一天到晚地出bad case,在产品运营小mm眼中的高大上形象正一点点在崩塌,唉,恨铁不成钢。
我们能够发现的pattern和bad case,就是“先验知识”。用人类的“先验知识”提升模型质量,这个问题还是太大了。本文还是只聚焦于我的老本行“推荐领域”,再聚焦于其中的两个具体问题:
特征就是重要的先验知识。但是有时我们自认为加入了一个非常重要的特征,但是模型效果却没有提升。很有可能是你加的位置不对。第一个话题,就讨论如何将“先验重要”的特征加到合适的位置。
第二个问题关注的是,在多任务推荐场景下,如果某个目标训练不好,我们如何利用先验知识替它找个帮手。
先验重要的特征要加到合适的位置
设计特征,是将先验知识注入模型的重要手段。别听什么“深度学习不需要特征工程”鬼话+屁话+外行话,“garbage in, garbage out”才是我们搞算法应该信奉的金科玉律。
但是很多时候,我们会陷入一种尴尬的场景:绞尽脑汁地设计了特征,费劲巴拉地打通了上下游数据链路,爆肝费神地将数据回溯好,加入模型训练一看,离线指标稳稳不动如山,顿时气也泄了三分。
唉,多么熟悉的场景,又多么痛的领悟!造成这种情况的原因有很多,我来谈其中一个原因,就是,如果你的“先验”的确成立的话,那么这个重要特征没发挥作用的原因,很可能是你没把他放到合适的位置上。
之前,我们都非常迷信DNN的表达能力,吹捧它是“万能函数模拟器”。但是近年来,很多研究表明,DNN没传说地那么强,正如DCN作者在论文中所宣称的那样,“People generally consider DNNs as universal function approximators, that could potentially learn all kinds of feature interactions. However, recent studies found that DNNs are inefficient to even approximately model 2nd or 3rd-order feature crosses.”。正因如此,如果你先重要的特征加到DNN底部,层层向上传递,恐怕再重要的信息到达顶部时,也不剩下多少了。另外,推荐系统中,DNN的底层往往是若干特征embedding的拼接,动辄几千维是小意思,这时你再新加入一个特征32维embedding,“泯然众人矣”,恐怕也不会太奇怪。
那么“先验”重要的特征到底要加到哪里才能发挥作用呢?根据业界和我个人的经验,一是要加得浅,二是让它们充当其他特征的裁判。
重要特征加得浅
其实这种思路并不新鲜,就是经典的Wide & Deep,。wide侧就是一个LR,或者条件再放宽一些,就是一个非常浅的小dnn,加入wide侧的特征离最终目标也近,避免自dnn底部层层传递带来的信息损失,更有机会将我们的先验知识贯彻到“顶”。
公式容易写,问题是哪些特征要进wide侧,哪些特征要进deep侧?在我之前的文章《看Google如何实现Wide & Deep模型》就指出过,wide侧负责记忆,因此要将“根据人工经验、业务背景,将我们认为(i.e.,先验)有价值的、显而易见的特征及特征组合,喂入Wide侧”。具体在推荐领域,比如:
特征及特征对上的统计数据,e.g., <男性,20~30岁,内容标签是‘二战’>上的点击率、分享率、平均时长等;
我们已经发现了(i.e., 先验)非常明显的用户分层,比如登录用户 vs. 未登录用户、不同国家的用户、......,用户行为完全不同。为了提升模型对“用户是否登录”、“用户地域”这样强bias特征的敏感度,这些特征也加入wide侧。
与用户分层类似,在multi-domain的推荐场景下(比如:首页推荐与猜你喜欢,混合训练),淘宝的STAR《One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》也是将domain-id这样的强bias特征,喂入一个非常简单的dnn,得到的logit再叠加到主模型的logit上,算是wide&deep的一个变种。文中还强调,“the auxiliary network is much simpler ...... The simple architecture makes the domain features directly influence the final prediction”
重要特征当裁判
对于一些强bias特征(e.g., 用户是否登录、用户所在国家),除了将它们加浅一些,离loss近一些,还有一种方法能够增强它们的作用,避免其信息在dnn中被损失掉,就是采用SENet或LHUC(Learn Hidden Unit Contribution)这样的结构。
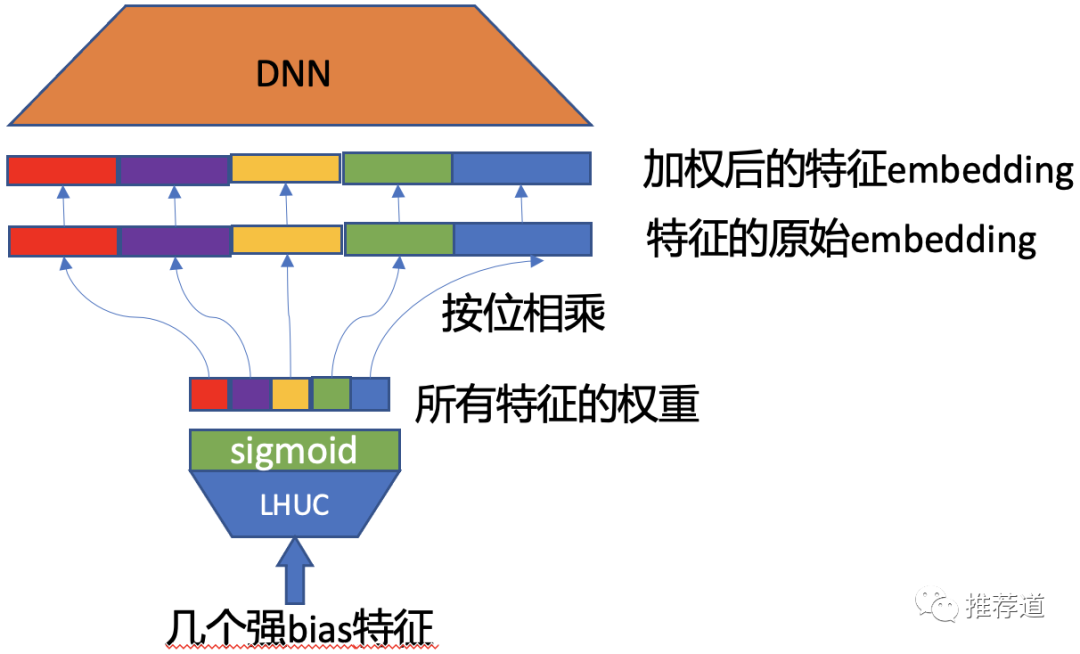
强bias特征作为LHUC的输入,经过sigmiod激活函数后,输出是一个N维度向量,N是所有field的个数
N维向量就是各field的重要性,将其按位乘到各field的embedding上,起到增强或削弱的作用
加权后的各field embedding再拼接起来,喂入上层DNN
这种结构,将一些先验认为重要的强bias的特征,放到裁判的位置,决定其他特征的重要性。比如,如果产品设计不允许未登录用户转发或评论,那么显然“用户未登录”这个特征值,就“应该”(suppose)将转发、评论相关特征的权重置为0,因为它们不能代表用户的真实意图。
这样做,相比于将所有特征“一视同仁”、一古脑地喂入DNN最底层等候上层dnn筛选,更能发挥重要特征的作用,将“先验知识”(e.g., 产品设计限制)深入贯彻。
题外话:交叉统计特征是重要先验
对于推荐模型,一个重要话题,就是特征之间的交叉(推荐五环中的第4环),引无数推荐打工人竞折腰
DNN是高阶隐式交叉,就像个黑盒,交叉成什么样了?我也不知道
FM和DCN,都是指定维度的显式交叉。
以上两种交叉其实描述的都是特征之间的共现,比如“用户是男性,同时,候选商品是篮球”,被业界研究得比较多。但是还有一类交叉,我感觉是业界谈论得比较少的,但是也是最能直接体现“先验知识”的,就是交叉特征上的统计数据,比如<男性,20~30岁,内容标签是‘二战’>上的点击率、分享率、平均时长。
但是使用这样的统计特征,有两大难点:
泛化能力差。统计特征只能涵盖样本中经常出现的特征组合,对于罕见的特征组合,假设<男性,口红>,要么统计结果不置信,要么干脆在样本中就从未出现过。
存储量巨大,需要存储任意两个特征值组合对应的统计数据。
为了更好地利用“统计特征”这一先验知识,阿里妈妈在SIGIR 21《Explicit Semantic Cross Feature Learning via Pre-trained Graph Neural Networks for CTR Prediction》一文中提出了用预训练来解决以上难题的思路:
预训练一个模型,输入两个特征,输出这一对特征组合上预估的xtr
预训练的时候用了GNN
顶点就是样本中出现过的categorical feature,样本中常见共现特征之间建立边,边上的值就是这一对儿特征离线统计出的xtr
按照link prediction的方式来训练GNN
阿里这种Pre-trained Cross Feature Learning的好处在于,用“预测”代替了“存储”,从而节省了存储量,而且对于不常见、甚至未出现过的特征组合也能够给出统计特征。感兴趣的同学可以下来原文阅读。
先验知识帮稀疏目标找帮手
多任务已经成为推荐系统的标配,以内容推荐为例,我们推荐出的内容,不仅要让用户点击,点击之后还要尽可能多地消费时长,还要鼓励用户转评赞,并上传自己制作的内容。卷卷的互联网人从来不做选择,我们都要!!!
多目标之间往往存在依赖关系(e.g., 先点击,再转化),从而导致消费链路靠后的环节,正样本稀疏,训练困难。所以,需要将信息从链路先前的环节,向链路靠后的环节迁移。
多目标之间的信息迁移,自然有MMOE、PLE这样的“全自动”方案,但是和其他dnn结构一样,它们也有“黑盒化”的缺点,也不知道它们实现的迁移是否符合我们的常识。因此,利用先验知识制订多目标之间的显式信息迁移规则,也就成了题中应用之义。
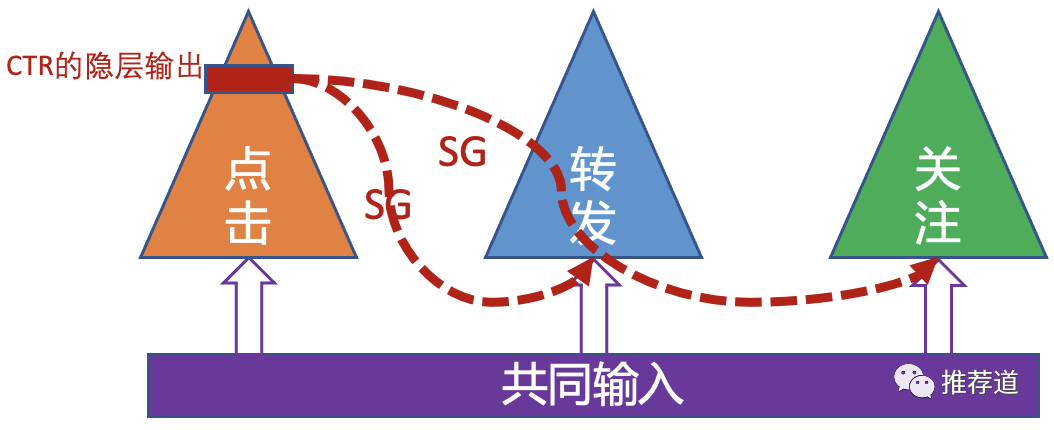
显式信息迁移的典型就是阿里的ESMM模型。pCTCVR=pCTR*pCVR。CTR任务的数据更多,预测精度更高,会给CTCVR的预测任务以提示。
将这种思路泛化之,“拿链路前端环节的输出,作为链路后端环节的输入”,也就成了“利用先验知识显式制订信息迁移规则”的典型手法。前端环节本来就会对后端环节施加重大影响,而且前端环节的训练数据丰富,它的隐层输出,将会对数据稀疏的后端环节的训练,带来极大帮助。不过,需要注意的是,在将前端环节的输出作为后端环节的输入之前,往往要先stop-gradient,防止后端稀疏环节反而将训练好的前端隐层带偏。
结论
DNN的表达能力没有传说中那么强,因此在DNN训练过程中注入人工先验知识,还是非常有必要的。本文聚焦于推荐领域,介绍了两类注入先验知识的方法:
特征是将先验知识注入模型的重要手段。但是为了能让这些先验重要的特征发挥作用,需要将它们加到浅层网络,或者作为判断其他特征重要性的裁判,而非一古脑地和其他特征混杂一起加到DNN底层。另外,文中还指明,交叉特征对儿上的统计数据是非常重要的先验知识,值得深入研究并使用之。
在多任务推荐场景下,利用先验知识,显式地设计信息迁移规则,将信息由链路前端、数据丰富的环节向链路后端、数据稀疏的环节迁移,从而提升稀疏目标的训练质量,有时能够获得比MMOE、PLE这种隐式、自动信息迁移更好的效果。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

- END -


KDD 2021 | 谷歌DHE:不使用embedding table的类别型特征embedding
2021-12-14
在国外当程序员有多爽
2021-12-11

聊一聊搜索推荐中的 Position Bias
2021-12-10
一篇就够!数据增强方法综述
2021-12-08