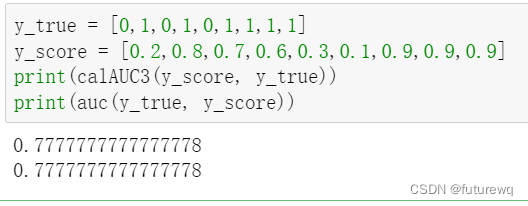
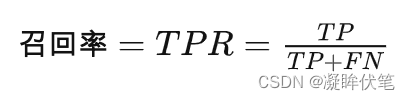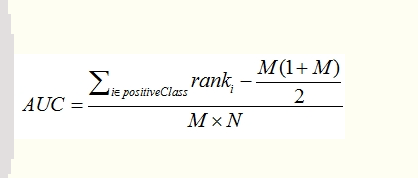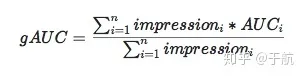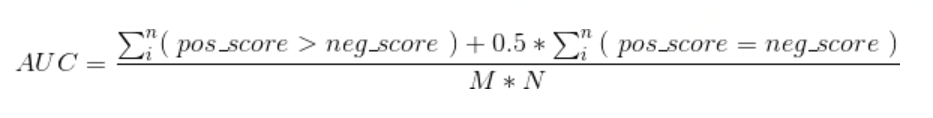模型评估指标AUC 、
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
AUC在机器学习领域中是一种模型评估指标。根据维基百科的定义,AUC(area under the curve)是ROC曲线下的面积。所以,在理解AUC之前,要先了解ROC是什么。而ROC的计算又需要借助混淆矩阵,因此,我们先从混淆矩阵开始谈起。
混淆矩阵
假设,我们有一个任务:给定一些患者的样本,构建一个模型来预测肿瘤是不是恶性的。在这里,肿瘤要么良性,要么恶性,所以这是一个典型的二分类问题。
假设我们用y=1表示肿瘤是良性,y=0表示肿瘤是恶性。则我们可以制作如下图的表格:
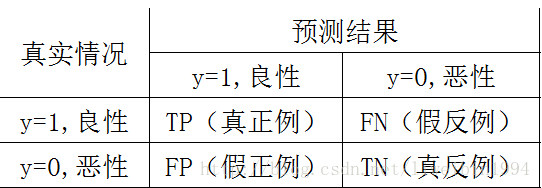
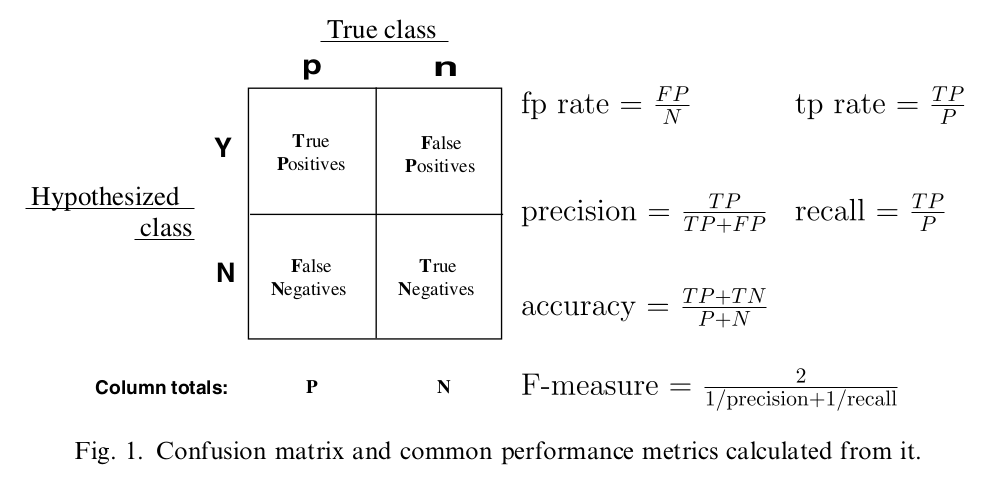
TP表示预测为良性,而实际也是良性的样例数;
FN表示预测为恶性,而实际是良性的样例数;
FP表示预测为良性,而实际是恶性的样例数;
TN表示预测为恶性,而实际也是恶性的样例数;
所以,上面这四个数就形成了一个矩阵,称为混淆矩阵。
两个变量
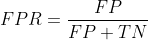
FPR表示,在所有的恶性肿瘤中,被预测成良性的比例。称为伪阳性率。伪阳性率告诉我们,随机拿一个恶性的肿瘤样本,有多大概率会将其预测成良性肿瘤。显然我们会希望FPR越小越好。
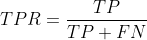
TPR表示,在所有良性肿瘤中,被预测为良性的比例。称为真阳性率。真阳性率告诉我们,随机拿一个良性的肿瘤样本时,有多大的概率会将其预测为良性肿瘤。显然我们会希望TPR越大越好。
如果以FPR为横坐标,TPR为纵坐标,就可以得到下面的坐标系:

纵坐标:TPR (预测为正,实际为正 占 所有实际为正 比例)
横坐标:FPR (预测为正,实际为负 占 所有实际为负 比例)
可能看到这里,你会觉得有点奇怪,用FPR和TPR分别作横纵坐标有什么用呢?我们先来考察几个特殊的点。
- 点(0,1),即FPR=0,TPR=1。FPR=0说明FP=0,也就是说,没有假正例。TPR=1说明,FN=0,也就是说没有假反例。这不就是最完美的情况吗?所有的预测都正确了。良性的肿瘤都预测为良性,恶性肿瘤都预测为恶性,分类百分之百正确。这也体现了FPR 与TPR的意义。就像前面说的我们本来就希望FPR越小越好,TPR越大越好。
- 点(1,0),即FPR=1,TPR=0。这个点与上面那个点形成对比,刚好相反。所以这是最糟糕的情况。所有的预测都预测错了。
- 点(0,0),即FPR=0,TPR=0。也就是FP=0,TP=0。所以这个点的意义是所有的样本都预测为恶性肿瘤。也就是说,无论给什么样本给我,我都无脑预测成恶性肿瘤就是了。
- 点(1,1),即FPR=1,TPR=1。显然,这个点跟点(0,0)是相反的,这个点的意义是将所有的样本都预测为良性肿瘤。
考察完这四个点,我们可以知道,如果一个点越接近左上角,那么说明模型的预测效果越好。如果能达到左上角(点(0,1)),那就是最完美的结果了。
ROC曲线
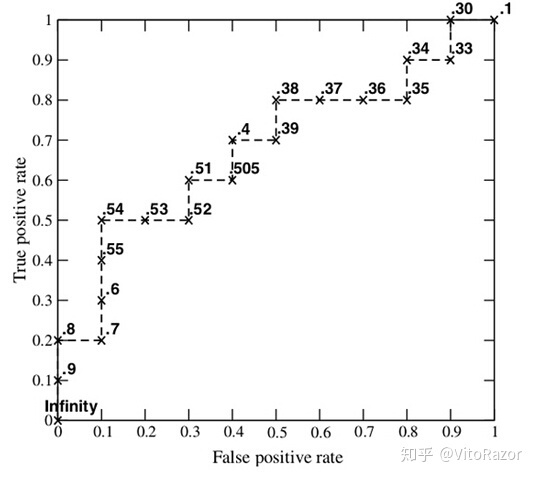
我们知道,在二分类(0,1)的模型中,一般我们最后的输出是一个概率值,表示结果是1的概率。那么我们最后怎么决定输入的x是属于0或1呢?我们需要一个阈值,超过这个阈值则归类为1,低于这个阈值就归类为0。所以,不同的阈值会导致分类的结果不同,也就是混淆矩阵不一样了,FPR和TPR也就不一样了。所以当阈值从0开始慢慢移动到1的过程,就会形成很多对(FPR, TPR)的值,将它们画在坐标系上,就是所谓的ROC曲线了。
我们来举一个例子。比如我们有5个样本:
真实的类别(label)为y = c(1,1,0,0,1).
一个分类器预测样本为1的概率为p=c(0.5, 0.6, 0.55, 0.4, 0.7).
正如上面说的,我们需要有阈值,才能将概率转换为类别,才能得到FPR和TPR。而选定不同的阈值会得到不同的FPR和TPR。假设我们现在选定的阈值为0.1,那么5个样本都被归类为1。如果选定0.3,结果仍然一样。如果选了0.45作为阈值,那么只有样本4被分进0,其余都进入1类。当我们不断改变阈值,就会得到不同的FPR和TPR。然后我们将得到的(FPR , TPR)连接起来,就得到了ROC曲线了。
这里要注意:
-
阈值的范围是[0,1],当阈值从1到0慢慢移动时,FPR会越来越大。因为FP(假正例)会越来越多。
-
如果在给定的样本中,我都随机预测,也就是0.5概率预测为良性肿瘤,0.5概率预测为恶性肿瘤。那么这条曲线会是怎样的呢?可以想象,如果数据是均匀,那么这条曲线就是y=x。
-
注意曲线一定是从(0,0)开始最终到达(1,1)的。理解了上面四个点的意义就知道了。
-
事实上,ROC曲线不是光滑的,而是阶梯型的。为什么呢?因为样本的数量是有限的,而FPR和TPR的变化需要至少有一个样本变化了,在没有变化的间隙里,就不会有变化。也就是说,步进是1/样本数。
得到了ROC曲线,我们就可以计算曲线下方的面积了。计算出来的面积就是AUC值了。
AUC值的意义
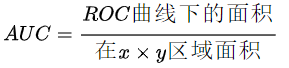
但是ROC曲线下的面积等于AUC,这句话怎么理解呢?(其实这里讲解了AUC的第二种计算方式)
实际上,这可以理解为一种积分过程,积分的内容是啥呢: 每个预测为正的样本,能比多少个负样本大
积分所在的区域是啥呢?实际是正样本和负样本的交叉,也即 正样本数∗负样本数

第一节中,原始有五个正样本:
p=0.9的真实正样本,它在所有5个负样本前面,因此记为5
p=0.8的真实正样本,它在所有5个负样本前面,因此记为5
p=0.7的真实正样本,它在所有5个负样本前面,因此记为5
p=0.6的真实正样本,它在4个负样本前面,因此记为4
p=0.4的真实正样本,它在3个负样本前面,因此记为3
交叉区域记为5*5=25
因此最终的AUC记为
![[公式]](https://img-blog.csdnimg.cn/674cb0d29bf34c97bb7ca9612444df77.png)
假设我们有一个分类器,输出是样本输入正例的概率,所有的样本都会有一个相应的概率,这样我们可以得到下面这个图:

——其中,横轴表示预测为正例的概率,纵轴表示样本数。
所以,蓝色区域表示所有负例样本的概率分布,红色样本表示所有正例样本的概率分布。显然,如果我们希望分类效果最好的话,那么红色区域越接近1越好,蓝色区域越接近0越好。
为了验证你的分类器的效果。你需要选择一个阈值,比这个阈值大的预测为正例,比这个阈值小的预测为负例。如下图:

在这个图中,阈值选择了0.5于是左边的样本都被认为是负例,右边的样本都被认为是正例。可以看到,红色区域与蓝色区域是有重叠的,所以当阈值为0.5的时候,我们可以计算出准确率为90%.
好,现在我们来引入ROC曲线

图中左上角就是ROC曲线,其中横轴就是前面说的FPR(False Positive Rate),纵轴就是TPR(True Positive Rate)。
然后我们选择不同的阈值时,就可以对应坐标系中一个点。

当阈值为0.8时,对应上图箭头所指的点。

当阈值为0.5时,对应上图箭头所指的点。
这样,不同的阈值对应不同的点。最后所有的点就可以连在一起形成一条曲线,就是ROC曲线。
现在我们来看看,如果蓝色区域与红色的区域发生变化,那么ROC曲线会怎么变呢?

上图中,蓝色区域与红色区域的重叠部分不多,所以可以看到ROC曲线距离左上角很近。

但是,当蓝色区域与红色区域基本重叠时,ROC曲线就和接近y=x这条线了。
综上两个图,如果我们想要用ROC来评估分类器的分类质量,我们就可以通过计算AUC(ROC曲线下的面积)来评估了,这就是AUC的目的。
其实,AUC表示的是正例排在负例前面的概率。
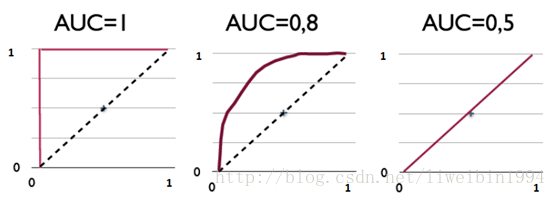
比如上图,第一个坐标系的AUC值表示,所有的正例都排在负例的前面。第二个AUC值,表示有百分之八十的正例排在负例的前面。
我们知道阈值可以取不同,也就是说,分类的结果会受到阈值的影响。如果使用AUC的话,因为阈值变动考虑到了,所以评估的效果更好。
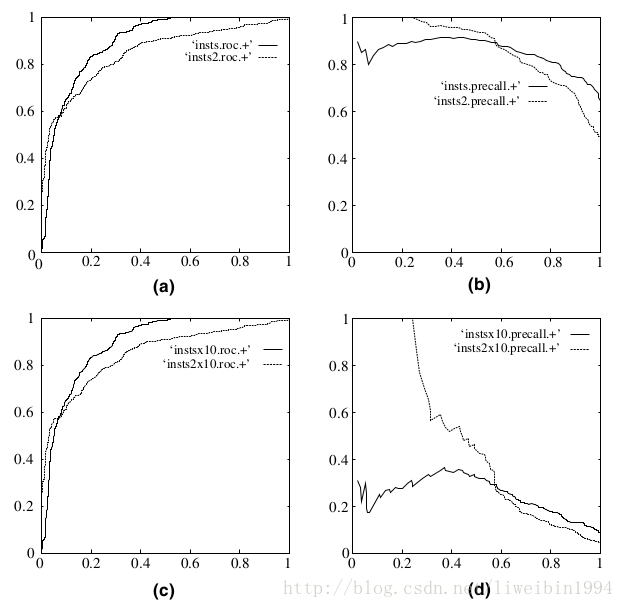
另一个好处是,ROC曲线有一个很好的特性:当测试集中的正负样本分布发生变化了,ROC曲线可以保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。

在上图中,(a)和©为ROC曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,©和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。
GAUC
auc在传统的机器学习二分类中还是很能打的,但是有一种场景,虽然是分类模型,但是却不适用auc,即广告推荐领域。
推荐领域使用的CTR(点击率)来作为最终的商用指标,但是在训练推荐模型时,却不用这个指标,用的是GAUC, 为什么呢,
因为推荐模型目前比较成熟的模式是训练分类模型,这个分类模型的任务是预测用户是否会点击给定的商品,因此,推荐系统的核心,仍然是一个二分类问题,但是是更细力度的二分类。
总结:传统的AUC可以评判二分类,但是推荐领域要算的是对于每个人的二分类结果
给定如下情形:
我们准备训练一个模型用来预测用户A和用户B购买iphone、华为和小米的可能性,我们训练了模型α

对于所有出现的概率值:我们可以计算得到AUC为 ![[公式]](https://img-blog.csdnimg.cn/6bd713d4a4c042a2a76d286b48aa7f28.png)
,好像预测效果不太好。但是,如果对每个用户查看AUC,则有:
用户A auc: ![[公式]](https://img-blog.csdnimg.cn/e27cde23e3814b9e8d6f9fa3c7ec7413.png)
用户B auc: ![[公式]](https://img-blog.csdnimg.cn/fdff31dace614d6e968bc074ded581a2.png)
也就是说这个模型其实预测地很完美!
auc的计算:
正样本:0.5,0.4,0.2
负样本:0.3,0.1
正样本3个,负样本2个,正负组合32=6种,
正样本值0.5大于负样本0.3、0.1 有两种,
正样本值0.4大于负样本0.3、0.1 有两种,
正样本值0.2大于负样本0.1 有一种,
所以正样本值大于负样本值的有2+2+1=5
所有auc为5/6=0.833 。
GAUC计算:
用户A的正样本0.5,负样本0.3,所以gauc为1;
用户B的正样本0.4,0.2,负样本0.1,正负组合为21种,正样本值大于负样本值有2种,
所以gauc为1
auc反映的是整体样本间的一个排序能力, 而在计算广告领域,我们实际要衡量的是不同用户对不同广告之间的排序能力,因此实际应该更关注的是同一个用户对不同广告间的排序能力。
GAUC(group auc)实际是计算每个用户的auc,然后加权平均,最后得到group auc,这样就能减少不同用户间的排序结果不太好比较这一影响。
group auc具体公式如下:
实际处理时权重一般可以设为每个用户view或click的次数,而且会过滤掉单个用户全是正样本或负样本的情况。
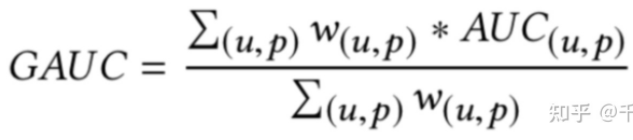
参考:
原文链接:https://blog.csdn.net/liweibin1994/article/details/79462554
https://www.zybuluo.com/frank-shaw/note/152851
https://www.zhihu.com/question/39840928?from=profile_question_card
http://blog.csdn.net/cherrylvlei/article/details/52958720
http://www.dataschool.io/roc-curves-and-auc-explained/
https://link.zhihu.com/?target=https%3A//blog.csdn.net/zhaohang_1/article/details/92794489
https://zhuanlan.zhihu.com/p/84350940