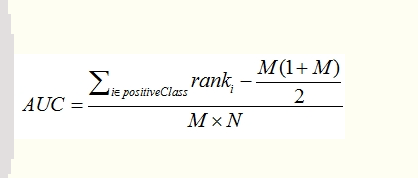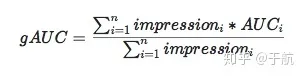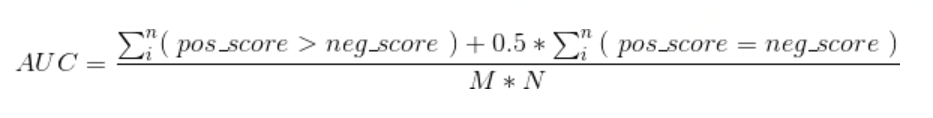1.什么是AUC?
推荐 搜索场景下的auc理解_凝眸伏笔的博客-CSDN博客_搜索auc
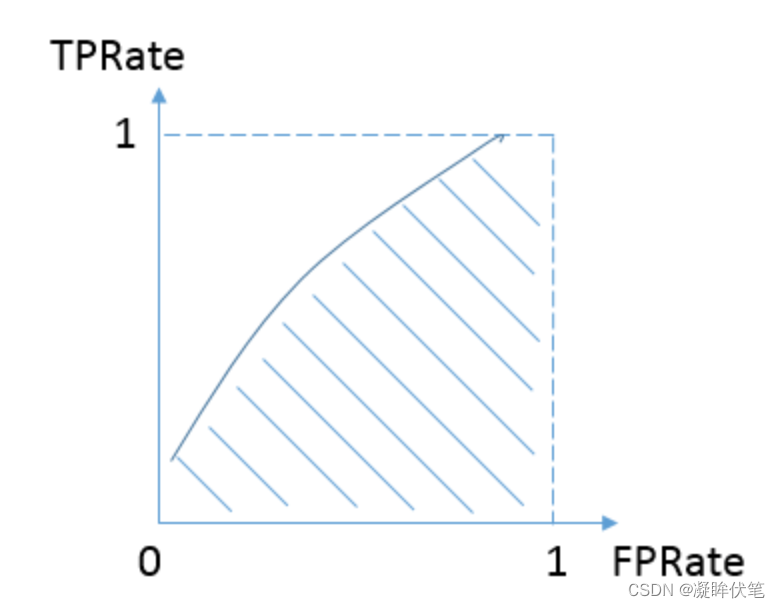
随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类器来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率。
![]()
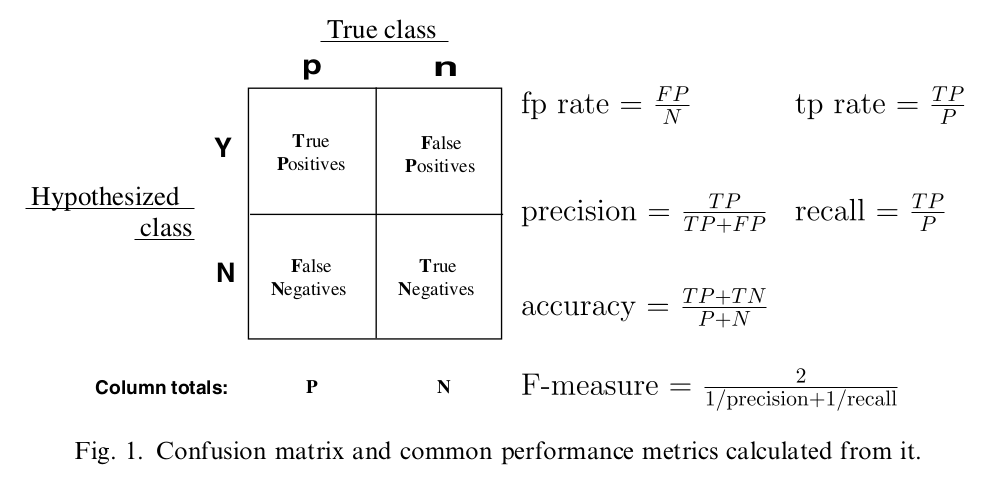
- TPRate的意义是所有真实类别为1的样本中,预测类别为1的比例。:真正率
- FPRate的意义是所有真实类别为0的样本中,预测类别为1的比例。:假正率
AUC的优势:
AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。
2.AUC对均匀正负样本采样不敏感
正由于AUC对分值本身不敏感,故常见的正负样本采样,并不会导致auc的变化。比如在点击率预估中,处于计算资源的考虑,有时候会对负样本做负采样,但由于采样完后并不影响正负样本的顺序分布。
3.AUC值本身有何意义
我们在实际业务中,常常会发现点击率模型的auc要低于购买转化率模型的auc。正如前文所提,AUC代表模型预估样本之间的排序关系,即正负样本之间预测的gap越大,auc越大.
4.如何计算AUC?
计算AUC时,推荐2个方法。
方法一:
在有M个正样本,N个负样本的数据集里。一共有M*N对样本(一对样本即,一个正样本与一个负样本)。统计这M*N对样本里,正样本的预测概率大于负样本的预测概率的个数。
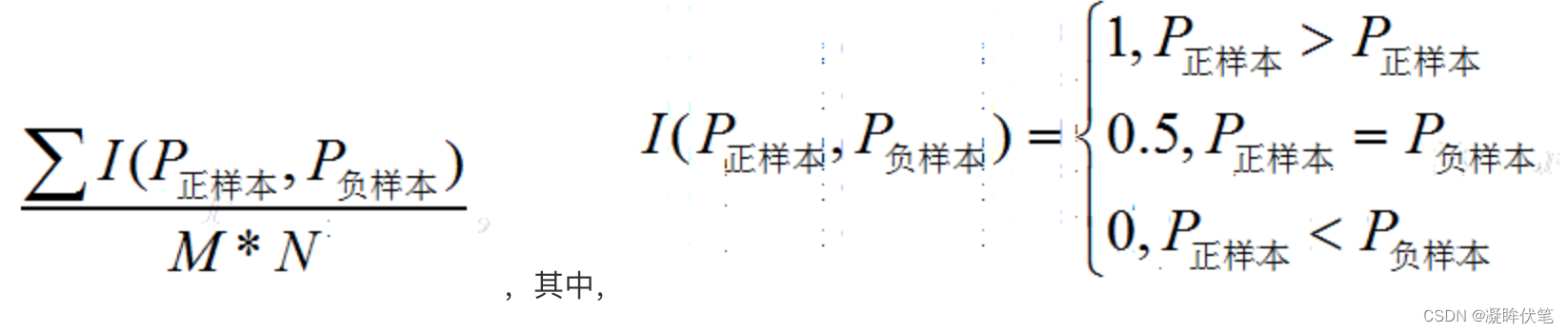
举一个例子:
| ID | label | pro |
| A | 0 | 0.1 |
| B | 0 | 0.4 |
| C | 1 | 0.35 |
| D | 1 | 0.8 |
假设有4条样本。2个正样本,2个负样本,那么M*N=4。即总共有4个样本对。分别是:
(D,B),(D,A),(C,B),(C,A)。在(D,B)样本对中,正样本D预测的概率大于负样本B预测的概率(也就是D的得分比B高),记为1,同理,对于(C,B)。正样本C预测的概率小于负样本C预测的概率,记为0.最后可以算得,总共有3个符合正样本得分高于负样本得分,故最后的AUC为(1+1+1+0)/4 = 0.75
在这个案例里,没有出现得分一致的情况,假如出现得分一致的时候,例如:
| ID | label | pro |
| A | 0 | 0.1 |
| B | 0 | 0.4 |
| C | 1 | 0.4 |
| D | 1 | 0.8 |
同样本是4个样本对,对于样本对(C,B)其I值为0.5。
最后的AUC为 (1+1+1+0.5)/4 = 0.875
方法二:
另外一个方法就是利用下面的公式:
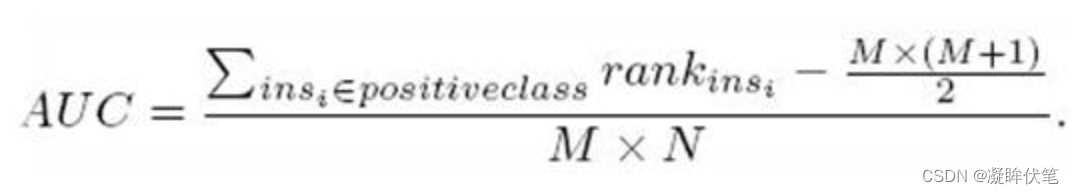

例子:
| ID | label | pro |
| A | 0 | 0.1 |
| B | 0 | 0.4 |
| C | 1 | 0.35 |
| D | 1 | 0.8 |
将这个例子排序。按概率排序后得到:
| ID | label | pro | rank |
| A | 0 | 0.1 | 1 |
| C | 1 | 0.35 | 2 |
| B | 0 | 0.4 | 3 |
| D | 1 | 0.8 | 4 |
按照上面的公式,只把正样本的序号加起来也就是只把样本C,D的rank值加起来后减去一个常数项:M(M+1)/2 =[ (4+2) -2*(2+1)/2]/2*2=0.75
这个时候,我们有个问题,假如出现得分一致的情况怎么办?下面举一个例子说明:
| ID | label | pro |
| A | 1 | 0.8 |
| B | 1 | 0.7 |
| C | 0 | 0.5 |
| D | 0 | 0.5 |
| E | 1 | 0.5 |
| F | 1 | 0.5 |
| G | 0 | 0.3 |
在这个例子中,我们有4个取值概率为0.5,而且既有正样本也有负样本的情况。计算的时候,其实原则就是相等得分的rank取平均值。具体来说如下:
先排序:
| ID | label | pro | rank |
| G | 0 | 0.3 | 1 |
| F | 1 | 0.5 | 2 |
| E | 1 | 0.5 | 3 |
| D | 0 | 0.5 | 4 |
| C | 0 | 0.5 | 5 |
| B | 1 | 0.7 | 6 |
| A | 1 | 0.8 | 7 |
这里需要注意的是:相等概率得分的样本,无论正负,谁在前,谁在后无所谓。
由于只考虑正样本的rank值:
对于正样本A,其rank值为7
对于正样本B,其rank值为6
对于正样本E,其rank值为(5+4+3+2)/4
对于正样本F,其rank值为(5+4+3+2)/4
最后我们得到:
[ (7 + 6 + ) + (5+4+3+2)/4 + (5+4+3+2)/4 - 4(4+1)/2] / 4*3 = 10/12=5/6
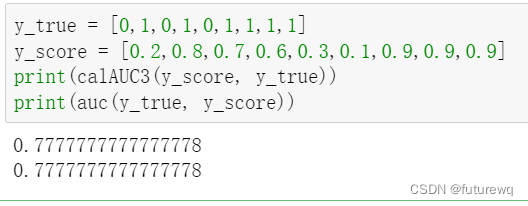
其python的代码:
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([1,1,0,0,1,1,0])
y_scores = np.array([0.8,0.7,0.5,0.5,0.5,0.5,0.3])
print "y_true is ",y_true
print "y_scores is ",y_scores
print "AUC is",roc_auc_score(y_true, y_scores)y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print "y_true is ",y_true
print "y_scores is ",y_scores
print "AUC is ",roc_auc_score(y_true, y_scores)
其他:
1.为什么auc和logloss比accuracy更常用?
答:模型分类问题预测得到的是概率,如果需要计算accuracy,则需要对这个概率设置一个阈值,而这个阈值极大的影响了accuracy的计算。使用auc和logloss避免把概率准换为类别。可以直接使用预测得到的概率来计算。
除此之外,虽然准确率可以判断总的正确率,但是在样本不平衡的情况下,并不能作为很好的指标来衡量结果。由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
2.精准率
精准率(Precision)又叫查准率,它是针对预测结果而言的,它的含义是在所有被预测为正的样本中实际为正的样本的概率,意思就是在预测为正样本的结果中,我们有多少把握可以预测正确,其公式如下:
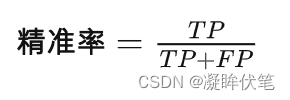
3. 召回率
召回率(Recall)又叫查全率,它是针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率,其公式如下:
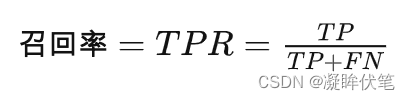
召回率的应用场景:比如拿网贷违约率为例,相对好用户,我们更关心坏用户,不能错放过任何一个坏用户。因为如果我们过多的将坏用户当成好用户,这样后续可能发生的违约金额会远超过好用户偿还的借贷利息金额,造成严重偿失。召回率越高,代表实际坏用户被预测出来的概率越高,它的含义类似:宁可错杀一千,绝不放过一个。
参考:
1. AUC的计算方法_kingsam_的博客-CSDN博客_auc计算公式
2.如何理解机器学习和统计中的AUC? - 知乎