目录
概述
为什么持续集成和发布可以提高效率
如何实现
1、在linux服务器安装部署代码仓库
2、安装jenkins
使用shell脚本实现CICD
使用pipeline实现CICD
使用Blue Ocean实现CICD
概述

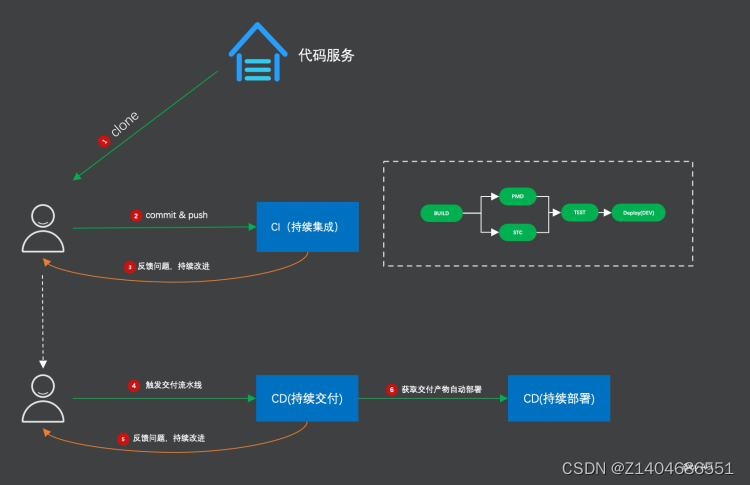
持续集成(Continuous Integration,CI)和持续发布(Continuous Delivery,CD,又称持续交付)是经常放在一起提及的两个概念,专有词组CI/CD Pipeline 用来描述他们同时存在的持续集成与发布自动化管线。
持续集成是一种编程实践,它让开发团队通过实现对代码一系列小的改动,高频率地提交到版本管理源。现代程序需要依赖大量平台与工具链,需要一种行之有效的方式去反复确认每个改动的正确性。持续集成在技术上的目标是建立一个自动化、工序稳定一致的工作饰程。这种流程包括编译代码、打包编译输出,以及测试最终生成的结果。这种稳定一致并可以反复执行的流程,让开发人员可以更加频繁地提交改动,从而提升合作效率和代码质量。通过持续集成,团队可以快速的从一个功能到另一个功能,简而言之,敏捷软件开发很大一部分都要归功于持续集成。
持续发布是在持续集成之后的一系列动作。持续发布自动化交付生成的产品到各个目标环境,如测试环境、审查环境和生产环境等,以用于不同的目的。除了生产环境外,多数的团队都会面对各种不同的环境,如开发人员使用的开发环境、测试人员使用的测试环境。持续发布可以保证各种修改以一种稳定、符合预期的方式交付到这些环境上。在发布的过程中,除了把持续集成的最终产物复制到目标环境外,持续交付通常还会跟外部的Web API、数据库和其他服务通信,让新的改动最终在目标环境生效。
为什么持续集成和发布可以提高效率
持续集成与发布有一套与之相伴的版本管理实践来指导团队之间的合作。而通过加入大量的自动化流程,持续集成与发布极大地减少了试错的成本和人为的错误。
1.更加高效的合作模式:持续集成作为一种实践,依赖于对工作流程的管理和自动化。当使用持续集成时,开发人员高频率地提交他们的代码到版本管理源中,有些团队甚至会对提交的频率作具体的要求,如每天一次。这种要求的原因是比起一大段需要数天甚至一个月写成的代码,一段段小规模的代码改动更容易定位质量问题。另外,通常代码是对整个团队的人开放的,如果开发人员的提交周期非常短,那么就可以避免出现多人共同编辑同一段代码,最终产生冲突的情况。当用户实现持续集成时,通常用户会从版本管理源的配置开始。虽然用户高频率地提交代码,但是一个新特性或者一段对错误的修复往往由多次代码提交组成,这些提交代码的时间跨度有长有短。团队需要通过版本管理和持续集成的结果来选择和判断哪些改动可以更新到生产环境。
能对多个并行开发的特性实施有效管理的其中一种方式是版本管理系统中的分支管理。分支策略有很多种,其中之一被称为Git流程,它定义了一系列基于源码分支的合作流程,如新的代码应该放在什么分支,如何命名,如何合并入其他主干分支,如开发分支、测试分支和最终生产分支。对于需要长时间开发的特性,也会使用专门的副主干分支,用于其他更细小分支的并入。当一个新特性完整之后,这个新特性代表的分支将会被合并入主干分支。这种工作方式最大的挑战是当大量特性在并行开发的时候,如何管理这些分支的合并。
2.减少试错成本:在持续集成与发布的概念出现之前,对于代码的改动,开发人员需要自行把编译结果进行一系列的编译打包操作,在业内缺乏统一的指导思想去优化整体的流程。这些冗长的重复性劳动极大地打击了开发人员的积极性,开发人员从而倾向于一次性提交大量的代码,以减少测试和部署的频率。由于测试的频率降低了,一个错误往往要在更长的开发周期后才会被发现,这种“一次性提交大量的代码”的偏好反而又增加了开发人员的其他时间成本,被称之为试错成本。
3.减少人为错误:对于大量重复性的工作,在一些流程严谨的公司里,也许会通过详细的文档来描述每一个步骤应该如何正确地执行。但是这远远无法减少人为的错误。正如那句计算机领域的谚语“如果一个人工操作的步骤存在犯错的可能,那么它必然会有犯错的一天”。减少人为犯错的空间,与尽可能自动化一切是两个在工程领域相互关联、相互促进的主题。
持续发布与集成,通过脚本和配置把所有的流程都完全自动化,最大限度地减少人为犯错的空间。而且由于整个流程稳定、可重复,对于流程或者具体脚本中出现的错误,用户都可以轻易对其进行改进和测试,而不会出现人们“随机犯错”的情况。
如何实现
1、在linux服务器安装部署代码仓库
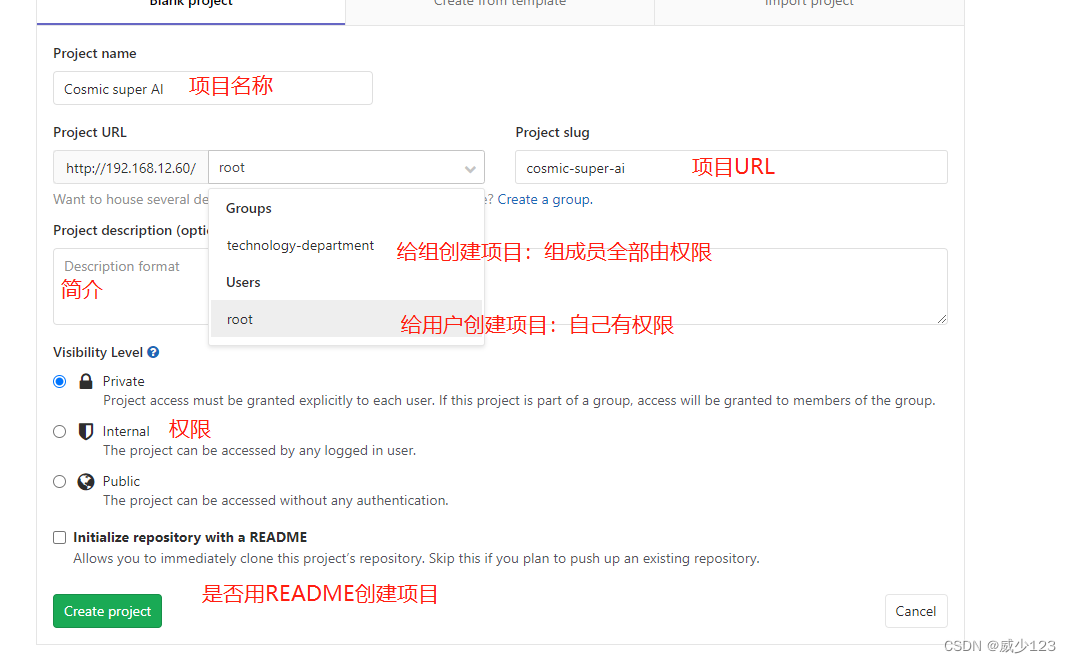
持续集成需要一个代码存储库,即需要版本控制软件来保障代码的可维护性,同时作为构建过程的素材库,Gitlab是依赖于Git的远程代码仓库,类似于GitHub、Gitee,不同的是GitHub、Gitee的公网上代码仓库, Gitlab是可以私有化部署的免费远程代码仓库,官网:https://about.gitlab.com/
1、准备服务器10.0.0.7 gitlab 2、下载安装包
wget https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el7/gitlab-ce-13.0.3-ce.0.el7.x86_64.rpm3、安装GitLab
# 安装依赖包
[root@gitlab /opt]# yum install -y curl policycoreutils-python openssh-server perl
# 关闭防火墙
[root@gitlab /opt]# systemctl disable --now firewalld
# 关闭selinux
[root@gitlab /opt]# sed -i 's#enforcing#disabled#g' /etc/sysconfig/selinux
# 临时关闭
[root@gitlab /opt]# setenforce 0
# 安装
[root@gitlab /opt]# yum install gitlab-ce-13.0.3-ce.0.el7.x86_64.rpm
# 修改配置文件
[root@sean ~]# vim /etc/gitlab/gitlab.rb
external_url 'http://10.0.0.7'
nginx['listen_port'] = 80
# 刷新配置(默认启动)
gitlab-ctl reconfigure安装后访问gitlab私库http://10.0.0.7/,创建用户组、用户及项目,其中组内成员有如下几种权限
1.Guest:可以创建issue、发表评论,不能读写版本库
2.Reporter:可以克隆代码,不能提交,QA、PM 可以赋予这个权限
3.Developer:可以克隆代码、开发、提交、push,普通开发可以赋予这个权限
4.Maintainer:可以创建项目、添加tag、保护分支、添加项目成员、编辑项目,核心开发可以赋予这个 权限
5.Owner:可以设置项目访问权限 - Visibility Level、删除项目、迁移项目、管理组成员,开发组组 长可以赋予这个权限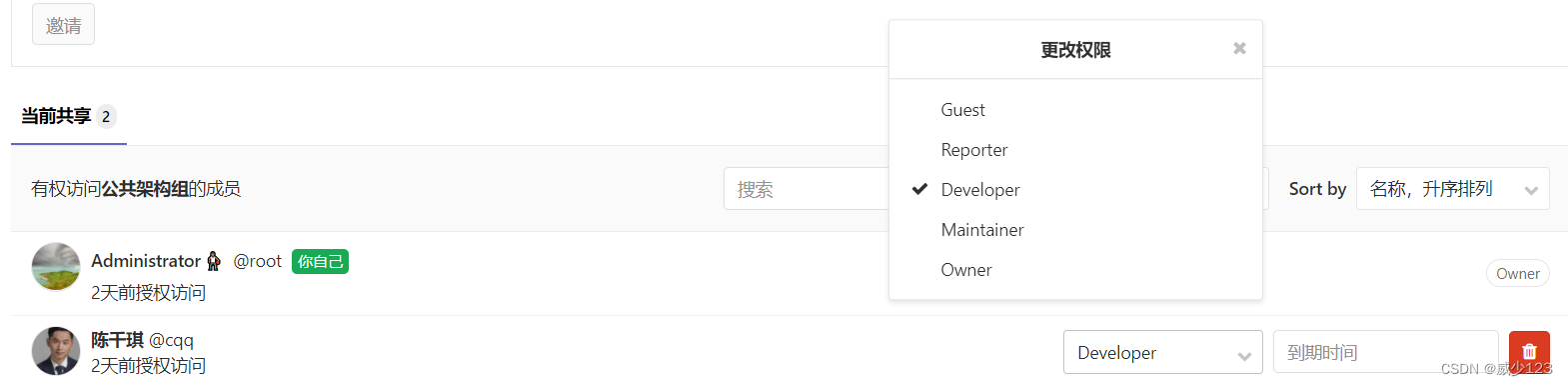
2、安装jenkins
持续集成需要一个持续集成服务器, Jenkins 就是一个配置简单和使用方便的持续集成服务器。依赖于Java开发的,由各种组件组成的一个自动化部署工具。
Jenkins自由风格主要的部署步骤:参数化构建->源代码管理->构建->构建后操作
1、安装Java
[root@localhost opt]# yum install java-1.8.0-openjdk* -y2、安装Jenkins
[root@localhost opt]# rpm --import https://pkg.jenkins.io/redhat-stable/jenkins.io.key
[root@localhost opt]# yum install -y jenkins-2.249.1-1.1.noarch.rpm
[root@localhost opt]# systemctl start jenkins3、登陆密码
[root@localhost opt]# cat /var/lib/jenkins/secrets/initialAdminPassword
edfcd0f0432a4a868dc32da0c34f7f3a4、安装插件
[root@localhost updates]# tar -xf /opt/plugins.tar.gz -C /var/lib/jenkins/5、Jenkins 优化
[root@localhost updates]# cd /var/lib/jenkins/updates
[root@localhost updates]# sed -i 's/http:\/\/updates.jenkinsci.org\/download/https:\/\/mirrors.tuna.tsinghua.edu.cn\/jenkins/g' default.json
[root@localhost updates]# sed -i 's/http:\/\/www.google.com/https:\/\/www.baidu.com/g' default.json# 最后,系统管理 --> 插件管理 --> 高级,把站点升级改为国内插件下载地址
https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json创建用户
创建权限组
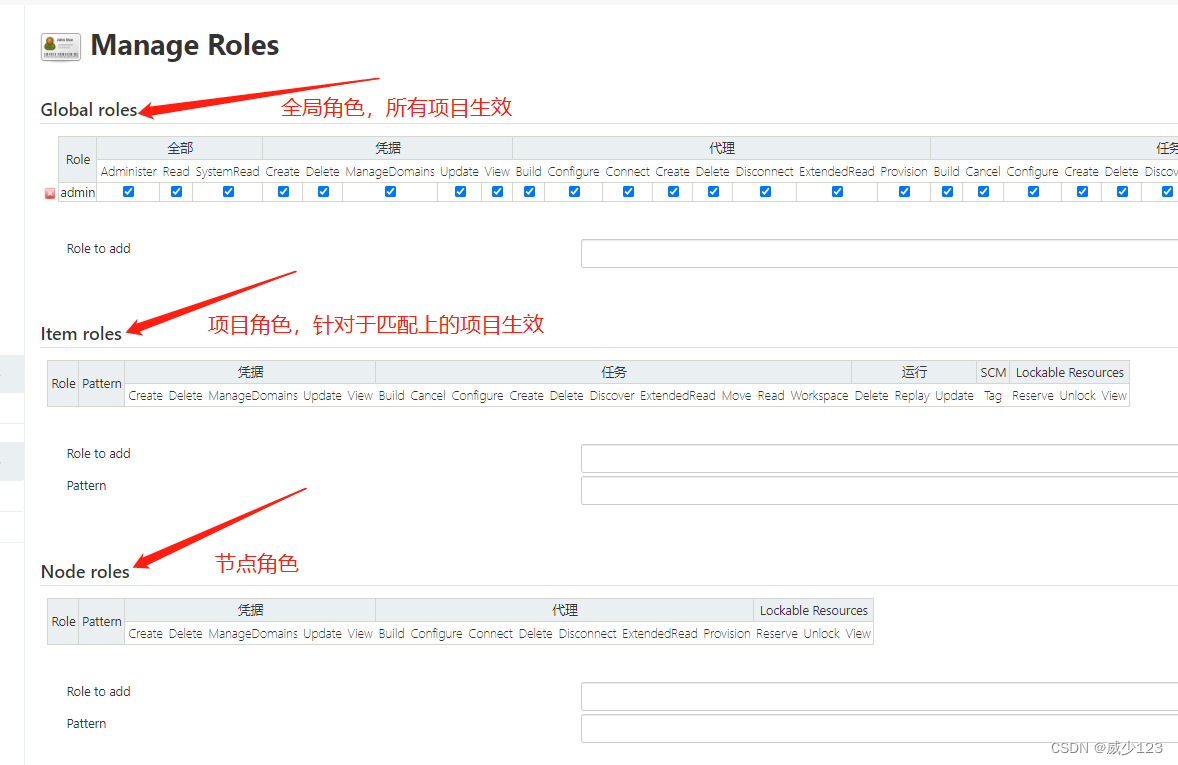
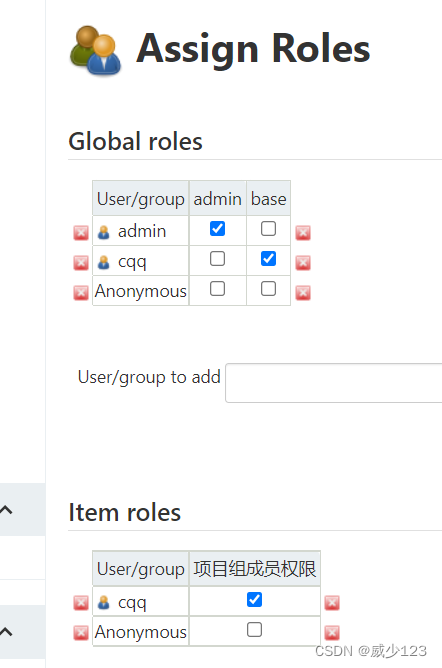
分配权限
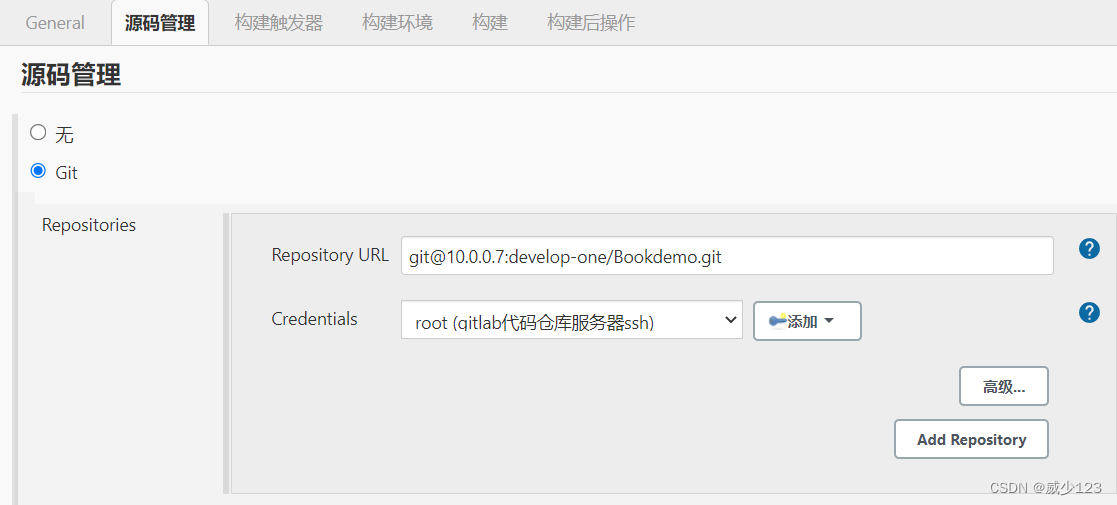
由于jenkins构建项目中的源码是从git拉取,因此需要配置凭证方能拉取成功
- 系统管理 ---> Manage Credentials ---> 系统凭证 ---> 全局凭证 ---> 添加凭证 ---> Username with Password(远程仓库的用户密码)
- 系统管理 ---> Manage Credentials ---> 系统凭证 ---> 全局凭证 ---> 添加凭证 ---> ssh username with private key(需先在远程仓库设置中配置jenkins服务器公钥,再填入jenkins服务器私钥)

配置完后就可以拉取代码到工作目录,然后进行构建和发布,工作目录默认在/var/lib/jenkins/workspace
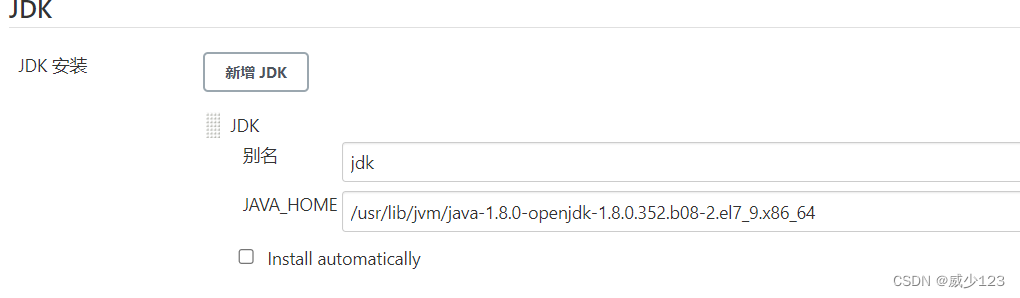
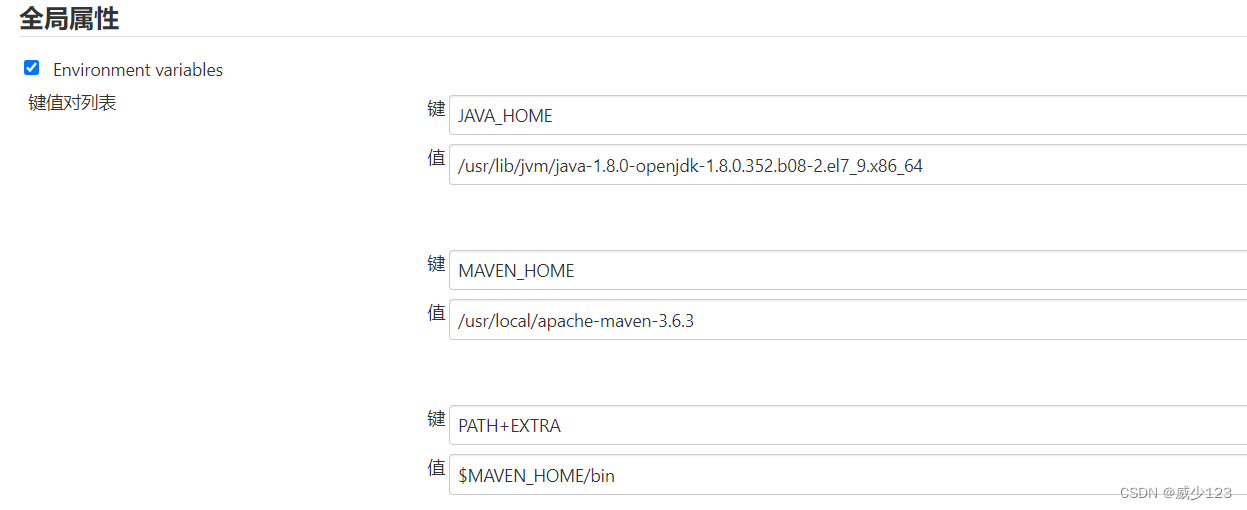
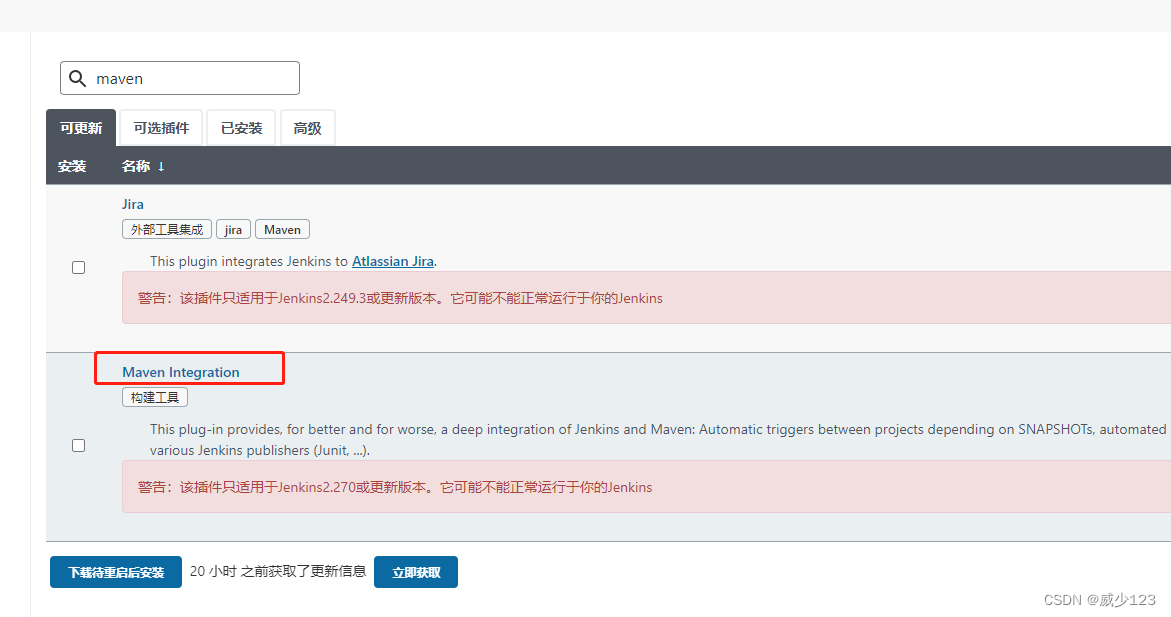
如果是发布maven工程,需要在jenkins服务器安装java,maven,并在全局工具配置java,在系统配置中配置maven,再安装maven集成插件
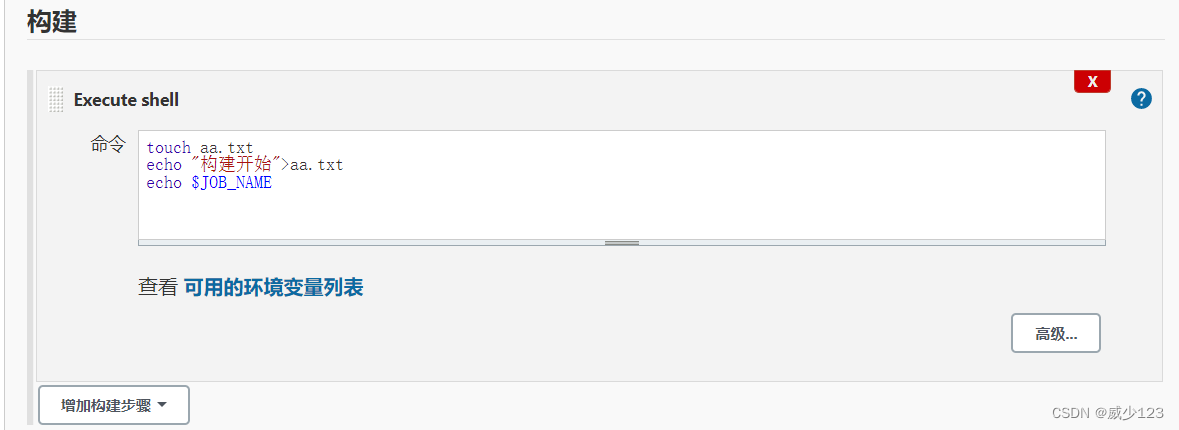
持续集成需要一个自动构建过程,从检出代码、编译构建、运行测试、结果记录、测试统计等都是自动完成的,无需人工干预,如下几种方式均可实现
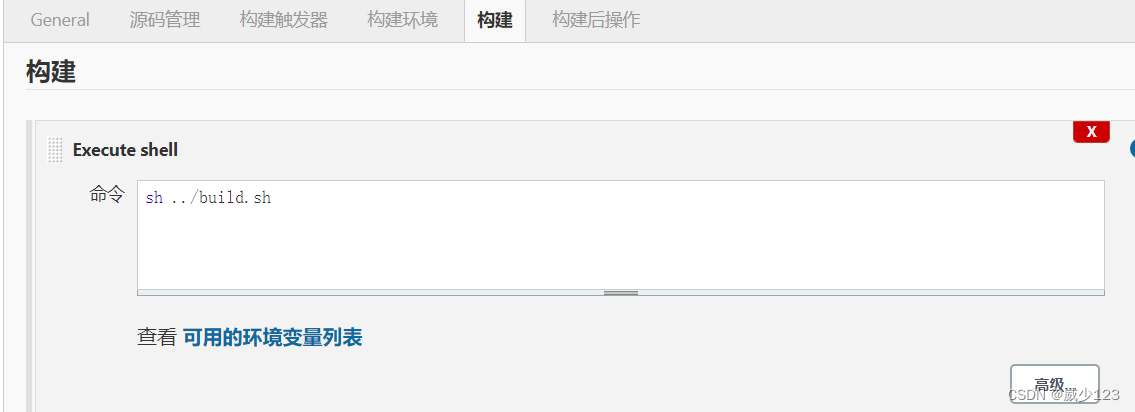
使用shell脚本实现CICD
直接执行脚本,在jenkins服务器进行编译,在部署服务器进行发布,若批量部署,可以使用ansible
#!/bin/bash
set -xe
function process() {if [ $1 -ne 0 ]; thenecho "deploy fail"exit 1fi
}
echo "构建开始"
git checkout $GIT_TAG
mvn clean package -D skipTests
process $?
sshpass -p '部署服务器密码' scp target/*.jar root@10.0.0.7:/application
process $?
sshpass -p "部署服务器密码" ssh -o StrictHostKeyChecking=no root@10.0.0.7 "cd /application;chmod 777 *.jar;kill -9 `ps -ef|grep java|grep 8081|awk '{print $2}'`;nohup java -jar *.jar --server.port=8081>deploy.log &"
process $?
echo "deploy success"
set +x
echo "构建结束" 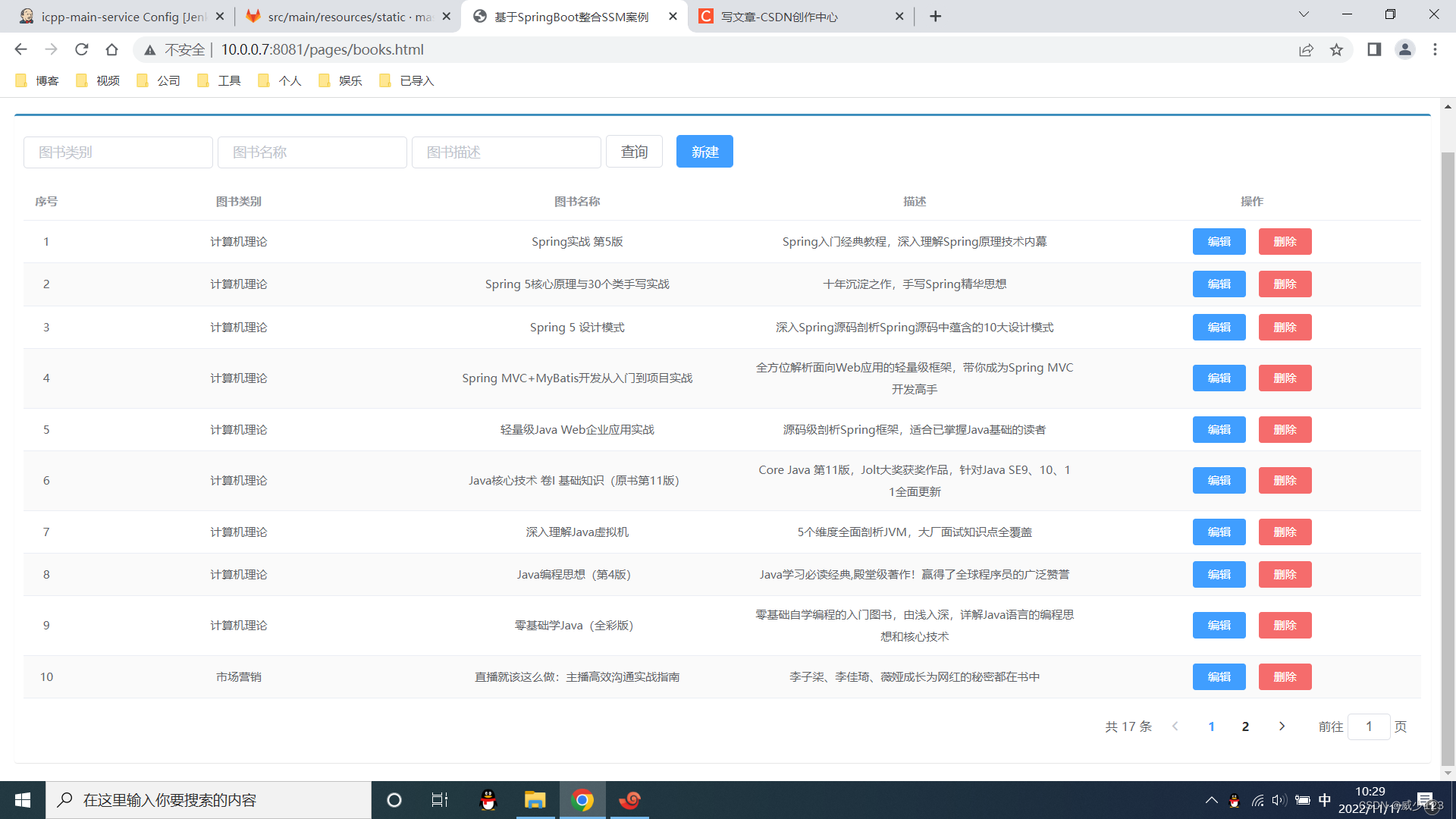
使用pipeline实现CICD
创建一个流水线


编写pipeline脚本
pipeline {agent anystages {stage('pull code') {steps {checkout scmGit(branches: [[name: '*/master']], extensions: [], userRemoteConfigs: [[credentialsId: 'gitee', url: 'https://gitee.com/chenqianqi/web_demo.git']])}}stage('code checking') {steps {script {//引入SonarQubeScanner工具scannerHome = tool 'SonarQube-Scanner'}//引入SonarQube的服务器环境withSonarQubeEnv('sonarqube') {sh "${scannerHome}/bin/sonar-scanner"}}}stage('build project') {steps {sh 'mvn clean package'}}stage('publish project') {steps {deploy adapters: [tomcat8(credentialsId: 'c4512fa0-4a20-41ff-a86b-4f38092baeea', path: '', url: 'http://10.0.0.7:8084/')], contextPath: null, war: 'target/*.war'}}}post {always {emailext(subject: '构建通知:${PROJECT_NAME} - Build # ${BUILD_NUMBER} - ${BUILD_STATUS}!',body: '${FILE,path="email.html"}',to: '291887741@qq.com')}}
}
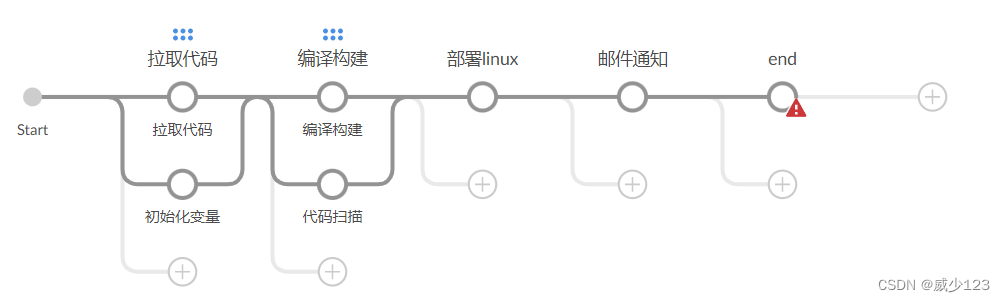
使用Blue Ocean实现CICD


![人人都能用Python写出LSTM-RNN的代码![你的神经网络学习最佳起步]](https://img-blog.csdnimg.cn/img_convert/cfca0b70e6d14e6cd1e0ae5c87f3b8aa.png)