数据挖掘之关联分析
- 算法实现:Apriori算法和FP-growth 算法
- 源代码
简单描述下,关联分析概念
关联分析概念主要参考下面的博文
原文:https://blog.csdn.net/qq_40587575/article/details/81022350
关联分析是从大量数据中发现项集之间有趣的关联和相关联系,而关联分析的最终目标就是要找出强关联规则。
•关联分析的基本概念:
1、事务:每一条交易称为一个事务,如上图包含5个事务。
2、项:交易的每一个物品称为一个项,例如豆奶,啤酒等。
3、项集:包含零个或多个项的集合叫做项集,例如{尿布,啤酒}。
4、k−项集:包含k个项的项集叫做k-项集,例如 {豆奶,橙汁}叫做2-项集。
5、支持度计数:一个项集出现在几个事务当中,它的支持度计数就是几。
例如{尿布, 啤酒}出现在事务002、003和005中,所以 它的支持度计数是3。
6、支持度:支持度计数除于总的事务数。
例如上例中总的事务数为5,{尿布, 啤酒}的支持度计数为3,所以它的支持度是 3÷5=60%,说明有60%的人同时买了尿布, 啤酒。
7、频繁项集:支持度大于或等于某个阈值的项集就叫做频繁项集。例如阈值设为50%时,因为{尿布,啤酒}的支持度是60%,所以 它是频繁项集。
8、前件和后件:对于规则{尿布}→{啤酒},{Diaper}叫做前件,{啤酒}叫做后件。
9、置信度:对于规则{尿布}→{啤酒},{尿布,啤酒}的支持度计数除于{尿布}的支持度计数,为这个规则的置信度。
例如规则{尿布}→{啤酒}的置信度为3÷3=100%。说明买了尿布的人100%也买了啤酒。
10、强关联规则:大于或等于最小支持度阈值和最小置信度阈值的规则叫做强关联规则
算法实现:Apriori算法和FP-growth 算法
其余的基本概念可以去其他博客大佬们观摩啦!
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
接下来,就是我自己的实验内容,我主要写的是一个关于关联分析的实验例子:
首先先引入各种包,再读取数据,数据用的虚拟伪造“泰塔号”事故的数据集(一共700条数据),主要目的是关联分析“泰塔号”船上的乘客的一些属性的关系
第一,是有无船舱(cabin),第二,是船的费用大于10¥和小于10¥的关联(fare),第三,是否生还(survived)
下面是引入包,还有读取csv格式的数据,最后组合三种属性成为3个元祖。
import csv
import pandas as pd
import sys
import numpy as np#读取892行数据
Survived = pd.read_csv('f:/train.csv', usecols=['Survived'],nrows=892)data_category1 = Survived.values
List_category1 = []
for k in data_category1: for j in k: List_category1.append(j)
Cabin = pd.read_csv('f:/train.csv', usecols=['Cabin'],nrows=892)
data_category2 = Cabin.values
List_category2 = []
for k in data_category2: for j in k: List_category2.append(j)
Fare = pd.read_csv('f:/train.csv', usecols=['Fare'],nrows=892)
data_category3 = Fare.values
List_category3 = []
for k in data_category3: for j in k: List_category3.append(j)#组合3个元祖
z = list(zip(List_category1,List_category2,List_category3))
对数据进行处理,有无生还(1为存活,空为狗带),有无船舱(1为有,空为无),费用fare(fare大于10,和小于10的)。
#将数量转化成商品名称
#fare大于10则输入数据,否则删除数据
#survived和cabin则通过判断是否为空来输入或删除数据
for k in z1:index = z1.index(k)if k[2] >10:z2[index][2] = 'Fare'else:del z2[index][2]if k[1] == k[1]:z2[index][1] = 'Cabin'else:del z2[index][1]if k[0] == k[0]:z2[index][0] = 'Survived'else:del z2[index][0]
pass
最后我们打印各级的项集:
if __name__ == "__main__":"""Test"""data_set = load_data_set()L, support_data = generate_L(data_set, k=3, min_support=0.1)#将限制概率调制0.6,低于0.6不显示big_rules_list = generate_big_rules(L, support_data, min_conf=0.6)for Lk in L:print("="*50)print("frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport")print("="*50)for freq_set in Lk:print(freq_set, support_data[freq_set])printprint("Big Rules")for item in big_rules_list:print(item[0], "=>", item[1], "conf: ", item[2])
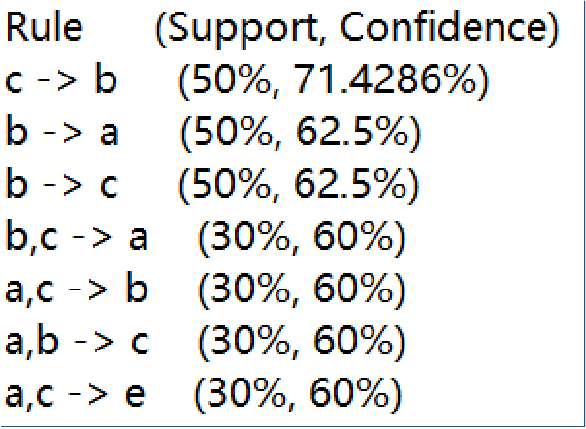
最后,得出结果是:
可以看出,{1-项集}中,船票价格fare大于10美元的人是70%,存活率是58.7%,有船舱住的人是34%.
{2-项集}中,我们主要关注,船票价格fare大于10美元的人且存活的是45.2%,有船舱住的人且存货的是21.4%
{3-项集}中,船票价格fare大于10美元的人且存货的人,概率高达77.1%,我们再次调整fare的价格限制为20美元,概率也有67%,可见船票价格fare大于10美元的人与是否存活有着一定关系。同时,有船舱的人他们的船票价格fare大于10美元的概率是97.3%,可见船上大于10美元的船舱是占巨大的比例。


源代码
import csv
import pandas as pd
import sys
import numpy as np#读取892数据
Survived = pd.read_csv('f:/train.csv', usecols=['Survived'],nrows=892)data_category1 = Survived.values
List_category1 = []
for k in data_category1: for j in k: List_category1.append(j)
Cabin = pd.read_csv('f:/train.csv', usecols=['Cabin'],nrows=892)
data_category2 = Cabin.values
List_category2 = []
for k in data_category2: for j in k: List_category2.append(j)
Fare = pd.read_csv('f:/train.csv', usecols=['Fare'],nrows=892)
data_category3 = Fare.values
List_category3 = []
for k in data_category3: for j in k: List_category3.append(j)#组合3个元祖
z = list(zip(List_category1,List_category2,List_category3))#将元祖转换为列表
for c in z:z[z.index(c)] = list(c)
pass
z1 = z.copy()#删除有两个空值的列表
for h in z1:index = z1.index(h)if h[0] != h[0] and h[1] != h[1]:del z1[index]continueelif h[0] != h[0] and h[2] != h[2]:del z1[index]continueelif h[1] != h[1] and h[2] != h[2]:del z1[index]continue
passz2 = z1.copy()#将数量转化成商品名称
for k in z1:index = z1.index(k)if k[2] >15:z2[index][2] = 'Fare'else:del z2[index][2]if k[1] == k[1]:z2[index][1] = 'Cabin'else:del z2[index][1]if k[0] == k[0]:z2[index][0] = 'Survived'else:del z2[index][0]passprint(z2)def load_data_set():data_set = z1return data_setdef create_C1(data_set):C1 = set()for t in data_set:for item in t:item_set = frozenset([item])C1.add(item_set)return C1def is_apriori(Ck_item, Lksub1):for item in Ck_item:sub_Ck = Ck_item - frozenset([item])if sub_Ck not in Lksub1:return Falsereturn Truedef create_Ck(Lksub1, k):Ck = set()len_Lksub1 = len(Lksub1)list_Lksub1 = list(Lksub1)for i in range(len_Lksub1):for j in range(1, len_Lksub1):l1 = list(list_Lksub1[i])l2 = list(list_Lksub1[j])l1.sort()l2.sort()if l1[0:k-2] == l2[0:k-2]:Ck_item = list_Lksub1[i] | list_Lksub1[j]if is_apriori(Ck_item, Lksub1):Ck.add(Ck_item)return Ckdef generate_Lk_by_Ck(data_set, Ck, min_support, support_data):Lk = set()item_count = {}for t in data_set:for item in Ck:if item.issubset(t):if item not in item_count:item_count[item] = 1else:item_count[item] += 1t_num = float(len(data_set))for item in item_count:if (item_count[item] / t_num) >= min_support:Lk.add(item)support_data[item] = item_count[item] / t_numreturn Lkdef generate_L(data_set, k, min_support):support_data = {}C1 = create_C1(data_set)L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)Lksub1 = L1.copy()L = []L.append(Lksub1)for i in range(2, k+1):Ci = create_Ck(Lksub1, i)Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)Lksub1 = Li.copy()L.append(Lksub1)return L, support_datadef generate_big_rules(L, support_data, min_conf):big_rule_list = []sub_set_list = []for i in range(0, len(L)):for freq_set in L[i]:for sub_set in sub_set_list:if sub_set.issubset(freq_set):conf = support_data[freq_set] / support_data[freq_set - sub_set]big_rule = (freq_set - sub_set, sub_set, conf)if conf >= min_conf and big_rule not in big_rule_list:big_rule_list.append(big_rule)sub_set_list.append(freq_set)return big_rule_listif __name__ == "__main__":"""Test"""data_set = load_data_set()L, support_data = generate_L(data_set, k=3, min_support=0.1)big_rules_list = generate_big_rules(L, support_data, min_conf=0.6)for Lk in L:print("="*50)print("frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport")print("="*50)for freq_set in Lk:print(freq_set, support_data[freq_set])printprint("Big Rules")for item in big_rules_list:print(item[0], "=>", item[1], "conf: ", item[2]