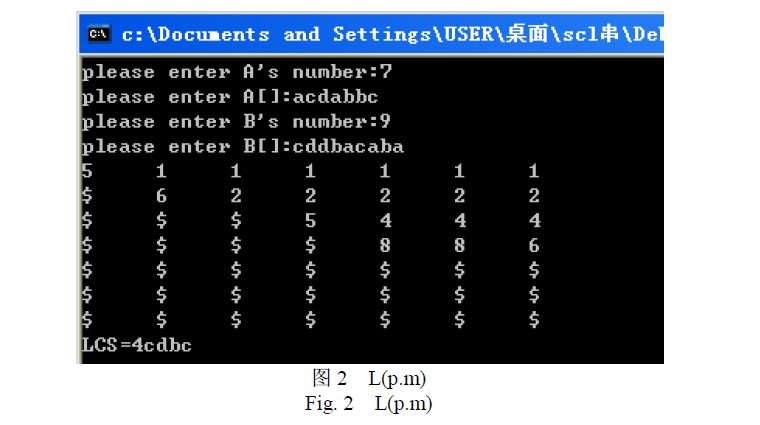
SLIC(simple linear iterativeclustering),即 简单线性迭代聚类 。
💛它是2010年提出的一种思想简单、实现方便的算法,将彩色图像转化为CIELAB颜色空间和XY坐标下的5维特征向量,然后对5维特征向量构造距离度量标准,对图像像素进行局部聚类的过程。
💛SLIC算法能生成紧凑、近似均匀的超像素,在运算速度,物体轮廓保持、超像素形状方面具有较高的综合评价,比较符合人们期望的分割效果。其实是从k-means算法演化的,算法复杂度是O(n),只与图像的像素点数有关,而与k值无关。而常规的k均值算法的复杂度是O(kni),i为迭代次数。
SLIC主要优点如下:
1)生成的超像素如同细胞一般紧凑整齐,邻域特征比较容易表达。这样基于像素的方法可以比较容易的改造为基于超像素的方法。
2)不仅可以分割彩色图,也可以兼容分割灰度图。
3)需要设置的参数非常少,默认情况下只需要设置一个预分割的超像素的数量。
4)相比其他的超像素分割方法,SLIC在运行速度、生成超像素的紧凑度、轮廓保持方面都比较理想。
超像素:
💛超像素概念是2003年Xiaofeng Ren提出和发展起来的图像分割技术。
💛是指具有相似纹理、颜色、亮度等特征的相邻像素构成的有一定视觉意义的不规则像素块。
💛它利用像素之间特征的相似性将像素分组,用少量的超像素代替大量的像素来表达图片特征(捕获图像的冗余信息),很大程度上降低了图像后处理的复杂度,所以通常作为分割算法的预处理步骤。
💛已经广泛用于图像分割、姿势估计、目标跟踪、目标识别等计算机视觉应用。需要注意的是,超像素分割算法很可能把同一个物体的不同部分分成多个超像素。
SLC的创新点:
1.SLIC限制聚类时搜索的区域(2Sx2S)————》原K均值算法中,计算的是聚类中心到图像中的每个像素的距离——》把k-means的算法复杂度降为常数,整个算法复杂度为线性

2.距离度量考虑lab颜色和xy距离,五维数据。 且可以考虑颜色和距离的比重,使超像素更加灵活。
SLIC算法步骤分析:
💚均匀撒k个种子并移动到梯度最小的地方——》为每个像素计算D并分配种子标签——》重新计算聚类中心——》增强区域连通性解决孤立点和超像素过小情况
💛对源文章过程的解析:
step1:初始化聚类中心且用五维数据表示,聚类中心 之间的间隔为S(步长s对像素进行采样,初始化聚类中心)
step2:移动聚类中心到33范围内梯度最低的地方
step3:对每一个像素i,设置label。取label第一个字母l表示label。l表示为每个像素点是属于哪个超像素,初始设置为-1
step4:对每个像素i,设置距离d(i)=正无穷 【ps.因为后面更新的时候,是根据距离数值小的点进行更新】
step5.循环以下过程————对每个聚类中心外循环,在围绕聚类中心的2s2s范围内的对每个像素i内循环—》如果距离度量值D数值小,就更新d(i)的值,将label(i)设置为所对应的超像素
step6.计算新的聚类中心和先前聚类中心位置之间的残差误差E。迭代直到错误收敛。 【ps.一般迭代10次差不多了】

1.撒种子。根据图像大小和定义的超像素数目K,将k个超像素中心均匀分布到图像的像素点上。假设图片总共有 N 个像素点,预分割为 K 个相同尺寸的超像素,那么每个超像素的大小为N/ K ,则相邻种子点的距离(步长)近似为S=sqrt(N/K)。
2.调整种子位置。以k为中心的nn(一般n取3,故为33)范围内,将超像素中心移动到这9个点中梯度最小的点上。目的是为了避免超像素点落入噪点或边界处。
3.初始化数据。在每个种子点周围的邻域内为每个像素点分配类标签lable(即该像素点是属于哪个聚类中心的)。做法:取一个数组label,保存每个像素点是属于哪个超像素。dis数据保存像素点到它属于的那个超像素中心之间的距离。
4.更新数据。对每一个超像素中心x,在其2s*2s范围内搜索;如果点到超像素中心x的距离(五维)小于点到它原来属于的超像素中心的距离,说明这个点属于超像素x。(新距离小于旧距离,则点属于新范围。更新dis,更新label)----》每个像素必须与所有聚类中心比较,通过引入距离测量D值。**【期望的超像素尺寸为SS,但是搜索的范围是2S2S】【由于每个像素点都会被多个种子点搜索到,所以每个像素点都会有一个与周围种子点的距离,取最小值对应的种子点作为该像素点的聚类中心。】**
5.计算。对每一个超像素中心,重新计算它的位置(属于该超像素的所有像素的位置中心)以及lab值。
6.迭代4、5步骤。【理论上上述步骤不断迭代直到误差收敛(可以理解为每个像素点聚类中心不再发生变化为止),实践发现10次迭代对绝大部分图片都可以得到较理想效果,所以一般迭代次数取10。】
后处理步骤:
可能存在不属于任何聚类的孤立像素,可以使用联通分量算法对这些像素分配最近聚类中心的标签。
💛增强连通性。经过上述迭代优化可能出现以下瑕疵:出现多连通情况、超像素尺寸过小,单个超像素被切割成多个不连续超像素等,这些情况可以通过增强连通性解决。
💛主要思路是:新建一张标记表,表内元素均为-1,按照“Z”型走向(从左到右,从上到下顺序)将不连续的超像素、尺寸过小超像素重新分配给邻近的超像素,遍历过的像素点分配给相应的标签,直到所有点遍历完毕为止。
关键步骤:
4和5【用到了k-means算法的思想】
💛步骤4相当于:知道超像素点,然后再给定一系列像素点。将像素点分类到某一超像素类中。
💛步骤5相当于:计算某类超像素类中,像素点的中心,然后让超像素点移动到刚才计算出来的中心位置。
💛迭代相当于:再让所有像素点分到某一超像素圈圈中,然后重新计算像素点中的中心,移动超像素中心到刚才的中心。然后重复。

注意:SLIC和K-means的区别是SLIC加快了计算速度,即,进行步骤4时只计算超像素中心有限范围内的点。
Lab彩色空间介绍:
L:亮度。值域为0(黑)~100(白)
a:从洋红色至绿色的范围。(a为负数指代绿色,a为正数指代品红色)
b:从黄色至蓝色的范围。(b为负数指代蓝色,b为正数指代黄色)
💛LAB彩色模型的最大优点:弥补了RGB彩色模型中色彩不均匀的缺点。因为RGB模型在蓝色到绿色之间的过渡色彩过多,而绿色到红色之间又缺少黄色和其他颜色。故,选择LAB色彩模型,可以保留尽量宽阔的色域和颜色。【
1)不像RGB和CMYK色彩空间,Lab 颜色被设计来接近人类生理视觉。它致力于感知均匀性,它的 L 分量密切匹配人类亮度感知。因此可以被用来通过修改 a 和 b 分量的输出色阶来做精确的颜色平衡,或使用 L 分量来调整亮度对比。这些变换在 RGB 或 CMYK 中是困难或不可能的。
2)因为 Lab 描述的是颜色的显示方式,而不是设备(如显示器、打印机或数码相机)生成颜色所需的特定色料的数量,所以 Lab 被视为与设备无关的颜色模型。
3)色域宽阔。它不仅包含了RGB,CMYK的所有色域,还能表现它们不能表现的色彩。人的肉眼能感知的色彩,都能通过Lab模型表现出来。
另外,Lab色彩模型的绝妙之处还在于它弥补了RGB色彩模型色彩分布不均的不足,因为RGB模型在蓝色到绿色之间的过渡色彩过多,而在绿色到红色之间又缺少黄色和其他色彩。如果我们想在数字图形的处理中保留尽量宽阔的色域和丰富的色彩,最好选择Lab。
】
LAB色彩模型有L、A和B三个通道,L通道主要是亮度通道,L的值域由0(黑色)到100(白色)。A和B通道主要是负责色彩变换,a表示从洋红色至绿色的范围(a为负值指示绿色而正值指示品红),b表示从黄色至蓝色的范围(b为负值指示蓝色而正值指示黄色)。Lab颜色空间的优点:1)不像RGB和CMYK色彩空间,Lab 颜色被设计来接近人类生理视觉。它致力于感知均匀性,它的 L 分量密切匹配人类亮度感知。因此可以被用来通过修改 a 和 b 分量的输出色阶来做精确的颜色平衡,或使用 L 分量来调整亮度对比。这些变换在 RGB 或 CMYK 中是困难或不可能的。2)因为 Lab 描述的是颜色的显示方式,而不是设备(如显示器、打印机或数码相机)生成颜色所需的特定色料的数量,所以 Lab 被视为与设备无关的颜色模型。3)色域宽阔。它不仅包含了RGB,CMYK的所有色域,还能表现它们不能表现的色彩。人的肉眼能感知的色彩,都能通过Lab模型表现出来。另外,Lab色彩模型的绝妙之处还在于它弥补了RGB色彩模型色彩分布不均的不足,因为RGB模型在蓝色到绿色之间的过渡色彩过多,而在绿色到红色之间又缺少黄色和其他色彩。如果我们想在数字图形的处理中保留尽量宽阔的色域和丰富的色彩,最好选择Lab。
距离的度量:
如果直接将l,a,b,x,y拼接成一个矢量计算距离,当超像素的大小变化时,x,y的值可以取到非常大 ,比如如果一张图10001000,空间距离可以达到1000Sqr(2),而颜色距离最大仅10*Sqr(2),导致最终计算得到的距离值中,空间距离ds权重占比过大。
所以需要进行归一化,除以最大值即超像素点的初始宽度S,将值映射到[0,1]。
而颜色空间距离也会给到一个固定的值m来调节颜色距离与空间距离的影响权重,m取值范围为[1,40]。
最终距离公式为D。

m还允许我们权衡颜色相似性和空间邻近度之间的相对重要性。
当m大时,(空间距离的权重越大)空间邻近性更重要,得到的超像素更紧凑(规则)
当m小时,(颜色距离权重更大)超像素更紧密的附着到图像边界,但具有较小的规则尺寸和形状(不规则)
可改进的点
1.撒种子步骤,原来是根据图像大小和超像素数目均匀撒的。
💛改:在初始种子点的n*n(一般n取3)个邻域内寻找更优的像素进行撒种子——计算邻域内所有像素的梯度值,把梯度值最小的像素点设置为新的超像素种子点——避免种子点落入轮廓或边界上
2.更新种子点步骤,原来是在updaye_clusters函数中根据当前超像素的所有归属像素来更新位置。
💛改:迭代引入滤波——去除超像素归属范围内与中心点在颜色空间上差异过大的像素点,用剩下的像素点更新聚类中心
3.SLIC的多次迭代中,对每一块超像素都进行迭代。
💛改:有些超像素块在迭代多次后变化不大了,所以可以设置一个准则,即本次迭代后的效果与上一次差别不大,则之后就不对此区域进行迭代。nChanges会在迭代过程中变化 ,如果nChanges小于阈值 则说明当前的超像素块 与 上一次迭代后变化不大 则直接跳出本次迭代
文章:Compact Watershed and Preemptive SLIC: On improving trade-offs of superpixel segmentation algorithms
double preemptive_thresh_iteration = 0.01; //设置的迭代阈值if(nChanges<preemptive_thresh_iteration*sz) break;