01标签
import torch
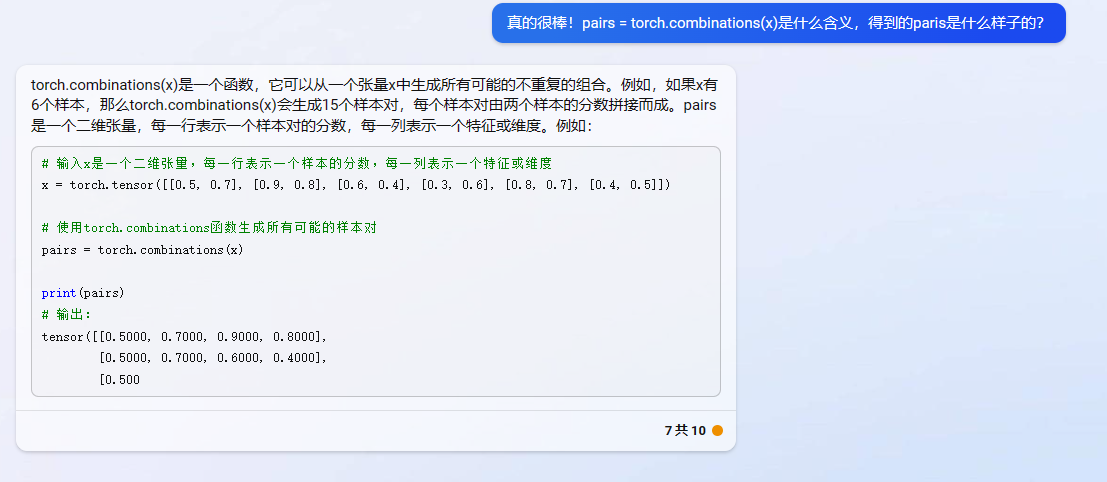
import torch.nn as nn# 输入x是一个二维张量,每一行表示一个样本的分数,每一列表示一个特征或维度
x = torch.tensor([[0.5, 0.7], [0.9, 0.8], [0.6, 0.4], [0.3, 0.6], [0.8, 0.7], [0.4, 0.5]])# 标签y是一个一维张量,表示样本之间的顺序关系(-1或1)
y = torch.tensor([1, -1, 1, -1, -1, 1])# 创建一个marginRankingLoss对象,设置边界为0.2
loss_fn = nn.MarginRankingLoss(margin=0.2)# 使用torch.combinations函数生成所有可能的样本对
pairs = torch.combinations(x)# 将pairs分成两个张量,分别表示第一个和第二个样本的分数
x1 = pairs[:, :2]
x2 = pairs[:, 2:]# 计算损失值
loss = loss_fn(x1, x2, y)print(loss) # 输出:tensor(3.)
多标签
import torch
import torch.nn as nn# 定义一个batch内数据的大小和维度
batch_size = 16
input_dim = 128# 随机生成一个batch内数据的特征向量
x = torch.randn(batch_size, input_dim)# 随机生成一个batch内数据的标签(0,1,2,3或4)
y = torch.randint(0, 5, (batch_size,))# 定义一个预测模型,比如一个线性层
model = nn.Linear(input_dim, 1)# 得到预测分数
scores = model(x)# 定义pairwise loss函数,比如MarginRankingLoss
loss_fn = nn.MarginRankingLoss(margin=1.0)# 初始化pairwise loss为0
loss = 0# 对于每个query,从batch中选择两个document,一个正例(标签大于0),一个负例(标签等于0)
for i in range(batch_size):# 找到正例和负例的索引pos_idx = (y > 0) & (y != y[i])neg_idx = (y == 0) & (y != y[i])# 如果找不到正例或负例,则跳过该queryif not pos_idx.any() or not neg_idx.any():continue# 随机选择一个正例和一个负例pos_score = scores[pos_idx].squeeze()[torch.randint(0, pos_idx.sum(), (1,))]neg_score = scores[neg_idx].squeeze()[torch.randint(0, neg_idx.sum(), (1,))]# 计算正例和负例之间的边缘损失,并累加到pairwise loss中target = torch.tensor([1.0])loss += loss_fn(pos_score, neg_score, target)# 对所有query和document对求平均,得到最终的pairwise loss
loss /= batch_sizeprint(loss)