正文共10052个字,4张图,预计阅读时间26分钟。
这次改写一下,做一个简单的分类模型和探讨一下hidden layer在聚类的应用场景下会有什么效果。为了能写的尽可能让读者理解,本文也会写一下keras来实现(就几行代码)。
01
爬取数据
网上有很多的爬虫教程,这里不具体讲了,不过强烈建议爬别人网站的时候先找找有没有现成的api(比如你想爬网易云音乐的歌词评论数据什么的o( ̄▽ ̄)d)。
我这里爬了bangumi上一些作品的评论,附上代码(crawler.py):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import re
import time
from bs4 import BeautifulSoup
req_header = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh - CN, zh;q = 0.8, en;q = 0.6',
'Connection':'keep - alive',
'Cookie':'_hc.v = "\"4e10f82f-cdb5-4fa1-ba89-262a394be3d1.1490604667\""; PHOENIX_ID = 0a01084a - 15b1299fd35 - 163c9ff; s_ViewType = 10; JSESSIONID = F255BB7A08A17AFC8F2E3701599B3193; aburl = 1; cy = 6; cye = suzhou',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
history = {} #记录链接是否已经爬取过,防止重定向
for subjectid in range(1,220000):
pageid = 1
cur_url = "http://bgm.tv/subject/" + str(subjectid)+ "/comments"
while(True):
mark = 0
cur_url = cur_url + "?page=" + str(pageid)
if cur_url in history: # 是否爬取过
break
else:
history[cur_url
] = 1
try:
r = requests.get(cur_url, headers=req_header, timeout=10)
except:
print(subjectid)
time.sleep(5)
try:
r = requests.get(cur_url, headers=req_header, timeout=10)
except:
break
#爬两次还爬不到就放弃换下一个
content = BeautifulSoup(r.content, 'lxml')
base_url_index = r.url.find("?")
cur_url = r.url[0:base_url_index]
try:
title = content.find("a",href=re.compile(r"/subject*")).text
except:
break
if title == "": #爬取到的页面有问题,比如404
break
# 因为把每个词条都作为文件名,所以有些特殊字符不能作为文件名
title = title.replace("/","-").replace(":","-").replace("\""," ").replace("<", "(").replace(">", ")").replace("?","-").replace("*","-").replace("\\","-").replace("|","-").replace("\n","-")
# 把爬取到的条目下的评论都拿出来放到条目文件里
with open("directory/"+title, "a", encoding="utf-8")as f:
for item in content.find("div", {"id": "comment_box"}).find_all("div", {"class":"item clearit"}): item = item.find("div",{"class": re.compile(r"text_main_*")})
try:
print(item.find("span")["class"])
except:
break
f.write(item.find("span")["class"][0] + '\n')
f.write(item.text.strip())
mark = 1
f.write("\n===========================\n")
pageid += 1
if mark == 0:
break
time.sleep(0.3) # 睡一会,别爬太快
爬下来的数据是这样的:

词条目录
每个词条里面是这样的:
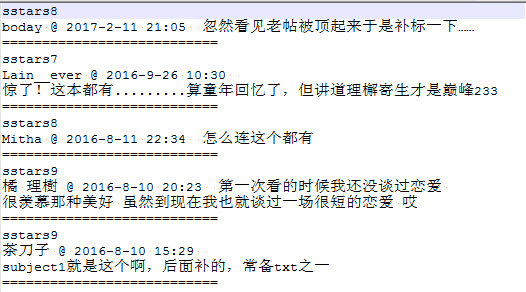
词条细节
sstarsX表示的是打分,半个星表示1分,所以如果是sstars8就是4个星。每一行用“=====”分割。我们先把数据抽取出来。
#!/usr/bin/env python # -*- coding: utf-8 -*- import osimport re out = open("bangumi_sentiment", "w", encoding="utf-8")for cur_file in os.listdir("directory"): with open("directory/"+cur_file, "r", encoding="utf-8") as f: comments = f.read().split("===========================") for comment in comments: if comment == "": continue start_index = comment.find("sstars") score = comment[start_index+6:8].strip() try: #找到日期末尾位置 content_index = re.search("\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2} ",comment).end() except: continue out.write(score+" ") out.write(" ".join(comment[content_index:].split("\n"))+"\n")
(因为又爬了日期又爬了用户名以及打分,所以还可以做一些数据分析比如看看那些人容易给差评,兴趣相投什么的,再按一定规则给词条打个平均分什么的..反正有很多东西可以做,不过又不是PM操什么心..)
抽取出来的数据如下,第一列是打分:
8 Tr1对唱和列车音好评,Tr2+1星
6 “Terminal Station”6.8★
7 Tr.1的对唱真心带感,可惜量少是硬伤
8 嗯!很棒!一二曲很好听的!
4 “Forgotten Paradise”5★
7 合唱都很赞。个别几轨有点抽风,不过不影响整体的水平
7 感觉还行吧……
6 一般吧,感觉没有3好
6 听不出原曲系列……Tr.1这个5合1略虎(可惜不好听233
6 GCHM良心大大滴坏了
9 这张很魔性
用类似的方法也可以爬爬其它网站,因为现在依然有很多网站没有做防爬虫的措施。(下篇博客写一下验证码识别哈~)
label 部分,我把情感分成low, middle, high三个部分,比如打分在[1,4]为low, (4,7]为middle, (7,10]为high。只是我自己拍脑袋这么设置的,因为我想弄成分类模型而不是回归,如果你打算直接预测得分,可以把label作为数值,后面建模的时候loss选用mean_squared_error,让预测的得分和实际得分尽可能的相近。
02
用TensorFlow建简单的文本分类模型
首先要把训练语料里的字和事先训练的word2vector里的字对应起来,再构建一个统一的embedding层。
这里我爬取了一些萌娘百科的文章加上上面bangumi的语料加起来差不多200M,因为是基于字,所以要把字按照空格分开,然后繁简大小写转换之后作为word2vector的输入,类似于这样:

word2vec输入文件
#!/usr/bin/env python# -*- coding: utf-8 -*- import logging import multiprocessing import sysfrom gensim.models import Word2Vec from gensim.models.word2vec import LineSentencedef train(inp, model_name, size=100, word_frequency_threshold=5): logging.basicConfig(format = '%(asctime)s : %(levelname)s : %(message)s', level = logging.INFO) print("Begin to train model ...") model = Word2Vec(LineSentence(inp), size = size, window = 10, hs = 1, sg = 1, # skip-gram min_count = word_frequency_threshold, workers = multiprocessing.cpu_count()/2) #CPU数量 model.save_word2vec_format(model_name, binary=False) # save a model in order to be checkedif __name__ == "__main__": if len(sys.argv) <3: print("please input input file and model file") inp = sys.argv[1] model = sys.argv[2] word_size = 100 word_threshold = 3 if len(sys.argv) > 3: word_size = int(sys.argv[3]) #词向量维度 word_threshold = int(sys.argv[4]) #每个字最少出现的次数 train(inp, model, word_size, word_threshold)
运行python inp out.model 200 3训练一段时间后就可以得到一个名为out.model的模型,为了方便查看所以binary设置成False,输出的模型文件如下:
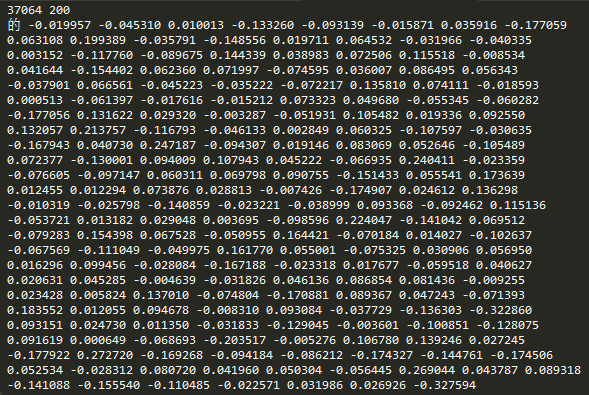
word2vec 模型
第一行是模型的维度,这里表示的含义是公有37064个字,每个字的词向量为200。每一行的第一个列是字。
这里提一下,我们有的时候训练了两个词向量的模型,那怎么把一个词的词向量映射到另一个词向量的空间呢?你可以利用两个词向量模型都有的词来学习权重w(有点像auto encoder),从而可以把一个模型中的词向量映射到另一个空间。
(另外,词向量的模型可以加载一个模型后,继续加入句子来训练。不过不可以加入新词)
我们这里比较简单的,如果不出现在我们训练好的词(字)向量中的字,直接用<unk>(unknow)来代替。
如果要使用我们训练好的词向量来代替embedding层(你也可以不用,效果可能会稍微差点),你要确保的是你的输入(句子)中的每个字的id正好是词向量矩阵的第id个。比如有一个句子:
除 了 剧 情 外 啥 都 好 的 片 子
每个字在词向量矩阵中的行号分别是:
[1 2 3 4 5 6 7 8 0 10 11]
那你的模型这句话的输入就是[1 2 3 4 5 6 7 8 0 10 11]。
请一定要确保这一点,而且如果你用keras,你的padding的值就是embedding中对应的行号,比如如果你的padding是-1,对应的就是embedding[-1] 也就是embedding的最后一个字。
这部分其实跟上次的序列标注差不多,区别就是上次是多输出,这次是一个输出判断属于哪个类。核心代码如下:
# 设置placeholderword_ids = tf.placeholder(tf.int32, shape=[None, None],name="word_ids") # batch size, max length of sentence in batchsequence_lengths = tf.placeholder(tf.int32, shape=[None], name="sequence_length") # shape = batch sizelabels = tf.placeholder(tf.int32, shape=[None], name="labels") # only one dimensiondropout = tf.placeholder(dtype=tf.float32, shape=[], name="dropout") lr = tf.placeholder(dtype=tf.float32, shape=[], name="lr")
# 设置embedding层with tf.variable_scope("words"): _word_embeddings = tf.Variable(embeddings, name="_word_embeddings", dtype=tf.float32, trainable=trainable) word_embeddings = tf.nn.embedding_lookup(_word_embeddings, word_ids, name="word_embeddings") word_embeddings = tf.nn.dropout(word_embeddings, dropout)# 设置模型with tf.variable_scope("bi-lstm"): lstm_cell = tf.contrib.rnn.LSTMCell(hidden_size) _, (output_state_fw, output_state_bw) = tf.nn.bidirectional_dynamic_rnn(lstm_cell, lstm_cell, word_embeddings, sequence_length=sequence_lengths, dtype=tf.float32) output = tf.concat((output_state_fw[-1], output_state_bw[-1]), axis=-1) output = tf.nn.dropout(output, dropout) # 输出部分在双向lstm的最后一层合并后加一个全连接层,全连接层后接一个softmax层with tf.variable_scope("proj"): W = tf.get_variable("W", shape=[2 * hidden_size, nlabels], dtype=tf.float32) b = tf.get_variable("b", shape=[nlabels], dtype=tf.float32, initializer=tf.zeros_initializer()) output = tf.reshape(output, [-1, 2 * hidden_size]) pred = tf.matmul(output, W) + b logits = pred labels_pred = tf.cast(tf.argmax(logits, axis=-1), tf.int32) losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels) loss = tf.reduce_mean(losses) # batch的平均losswith tf.variable_scope("train_step"): optimizer = tf.train.AdamOptimizer(lr) train_op = optimizer.minimize(loss)
03
用Keras建简单的文本分类模型
keras这部分的代码比较简洁,需要注意的是如果要用variable_length的句子(不同长度句子),需要多设置一个参数mask_zero=True,这个参数在embedding层设置后,所有word_id=0的字都会在后面的lstm层会忽略掉,所以我们在设置embedding的时候要在第一行插入一个全0的row,相应的word_id也都要加1,这点要注意注意。
这里我给了两个可以做这个模型的模型,区别只是在输出的时候是要预测一个分类还是一个数值。如果是分类就把label处理成categorical的,如果是预测打分值就直接用数值就行(比如半颗星是1分,5星是10分)。
# 分类模型def create_model_classify(max_features, nlabels, embeddings=None, embedding_dim=200, hidden_dim=300): model = Sequential() if embeddings is not None: model.add(Embedding(input_dim=max_features,output_dim=embedding_dim, dropout=0.2, weights=[embeddings], mask_zero=True)) else: model.add(Embedding(max_features, embedding_dim=embedding_dim, dropout=0.2)) model.add(Bidirectional(LSTM(hidden_dim, dropout_W=0.2, dropout_U=0.2, return_sequences=False))) # try using a GRU instead, for fun model.add(Dense(nlabels)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy',]) # availabel metrics https://keras.io/metrics/ return model# 回归模型def create_model_regress(max_features, embeddings=None, embedding_dim=200, hidden_dim=300): model = Sequential() if embeddings is not None: model.add(Embedding(input_dim=max_features,output_dim=embedding_dim, dropout=0.2, weights=[embeddings], mask_zero=True)) else: model.add(Embedding(max_features, embedding_dim=embedding_dim, dropout=0.2)) model.add( Bidirectional(LSTM(hidden_dim, dropout_W=0.2, dropout_U=0.2), merge_mode='concat')) model.compile(loss='mean_squared_error', optimizer='sgd', metrics=['mae','acc' ]) # availabel metrics https://keras.io/metrics/idden_dim= return model
04
情感模型的隐藏层聚类
利用上面训练出来的模型,抽取每一条训练数据的隐藏层,然后对其进行聚类。(saraba1st数据集,训练集准确率90%)
#keras实现from keras.models import Model org_model = load_model("result/model.weights/acc_XXX.model") layer_name = 'bidirectional_1'intermediate_layer_model = Model(input=org_model.input, # keras 2.0 inputs outputs output=org_model.get_layer(layer_name).output) intermediate_output = intermediate_layer_model.predict(np.asarray(word_ids))
我们先对原始数据用PCA降维到2维方便显示在平面上,不同的颜色表示的是其原始的label。
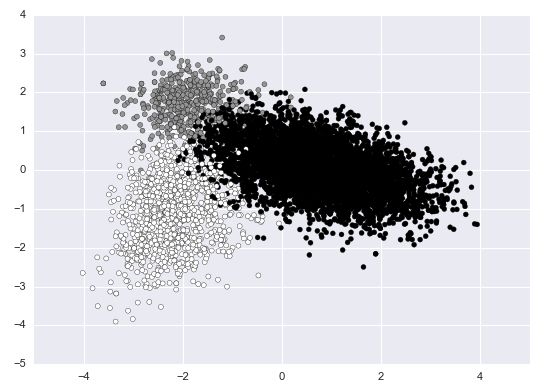
原始结果
从图中可以看到原始的数据分布就是很不均匀的,黑色部分的数据量非常大。
那么来看一下其隐藏层的实际聚类情况:
Kmeans k=3:
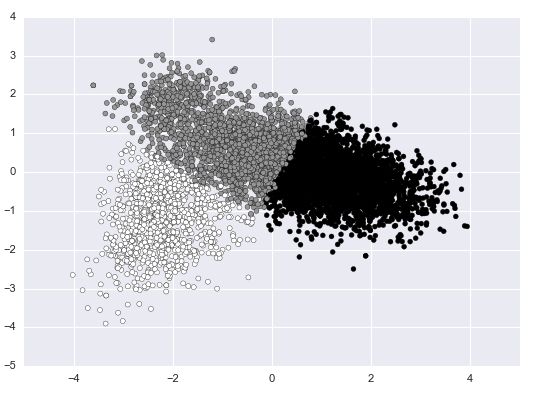
Kmeans k=3
我们可以发现原本很大的一部分黑色被纳入了灰色,很有可能就是这部分的数据很难判断是归于哪个类。检查之后发现是level_middle和level_high之间存在了混淆(看起来也是可以理解的)。比如有些句子是这样的:
level_high 因 为 天 元 , 所 以 期 望 越 大 失 望 越 大 吧 . . . 看 完 后 还 有 印 象 的 就 第 1 第 3 第 7 集 了 . . . 后 半 部 分 慢 慢 变 得 很 乏 力 , 能 记 住 的 只 有 几 个 小 点 . . . 神 展 开 也 让 人 感 觉 不 到 太 大 的 惊 喜 。
level_high 前 第 三 话 真 是 惊 艳 , 往 后 越 来 越 烂 。
这两句句子就算是人眼去看的话也真的很难区分到底应不应该标level_high。
来看一下Kmeans k=4:
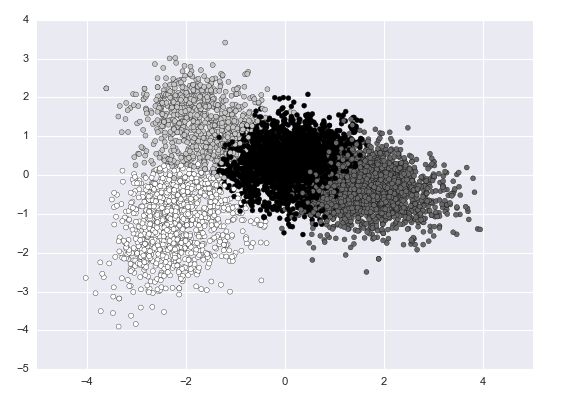
Kmeans k=4
可以看到在middle和high之间确实还夹杂了一层难以判断是好还是中立的语句。
可以庆幸的是负类都很明显的区分开来了。
05
分成正负两类的结果
把三个分类的结果转换成二分类之后,验证集上的acc从0.8提升到了0.85。
训练集上hidden layer的结果如下:
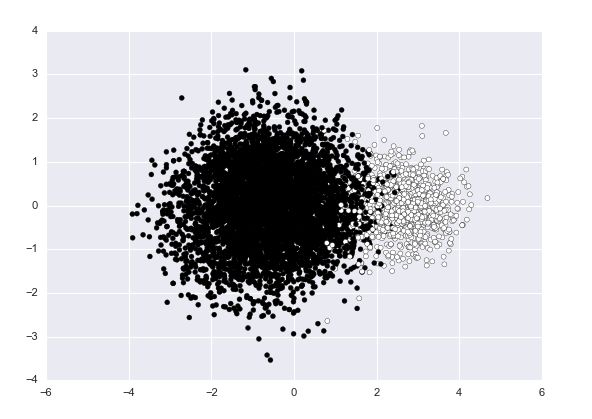
原始训练集PCA降维后的分布
Kmeans聚类之后的结果
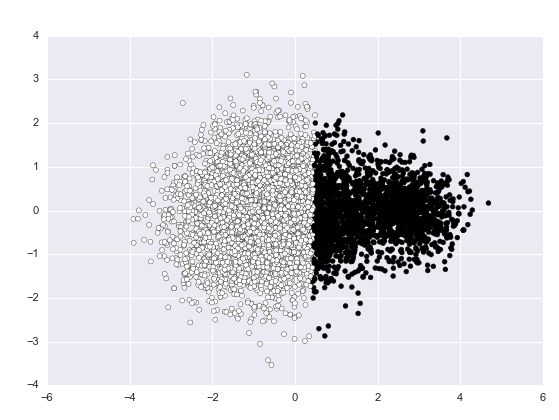
k=2
可以看到中间还是有一部分被遮盖了。
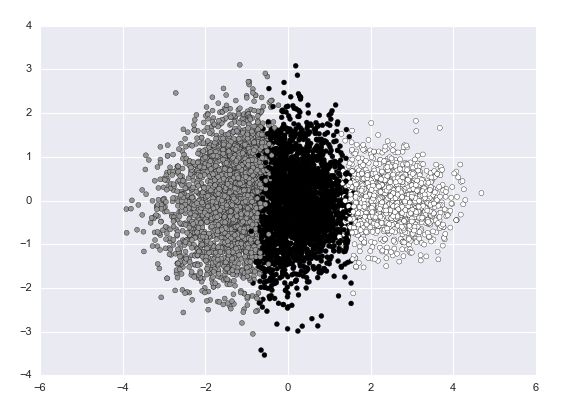
k=3
由于从原始的PCA降维后的结果其实是很容易看到两个"簇"的,所以考虑换一个聚类方法。
Agglomerative聚类:
linkage = complete
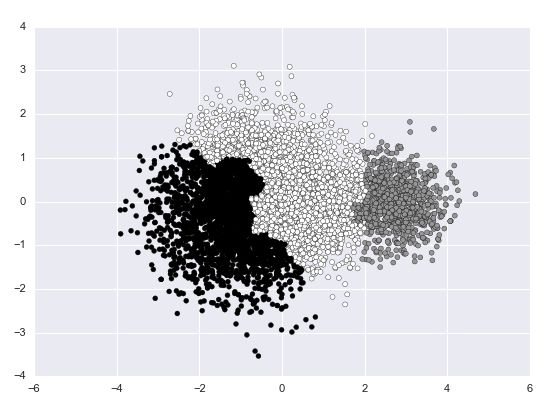
agglomerative k=3 linkage=complete
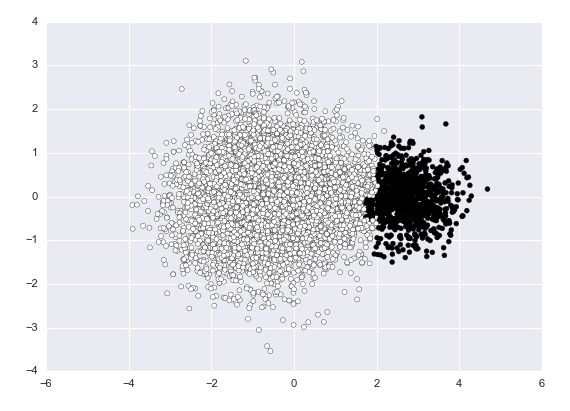
k=2 linkage=complete
看起来好多了。。。
同样的出现上面的问题,很大程度是因为我们用了现成的"标注"(用户的评分),但是这种标注有的时候是非常不准确的。比如:

训练集标注样例
(明明打了5星,硬是在评价上做出了看起来不那么positive的结果,sigh~)
所以在实际应用训练集的时候往往是需要多个"专业"人员对其共同进行打分和标注,才能尽可能的准确。(然而这样的数据非常缺乏)。
话说旅游网站的评论数据通常都十分准确。。
06
文本代码
请戳这里(https://github.com/Slyne/tf_classification_sentiment)
07
总结
本文用tensorflow和keras实现了一下文本情感分类,窥探了一下隐藏层的表述能力(还是不错的)。
原文链接:https://www.jianshu.com/p/1659ce108f55
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础