Bag of features,简称Bof,中文翻译为“词袋”,是一种用于图像或视频检索的技术。而检索就要进行比对。两幅不同的图像如何比对,比对什么,这就需要提炼出每幅图像中精练的东西出来进行比较。
一、Bag of features算法基础流程
1、收集图片,对图像进行sift特征提取。
2、从每类图像中提取视觉词汇,将所有的视觉词汇集合在一起。
3、利用K-Means算法构造单词表。
K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为单词表中的基础词汇,假定我们将K设为3,那么单词表的构造过程如下:
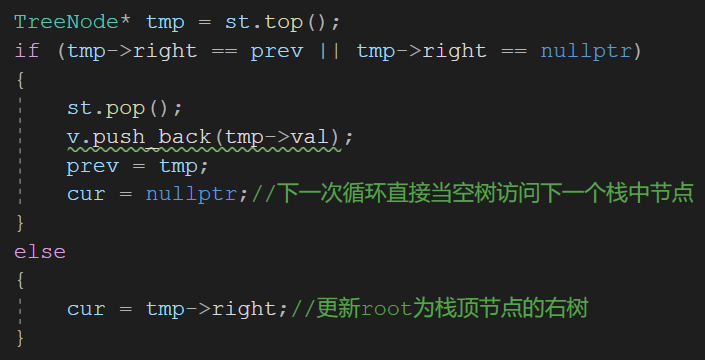
4、针对输入的特征集,根据视觉词典进行量化,把输入图像转化成视觉单词的频率直方图(统计直方图)。
5、构造特征到图像的倒排表,通过倒排表快速索引相关图像。
6、根据索引结果进行直方图匹配。
SIFT和K-means都是之前已经学习过的东西,就不再赘述了,这一章最重要的知识点就在于视觉词典的学习量化过程。
对于图像检索来说,最重要的就是要找到图像中最能表征该图像的特征,一些图像特征即使在一张图像中出现的频率很高,但同时它也会在多张图像中出现,这就导致该特征的图像分类能力很差,对图像分类起不到作用,类似于BOW方法中要剔除的文章中的高频但无效的单词:the、a、I 等。这就要用到TF-IDF的概念。
TF-IDF
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF
词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
但是, 需要注意, 一些通用的词语对于主题并没有太大的作用, 反倒是一些出现频率较少的词才能够表达文章的主题, 所以单纯使用是TF不合适的。
权重的设计必须满足:一个词预测主题的能力越强,权重越大,反之,权重越小。所有统计的文章中,一些词只是在其中很少几篇文章中出现,那么这样的词对文章的主题的作用很大,这些词的权重应该设计的较大。TF就是在完成这样的工作.TF计算公式:
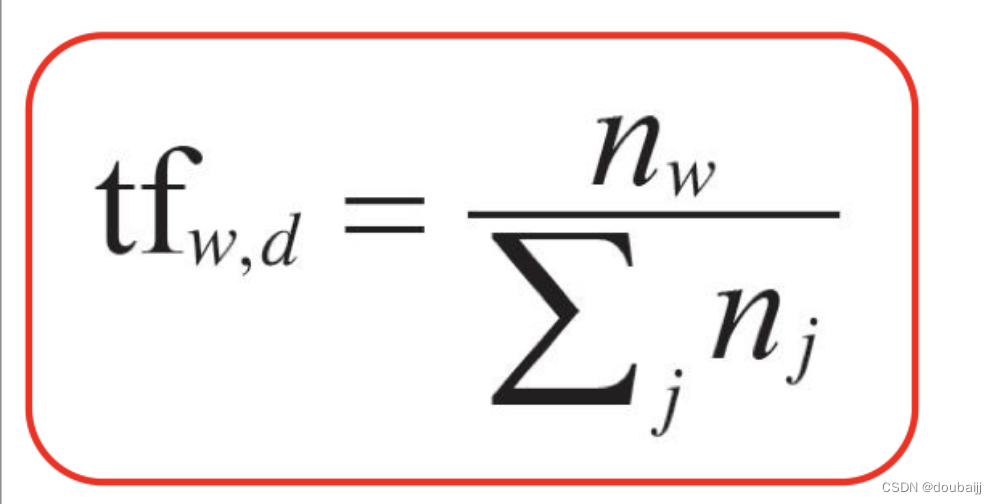
IDF
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。IDF计算公式:
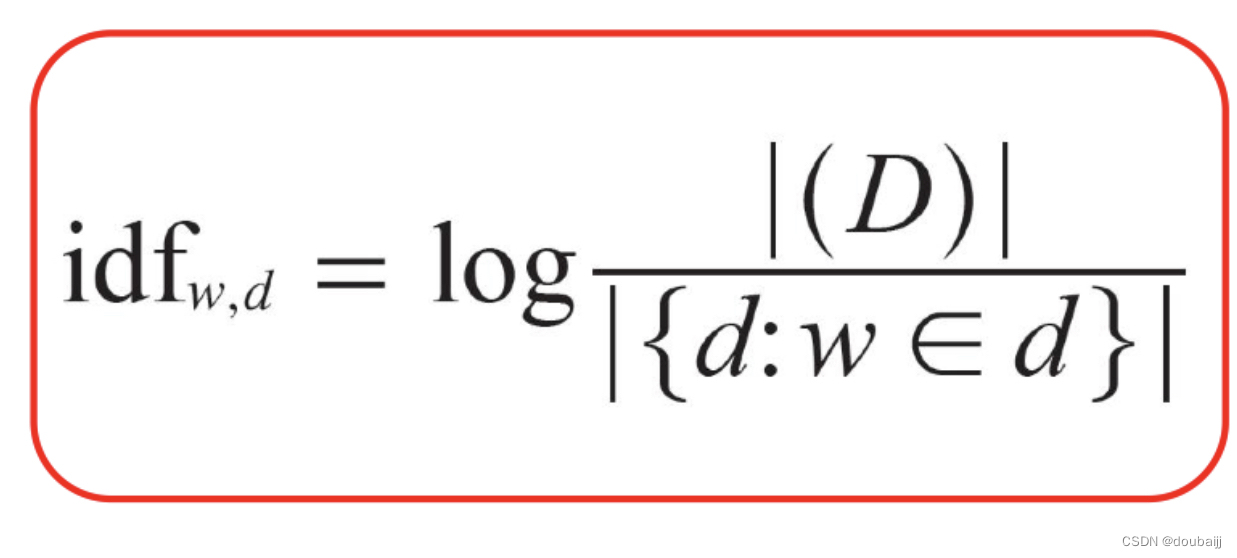
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。TF-IDF就是TF与IDF的乘积:TF−IDF=TF∗IDF
实验:
用爬虫爬数据集:
import re #为了正则表达式import requests#请求网页urlimport os #操作系统num=0 #给图片名字加数字header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36', 'Cookie':'BAIDUID=4CF8D0A4EC34C5767054C91DBBA320BF:FG=1; HOSUPPORT=1; HOSUPPORT_BFESS=1; UBI=fi_PncwhpxZ~TaJc8E~o7AylVAKZjSR4uhv; HISTORY=439af17d00ab5d33faa401de40f7f8eb74194a; HISTORY_BFESS=439af17d00ab5d33faa401de40f7f8eb74194a; UBI_BFESS=fi_PncwhpxZ~TaJc8E~o7AylVAKZjSR4uhv; BIDUPSID=4CF8D0A4EC34C5767054C91DBBA320BF; PSTM=1655628504; H_PS_PSSID=31253_26350; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; delPer=0; PSINO=7; BA_HECTOR=8h802k840g840l0k201hatq5c14; ZFY=3H1nYUpCDFUH:A25KqGctlJ279sGwBdePORsKbLyIYLk:C; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[8yR0uJE9nIf]=mk3SLVN4HKm; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=www.baidu.com; ab_sr=1.0.1_OWIzNGM5OWI5NGVkY2E5ZDg3NzQ2ZTZkYTk1MzNjYWMyMmZlMDY2ZmQ5OWUwODI2ODQzYmUxYWJiYjY4ODQyMjJmMWI1MGI5Y2Q0OWEyMWUyNmNhNjI0NDdhNTY2Yjg0N2E2NjI5Y2IwN2NiZWE3MTNkMzJjNDRlNjhkMWI4Zjk4YzEzNjUyY2Q4YzI4MjM4YmYxYjIyZmUwYWFmM2UzZg==; pplogid=2664kDh7VOrMUky4o78I99kxlKQzcDm6gbz29vdXB9MgNbC44ABDCk1rC0It9nsOypWexVqw687HBue7o3IdWPQjH5WH9cSeGdQacgLvUsv/UMk=; pplogid_BFESS=2664kDh7VOrMUky4o78I99kxlKQzcDm6gbz29vdXB9MgNbC44ABDCk1rC0It9nsOypWexVqw687HBue7o3IdWPQjH5WH9cSeGdQacgLvUsv/UMk=', 'Accept':'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9' } #请求头,谷歌浏览器里面有,具体在哪里找到详见我上一条csdn博客#图片页面的urlurl='https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1655641574257_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&dyTabStr=MCwzLDIsNiw0LDUsMSw4LDcsOQ==&ie=utf-8&sid=&word=新之助'#通过requests库请求到了页面html=requests.get(url,headers=header)#防止乱码html.encoding='utf8'#打印页面出来看看print(html.text) html=html.textpachong_picture_path='C:\Python\imgs\pc'if not os.path.exists(pachong_picture_path): os.mkdir(pachong_picture_path) res=re.findall('"objURL":"(.*?)"',html) #正则表达式,筛选出html页面中符合条件的图片源代码地址urlfor i in res: #遍历 num=num+1 #数字加1,这样图片名字就不会重复了 picture=requests.get(i) #得到每一张图片的大图 file_name='C:\Python\imgs\pc\蜡笔小新'+str(num)+".jpg" #给下载下来的图片命名。加数字,是为了名字不重复 f=open(file_name,"wb") #以二进制写入的方式打开图片 f.write(picture.content) # 往图片里写入爬下来的图片内容,content是写入内容的意思 print(i) #看看有哪些urlf.close() #结束f文件操作
从图像中提取视觉词汇,将所有的视觉词汇集合在一起,利用K-Means算法构造单词表:
import picklefrom PCV.imagesearch import vocabularyfrom PCV.tools.imtools import get_imlistfrom PCV.localdescriptors import sift#获取图像列表imlist = get_imlist('C:\Python\imgs\pc5')nbr_images = len(imlist)#获取特征列表featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]#提取文件夹下图像的sift特征for i in range(nbr_images): sift.process_image(imlist[i], featlist[i])#生成词汇voc = vocabulary.Vocabulary('ukbenchtest')voc.train(featlist, 1000, 10)#保存词汇with open('C:\Python\imgs\pc5\vocabulary1000.pkl', 'wb') as f: pickle.dump(voc, f)print ('vocabulary is:', voc.name, voc.nbr_words)
针对输入的特征集,根据视觉词典进行量化,把输入图像转化成视觉单词的频率直方图:
import picklefrom PCV.imagesearch import imagesearchfrom PCV.localdescriptors import siftimport sqlite3from PCV.tools.imtools import get_imlist# 获取图像列表imlist = get_imlist(r'C:Pythonimgspc5')nbr_images = len(imlist)# 获取特征列表featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]# 载入词汇with open(r'C:Pythonimgspc5ocabulary1000.pkl', 'rb') as f: voc = pickle.load(f)# 创建索引indx = imagesearch.Indexer(r'C:Pythonimgspc5 estImaAdd.db', voc)indx.create_tables()# 遍历所有的图像,并将它们的特征投影到词汇上for i in range(nbr_images)[:51]: locs, descr = sift.read_features_from_file(featlist[i]) indx.add_to_index(imlist[i], descr)# 提交到数据库indx.db_commit()con = sqlite3.connect(r'C:Pythonimgspc5 estImaAdd.db')print(con.execute('select count (filename) from imlist').fetchone())print(con.execute('select * from imlist').fetchone())
构造特征到图像的倒排表,通过倒排表快速索引相关图像,根据索引结果进行直方图匹配:
import picklefrom PCV.imagesearch import imagesearchfrom PCV.geometry import homographyfrom PCV.tools.imtools import get_imlistfrom PCV.localdescriptors import siftimport warningswarnings.filterwarnings("ignore")# load image list and vocabulary# 载入图像列表imlist = get_imlist(r'C:Pythonimgspc5')nbr_images = len(imlist)# 载入特征列表featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]# 载入词汇with open(r'C:Pythonimgspc5ocabulary1000.pkl', 'rb') as f: voc = pickle.load(f, encoding='iso-8859-1')src = imagesearch.Searcher(r'C:Pythonimgspc5 estImaAdd.db', voc) # Searcher类读入图像的单词直方图执行查询# index of query image and number of results to return# 查询图像索引和查询返回的图像数q_ind = 0nbr_results = 51# regular query# 常规查询(按欧式距离对结果排序)res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]] # 查询的结果print('top matches (regular):', res_reg)# load image features for query image# 载入查询图像特征进行匹配q_locs, q_descr = sift.read_features_from_file(featlist[q_ind])fp = homography.make_homog(q_locs[:, :2].T)# RANSAC model for homography fitting# 用单应性进行拟合建立RANSAC模型model = homography.RansacModel()rank = {}# load image features for result# 载入候选图像的特征for ndx in res_reg[1:]: #在报错行出添加try except语句 try: locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1 except: continue # get matches matches = sift.match(q_descr, descr) ind = matches.nonzero()[0] ind2 = matches[ind] tp = homography.make_homog(locs[:, :2].T) # compute homography, count inliers. if not enough matches return empty list # 计算单应性矩阵 try: H, inliers = homography.H_from_ransac(fp[:, ind], tp[:, ind2], model, match_theshold=4) except: inliers = [] # store inlier count rank[ndx] = len(inliers)# sort dictionary to get the most inliers first# 对字典进行排序,可以得到重排之后的查询结果sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)res_geom = [res_reg[0]] + [s[0] for s in sorted_rank]print('top matches (homography):', res_geom)# 显示查询结果imagesearch.plot_results(src, res_reg[:8]) # 常规查询imagesearch.plot_results(src, res_geom[:8]) # 重排后的结果检索图片为第一张:
聚类类别为1000:
常规查询:

重排后:
聚类类别为500:

常规查询:

重排后:

聚类类别为100:

常规排序:

重排后:

检索图片为第39张:
聚类类别为1000:

常规查询:

重排后:

聚类类别为500:

常规查询:

重排后:

聚类类别为100:

常规排序:

重排后:

检索图片为第48张:
聚类类别为1000:

常规排序:
重排后:

聚类类别为500:
常规排序:

重排后:
聚类类别为100:

常规排序:

重排后:

从上面的运行结果可以发现,随着聚类类别数量的增加,图像检索的结果越来越好,更加接近合理性。但是当类别数量K增加到某一个值得时候,图像检索的效果又开始下降,会有过拟合的现象。因此聚类类别数量能够很大程度的影响图像检索的效果。