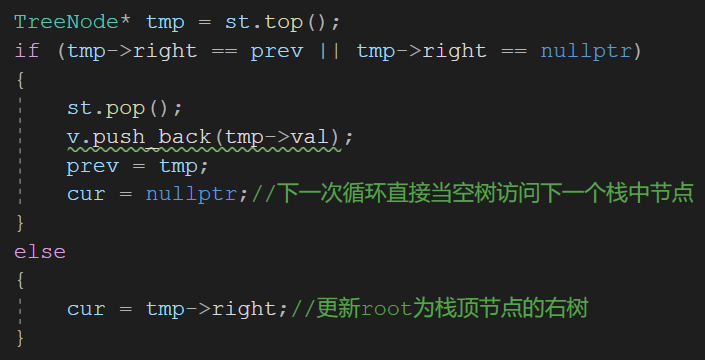
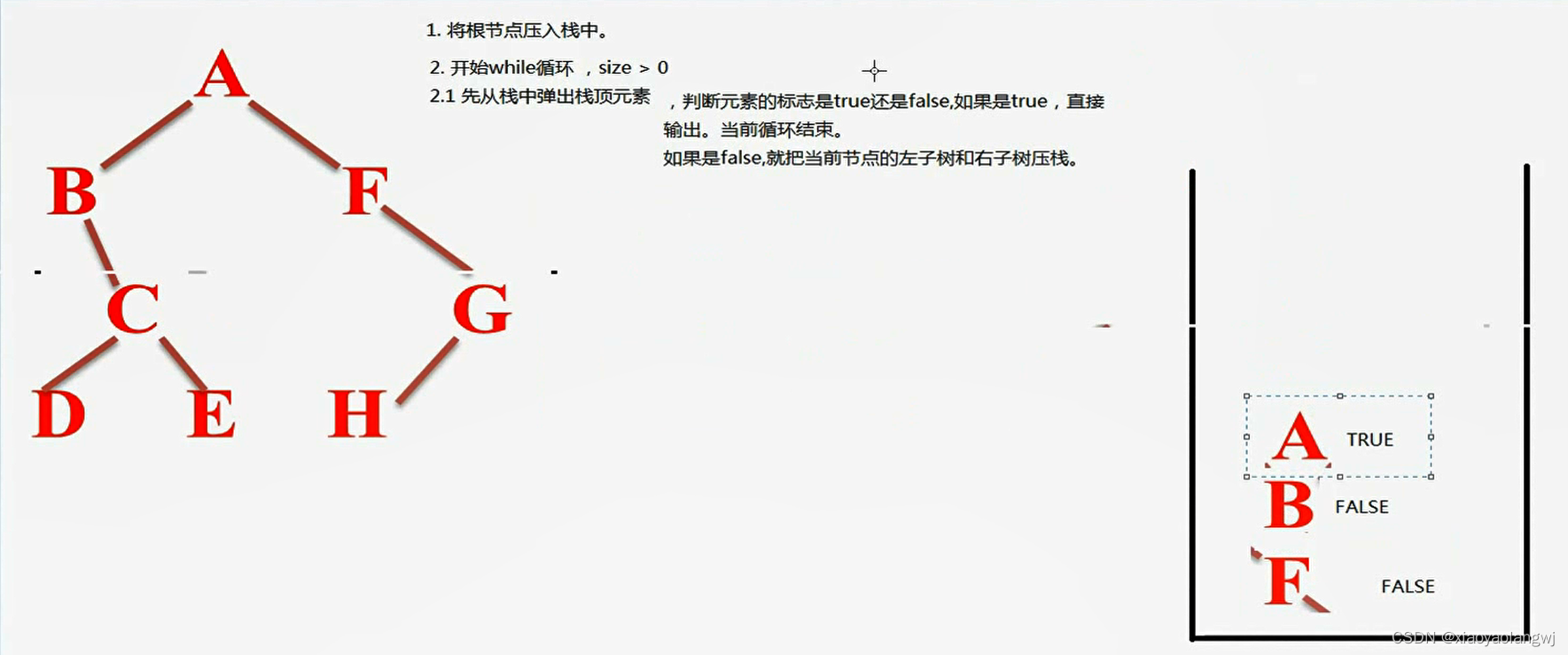
1 爬虫
1.1 爬虫原理
这部分内容可以跳过,掌握与否对后面内容的阅读影响并不大,但有兴趣的话可以看看呐~
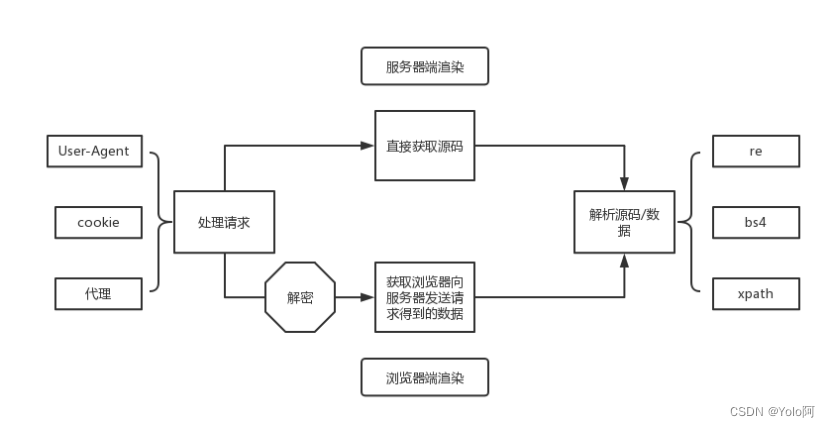
实现一个爬虫,一般需要经过两个步骤:处理请求和解析源码/数据。
处理请求方面,我们可以使用Python程序自动发送请求,然后根据返回的网页脚本,判断该页面是服务器端渲染还是浏览器端渲染。服务器端渲染可以直接获取到源码并进行解析,如果是浏览器端渲染则需要获取浏览器向服务器发送的二次请求得到的数据。其中,服务器端渲染的网页需要我们解析源码,而浏览器端渲染的网页一般可以直接获得数据。
-
服务器端渲染:右键 - 查看页面源代码,如果在源码中能看到页面中字条的内容,则认为该字条是
服务端渲染的。

-
浏览器端渲染:右键 - 检查,分别点击网络、Fetch/XHR,当搜索框获得焦点的时候,我们可以看到浏览器会向服务器发送一个请求,然后将服务器返回的数据渲染后到页面上,这种方式就是浏览器端渲染,也被称为
AJAX技术。
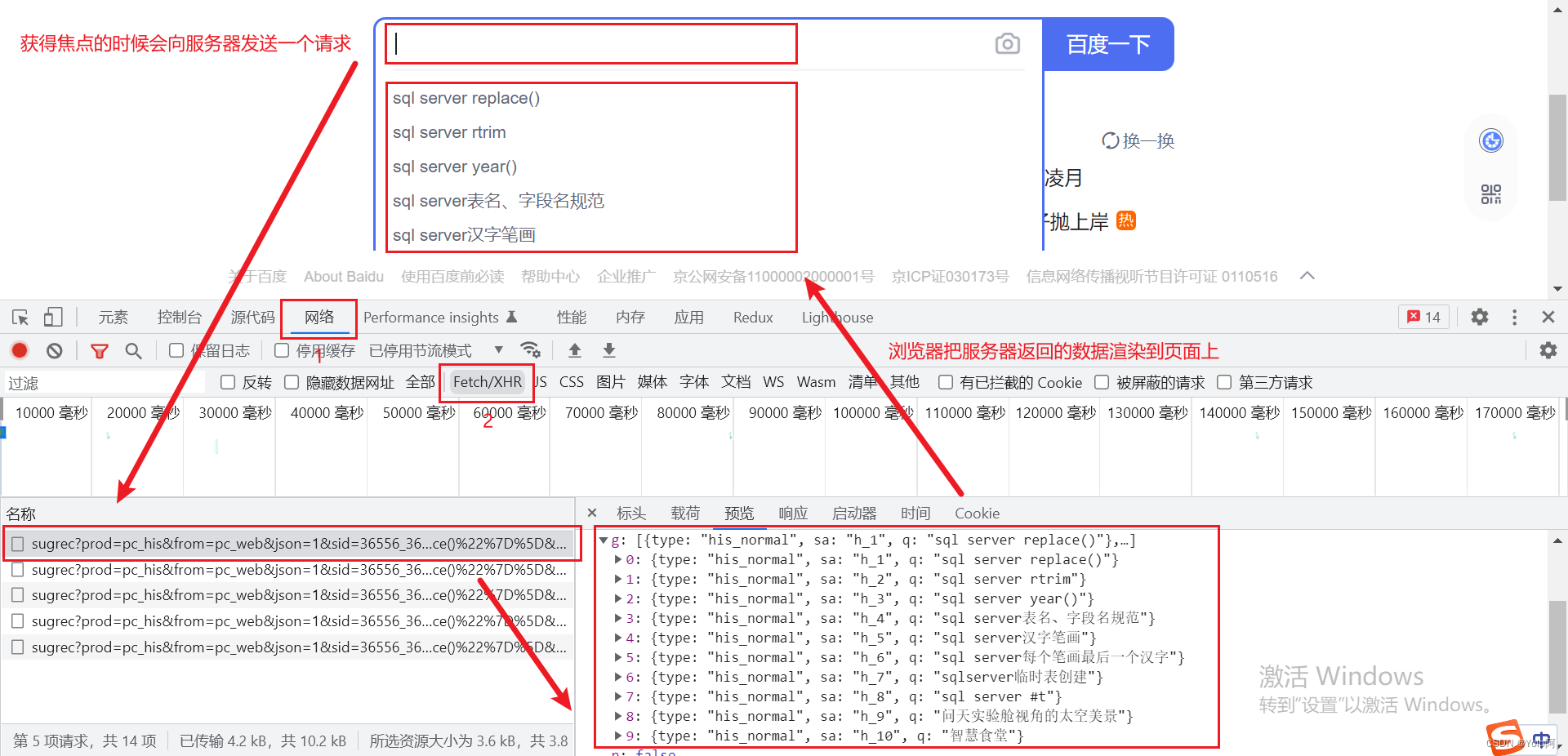
对于浏览器端渲染的页面,我们直接获取二次请求得到的数据即可,而对于服务器端渲染的页面,我们需要从源码解析出有价值的内容。我们可以使用Python的第三方模块re、bs4、xpath等。re是使用正则表达式匹配网页源码,从而得到我们想要的内容;而bs4是通过标签和属性定位网页源码中我们需要的内容的位置,其更符合前端的编程习惯;xpath同样是通过标签和属性定位,但它看起来更加直观。
- re
import relist = re.findall(r"\d+", "我的电话号码是:10086, 我女朋友的电话号码是:10010") # ['10086', '10010']
- bs4
from bs4 import BeautifulSouppage = BeautifulSoup(res, "html.parser") # 把页面源代码(res)交给BeautifulSoup进行处理, 生成BeautifulSoup对象
table = page.find("table", attrs={"class": "hq_table"}) # 找到table
- xpath
# xpath是在XML文档中搜索内容的一门语言,html是xml的一个子集
from lxml import etreexml =
"""
<book><id>1</id><name>野花遍地香</name><price>1.23</price><author><nick>周大强</nick><nick>周芷若</nick></author>
</book>
"""
tree = etree.XML(xml)
result = tree.xpath("/book/name/text()") # ['野花遍地香']。/表示层级关系,第一个/是根节点,text() 拿文本
另外,在处理请求的过程中,可能需要解决一系列的反爬措施:(1)防止网站识别Python程序需要加上User-Agent请求头;(2)对于使用cookie验证登录的网站需要带上登录后服务器返回的cookie作为请求头;(3)防止因频繁的请求导致ip地址被封需要使用代理;(4)以及针对浏览器端渲染的情况,直接请求数据时可能遇到的一系列加密手段,这时候获取数据需要模拟加密过程进行解密……
个人理解的爬虫原理~
1.2 实现一个爬虫
一般来说,平台知名度越大,其反爬措施就越多,这时候获取数据也会变得更加困难,而下文将会介绍一种技巧性的方法。
1.2.1 Selenium
Selenium是一个用于Web应用程序测试的工具,它可以直接运行在浏览器中,模拟用户的操作,例如点击、输入、关闭、拖动滑块等,就像真正的用户在操作一样。通过Selenium我们可以直接定位到页面中某段文字的位置,在已经经过浏览器渲染的网页中获取需要的内容,而不需要关心网页是服务器端渲染还是浏览器端渲染,所见即所得。
1.2.2 超级鹰
另一方面,某些数据可能需要登录网站后才能获取,而在登录选项中选择账号密码登录一般会被要求输入验证码,比如常见的数字、汉字验证码等,某东平台使用的是滑块。我们可以使用超级鹰处理滑块,它是一款成熟的验证码处理工具,其使用原理是通过截取浏览器中验证码的图片传到超级鹰工具接口,然后接口会返回识别出来的数据(数字,汉字,坐标等),我们通过Selenium可以直接操作浏览器从而通过验证。
1.2.3 实现一个爬虫(源码在这里~)
- 在这之前,大家可以先注册一个超级鹰账号哈,1元=1000题分,识别一次只需不到50题分,还是相当良心的。
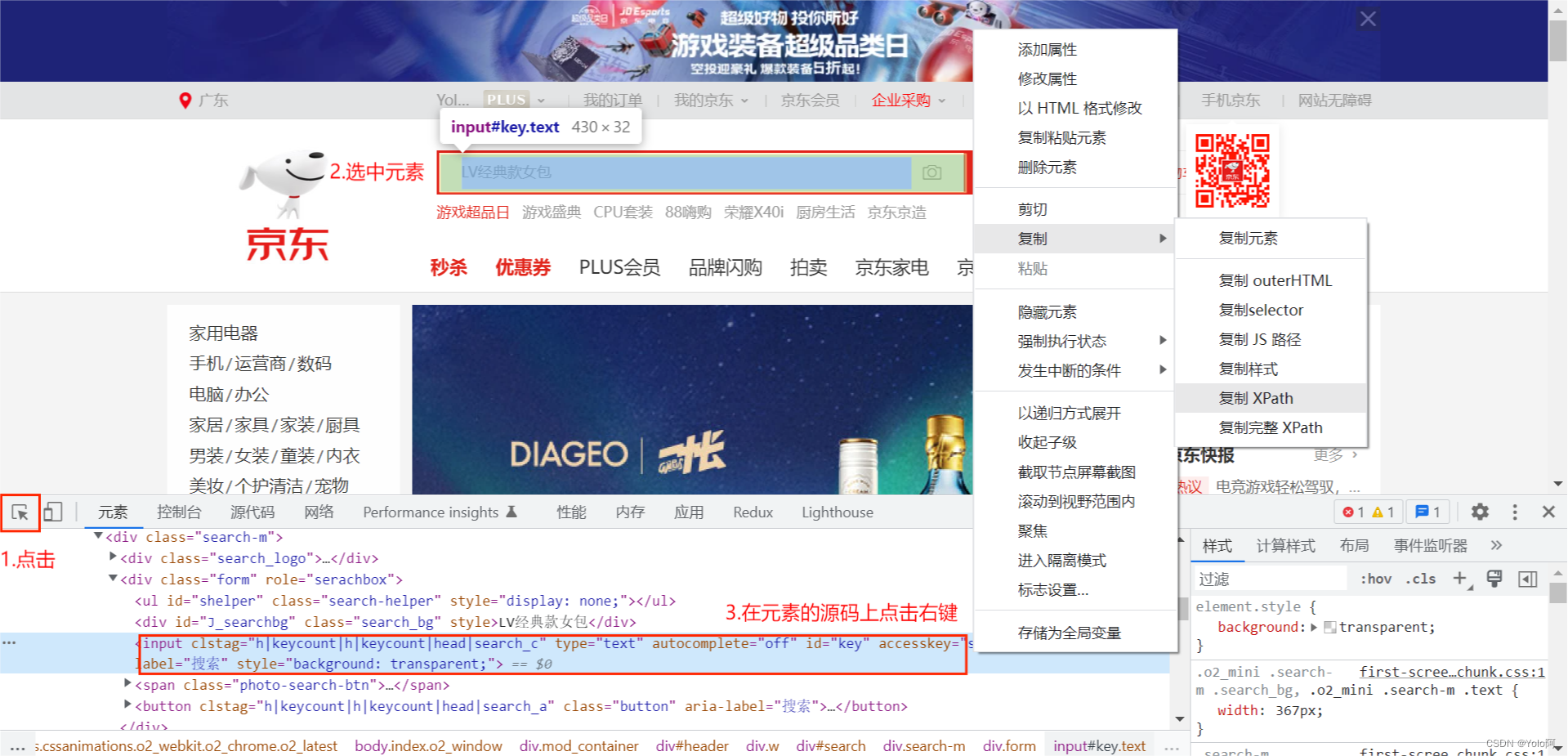
- 其次,在
1.1 爬虫原理部分有简单介绍过xpath,这里有一种更便捷的方法获取元素的xpath,就像这样:右键-检查
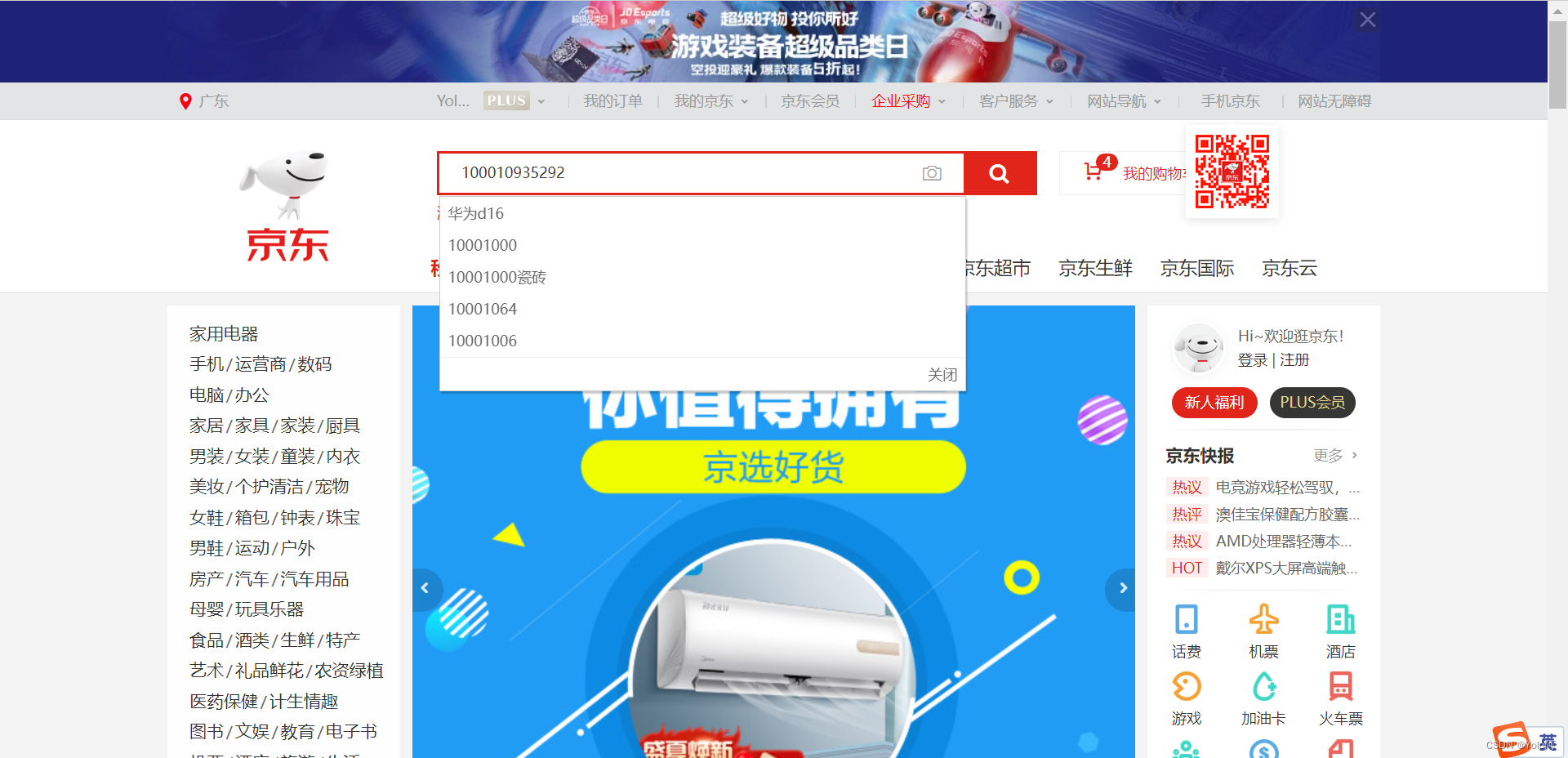
- 另外,部分商品可以使用
id搜索
- 再有就是,
Selenium是需要配合浏览器驱动使用的,Chrome的驱动:chromedriver,对应浏览器版本的驱动下载完成后,将驱动放置在Python的安装目录,像下面这样:(也许还需要配置环境变量??如果遇到报错说没有找到浏览器驱动的话,可以自行搜一下具体是怎么配置的哈)

chaojiying.py(验证码处理)
#!/usr/bin/env python
# coding:utf-8import requests
from hashlib import md5class Chaojiying_Client(object):def __init__(self, username, password, soft_id):self.username = usernamepassword = password.encode('utf8')self.password = md5(password).hexdigest()self.soft_id = soft_idself.base_params = {'user': self.username,'pass2': self.password,'softid': self.soft_id,}self.headers = {'Connection': 'Keep-Alive','User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',}def PostPic(self, im, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,}params.update(self.base_params)files = {'userfile': ('ccc.jpg', im)}r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)return r.json()def ReportError(self, im_id):"""im_id:报错题目的图片ID"""params = {'id': im_id,}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)return r.json()# if __name__ == '__main__':# 用户中心>>软件ID# chaojiying = Chaojiying_Client('超级鹰账号', '密码', '软件ID')# 本地图片文件路径替换code.png,有时WIN系统须要//# im = open('code.png', 'rb').read() # im就是图片的所有字节# 官方网站>>价格体系# print(chaojiying.PostPic(im, 9101)) # 9101验证码类型jd.py - 爬虫主程序
目标链接:(第24行代码)

from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from chaojiying import Chaojiying_Client
import time# 初始化超级鹰
chaojiying = Chaojiying_Client('******', '********', '******') # 替换自己的账号、密码和软件ID# 无头浏览器
# opt = Options()
# opt.add_argument("--headless")
# opt.add_argument("--disbale-gpu")
# options = opt# 设置不关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)web = webdriver.Chrome(options = option)# 打开登录页面
web.get("") # 填入某东登录页面链接,由于不能出现具体的目标链接,故以截图显示
# 最大化窗口,防止误触
web.maximize_window()# time.sleep()是为了等待资源加载完
time.sleep(3)
# 使用账号登录
web.find_element(By.XPATH, '//*[@id="content"]/div[2]/div[1]/div/div[3]/a').click()time.sleep(3)
# 输入用户名和密码
web.find_element(By.XPATH, '//*[@id="loginname"]').send_keys("***********") # 某东账号
web.find_element(By.XPATH, '//*[@id="nloginpwd"]').send_keys("********") # 某东密码
# 点击登录
web.find_element(By.XPATH, '//*[@id="loginsubmit"]').click()time.sleep(3)
# 处理验证码,识别图像
verify_img = web.find_element(By.XPATH, '//*[@id="JDJRV-wrap-loginsubmit"]/div/div/div/div[1]/div[2]/div[1]/img')
dic = chaojiying.PostPic(verify_img.screenshot_as_png, 9101)
result = dic['pic_str'] # x1,y1
p_temp = result.split(",")
x = int(p_temp[0])# 滑动滑块
btn = web.find_element(By.XPATH, '//*[@id="JDJRV-wrap-loginsubmit"]/div/div/div/div[2]/div[3]')
ActionChains(web).drag_and_drop_by_offset(btn, x, 0).perform()time.sleep(8)
# 登陆成功,搜索界面(使用id搜索)
web.find_element(By.XPATH, '//*[@id="key"]').send_keys("100010935292", Keys.ENTER)# time.sleep(5)
# # 点击商品
# web.find_element(By.XPATH, '//*[@id="J_goodsList"]/ul/li[1]/div/div[1]/a/img').click()# time.sleep(5)
# # 移动到新窗口
# web.switch_to.window(web.window_handles[-1])time.sleep(5)
# 商品属性
web.find_element(By.XPATH, '//*[@id="choose-attr-1"]/div[2]/div[1]/a').click()time.sleep(5)
# 点击(商品评论)
comment_el = web.find_element(By.XPATH,'//*[@id="detail"]/div[1]/ul/li[5]')
comment_el.click()time.sleep(5)
# 点击(只看当前商品评价)
only_el = web.find_element(By.XPATH, '//*[@id="comment"]/div[2]/div[2]/div[1]/ul/li[9]/label')
webdriver.ActionChains(web).move_to_element(only_el ).click(only_el ).perform()f = open("comments.txt", mode="w", encoding='utf-8')time.sleep(5)
# 评论列表
for i in range(100):# 每一页的评论div_list = web.find_elements(By.XPATH,'//*[@id="comment-0"]/div[@class="comment-item"]') for div in div_list:comment = div.find_element(By.TAG_NAME, 'p').textf.write(comment + '\n\n')# 打印页数print(i)if i < 99:# 下一页 next_el = web.find_element(By.XPATH, '//*[@id="comment-0"]/div[12]/div/div/a[@class="ui-pager-next"]')# 防止元素遮挡 webdriver.ActionChains(web).move_to_element(next_el ).click(next_el ).perform()time.sleep(3)f.close()
print('over!')- 把
chaojiying.py和jd.py放在同一个目录下,然后下载相关依赖包,运行jd.py就ok了,再放个视频趴(懒得剪了😁):
其中,Selenium执行的动作有:(1)打开登录页面并最大化窗口 - (2)使用账号登录并输入用户名和密码 - (3)处理验证码,滑动滑块(使用超级鹰滑动没通过的时候可以手动滑一次,时间足够的🌝) - (4)使用id搜索商品 - (5)点击商品属性 - (6)点击评论(加载页面的时候可以事先滑到评论位置,因为不这样做的话有时候评论数据不会显示出来⚠️)和只看当前商品评价 - (7)获取评论数据,再看下打印结果:
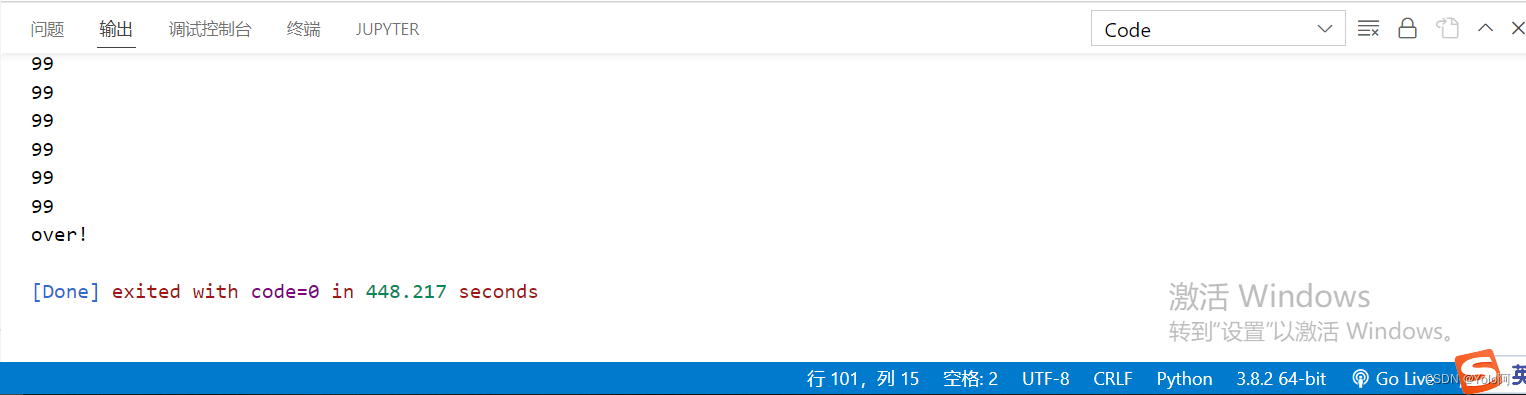
可以看到,由于Selenium需要等待浏览器将页面渲染完成,最终程序运行了7分钟多,个人认为这算得上是使用Selenium实现爬虫的最大的缺点了。另外,其优点也是显而易见的:(1)不容易遇到反爬(但好像爬某宝还是不行🐵);(2)代码稳定性高,根据指定的页面修改xpath,代码放个半年再拿出来同样可以运行;(3)通俗易懂,代码容易上手;
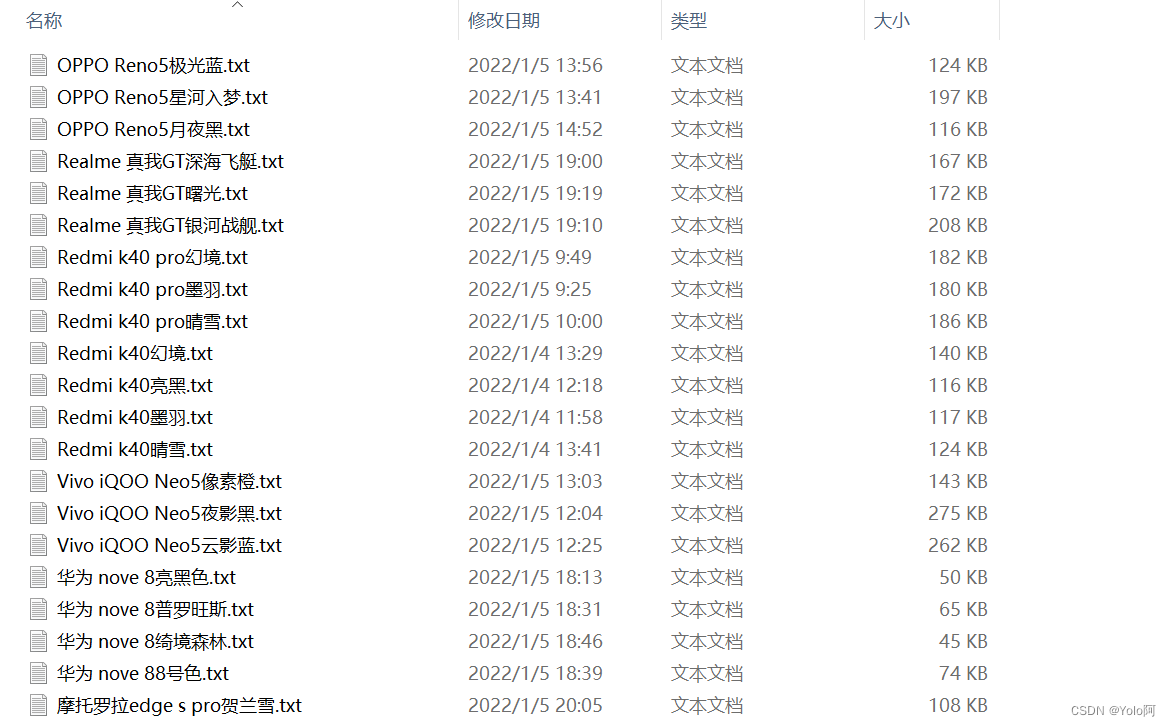
以上是搜索商品的时候输入不同的商品id的获取到的评论,内容是这样的:

- 其他需要注意的点:
- 我曾经遇到过的一种情况就是,某一页的评论结构突然不一致了,导致爬到那一页之后就报错,这时候加一个条件判断区别处理就可以了。
2 预处理
获取到文本之后,我们对文本进行预处理,包括去重和拆分短句。
2.1 去重
无论文本挖掘的最终目的是什么,去重几乎是必需的,目的可能是排除一个消费者复制另一个消费者的评论,“挺好的”、“满意”、“不错”等重复率较高的评论,或者爬取重复等情况的出现,本文使用JS实现去重。(基于Node.js环境)(后面步骤不是必须使用Python的都会用JS来完成)
先把所有评论合并为一个文件:
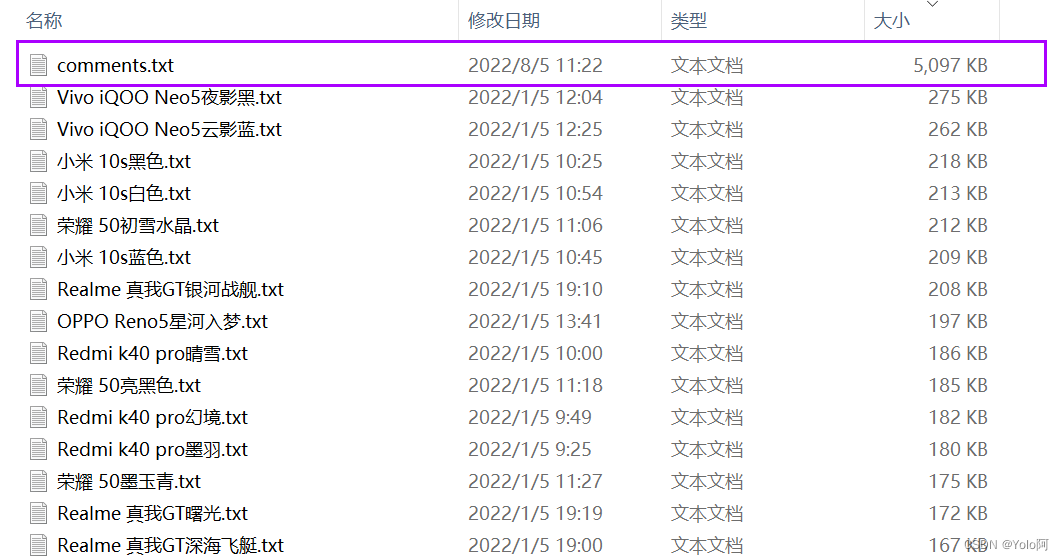
代码可以这样写(JS):
let fs = require('fs')// 读取comments目录下的所有文件
fs.readdir('../comments', (err, data) => {if (err) {throw errreturn;}let res// data是一个包含文件名的数组for (let item of data) {res = fs.readFileSync(`../comments/${item}`)fs.writeFileSync('./comments.txt', res.toString(), {flag:'a'})}
})然后对评论进行去重处理:

打印结果(合并后一共有30799条评论,去重后剩余30352条评论,重复评论447条):
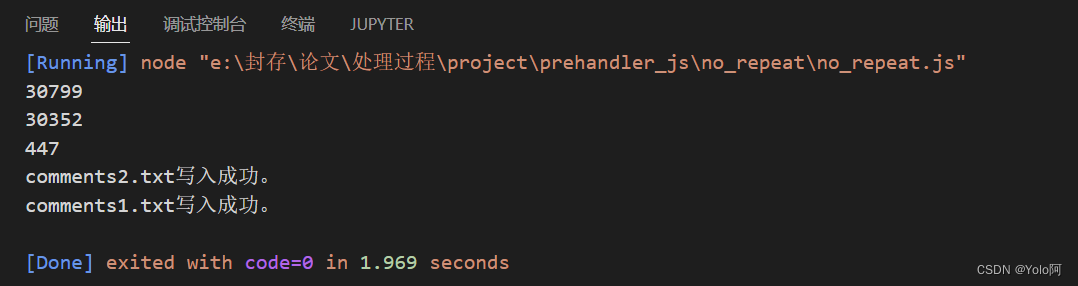
程序可以这样写(JS):👇
let fs = require('fs')// 读取评论
fs.readFile('comments.txt', function (err, data) {if (err) {console.log(err)return;}// 字符串转数组:(回车换行)let arr = data.toString().split('\r\n\r\n')// 数组去重let arr2 = [] // 保存重复的评论let arr1 = arr.filter((value, index, arr) => { // 保存去重后的评论if (arr.indexOf(value) !== index) {arr2.push(value)}return arr.indexOf(value) === index})// 写入数据// 去重后的评论fs.writeFile('./comments1.txt', arr1.join('\r\n\r\n'), function (err) {if (err) {console.log(arr)return;}console.log('comments1.txt写入成功。')})// 重复的评论fs.writeFile('./comments2.txt', arr2.join('\r\n\r\n'), function (err) {if (err) {console.log(arr)return;}console.log('comments2.txt写入成功。')})console.log(arr.length)console.log(arr1.length)console.log(arr2.length)
})- comments目录文件
- comments.txt
- comments1.txt
- comments2.txt
2.2 拆分短句
如标题所示,后面我们将会计算特征词的情感得分,而研究上一般将短句的情感得分作为特征词的情感得分,因此我们可以将去重后的每一个评论拆分为多个短句,从而提高情感分析的准确度。
先通过换行符划分短句,就像这样:

🔽

程序可以写成这样(JS):只是将两个换行符替换为一个换行符😎
let fs = require('fs')fs.readFile('./comments1.txt', (err, data) => {if (err) {console.log(err)return;}fs.writeFile('./comments - 拆分短句1.txt', data.toString().replace(/\r\n\r\n/g, '\r\n'), (err) => {if (err) {console.log(err)return;}console.log('成功。')})
})
另外,根据中文的书写习惯,一般以句号、感叹号、问号、省略号等作为一个句子结束的标志,所以我们可以依据这些标点符号继续拆分句子。Python的LTP模块实现了分句函数,在这里我们直接调用LTP模块的分句函数进行分句,以达到这样的效果:
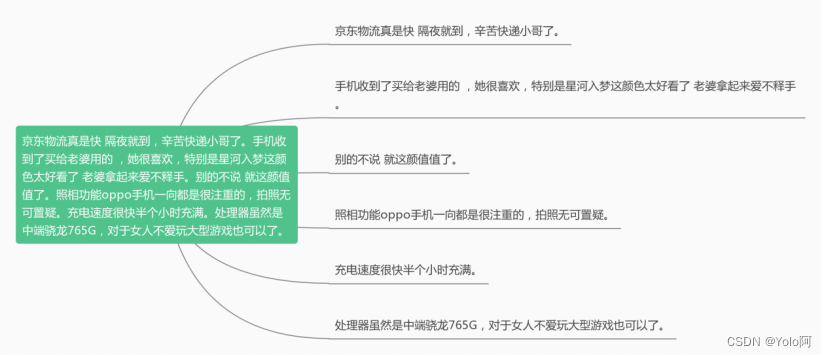
代码可以写成这样(Python):🐜
from ltp import LTPf = open("comments - 拆分短句1.txt", encoding='utf-8')
list = []
line = f.readline()while line:# 读取到数组list.append(line.replace("\n", ""))line = f.readline()f.close()ltp = LTP()
# 分句,sents是一个数组
sents = ltp.sent_split(list)# 打开一个文件
fo = open("comments - 拆分短句2.txt", "w", encoding='utf-8')for i in range(len(sents)):fo.write( f"{sents[i]}\n")fo.close()- comments - 拆分短句1.txt
- comments - 拆分短句2.txt
3 高频词统计
3.1 分词
分词即将句子切分为多个词语,它是统计高频词的关键,我们可以使用Python的jieba库实现分词,它有四种分词模式:💨
| 分词模式 | 特点 |
|---|---|
| 精确模式 | 试图将句子最精确地切开,适合文本分析; |
| 全模式 | 把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义; |
| 搜索引擎模式 | 在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词; |
| paddle模式 | 利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词; |
jieba也支持自定义词典(dict.txt),可以添加未包含在jieba词库里的词语,jieba在处理自定义词典的词语时不会继续拆分,下面是一个自定义词典:💨

分词后的结果:

代码这样写(Python):
import jieba# 添加自定义词典
jieba.load_userdict("E:\\封存\论文\处理过程\project\prehandler_py\dict.txt")# 对文本进行操作
with open('comments - 拆分短句2.txt', 'r', encoding = 'utf-8') as sourceFile, open('comments-分词.txt', 'a+', encoding = 'utf-8') as targetFile:for line in sourceFile:seg = jieba.cut(line.strip(), cut_all = False) # 精确模式# 分好词之后之间用空格隔断targetFile.write(' '.join(seg))targetFile.write('\n')print('写入成功!')- dict.txt
- comments - 分词.txt
3.2 去停用词
从分词结果可以看到,词语基本上可以被单独的划分出来,例如“外观”、“音质”、“像素”等,但分词后的句子夹杂着许多类似“已经”、“了”、“很”等没有实际意义的文本,这些词语我们称之为停用词,为使高频词统计的结果更加准确,我们对分词后的短句进行去除停用词处理。
本文使用的停用词表结合了四川大学机器智能实验室停用词库、百度停用词和哈工大停用词表,一共包含了2131个停用词。
停用词表 👊
去停用词处理后:(此步骤同时进行分词和去停用词)

代码可以这样写(Python):
import jieba# 加载字典
jieba.load_userdict("E:\\封存\论文\处理过程\project\prehandler_py\dict.txt")# 读取停用词
def stopwordslist(filepath):stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]return stopwordsdef seg_sentence(sentence):sentence_seged = jieba.cut(sentence.strip(), cut_all = False) # 分词stopwords = stopwordslist('E:\\封存\论文\处理过程\stopwords\stopwords.txt') # 加载停用词的路径outstr = ''for word in sentence_seged:if word not in stopwords:outstr += wordoutstr += " "return outstrinputs = open('comments - 拆分短句2.txt', 'r', encoding='utf-8')
outputs = open('comments - 分词、去停用词.txt', 'w', encoding='utf-8')for line in inputs:line_seg = seg_sentence(line) # 返回每行outputs.write(line_seg + '\n')outputs.close()
inputs.close()- stopwords.txt
- comments - 分词、去停用词.txt
3.3 词频统计
分词后得到的词语数量庞大,分别统计每一个词语的数量可以直观地看出消费者更关注哪些产品特征,本文只取数量在前300名之内的词语亦即消费者更关注的前300个特征进行分析。
以下是在分词和去停用词处理后进行词频统计的结果:🐥

统计词频的代码可以这样写(Python):(分词、去停用词、词频统计同时进行)
import jieba# 加载字典
jieba.load_userdict("E:\\封存\论文\处理过程\project\prehandler_py\dict.txt")# 读取停用词
def stopwordslist(filepath):stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]return stopwordscounts = {}
def seg_sentence(sentence):sentence_seged = jieba.cut(sentence.strip(), cut_all = False) # 分词stopwords = stopwordslist('E:\\封存\论文\处理过程\stopwords\stopwords.txt') # 加载停用词的路径outstr = ''for word in sentence_seged:if word not in stopwords:outstr += wordoutstr += " "if len(word) == 1:continueelse:counts[word] = counts.get(word, 0) + 1 # 返回指定键的值,如果值不在字典中返回default值return outstrinputs = open('comments - 拆分短句2.txt', 'r', encoding='utf-8')
outputs = open('comments - 分词、去停用词.txt', 'w', encoding='utf-8')
output_count = open('comments - 词频.txt', 'w', encoding='utf-8')for line in inputs:line_seg = seg_sentence(line) # 返回每行outputs.write(line_seg + '\n')items = list(counts.items()) # 字典转列表
items.sort(key = lambda x : x[1], reverse = True) # 降序排列N = 300
for i in range(N):word, count = items[i]output_count.write("{0:<10} {1:>5}".format(word, count) + '\n') # 格式化outputs.close()
inputs.close() 还可以制作词云图(使用ECharts的API):🌵

词云代码可以这样写(wordcloud.html):把echarts.min.js、echarts-wordcloud.min.js和wordcloud.html放到同一目录,直接在浏览器打开wordcloud.html即可。
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title><script src="./echarts.min.js"></script><script src="./echarts-wordcloud.min.js"></script>
</head><body><style>html,body,#main {width: 100%;height: 100%;margin: 0;}</style><div id="main"></div><script>window.onload = function () {var chart = echarts.init(document.getElementById('main'))var maskImage = new Image()maskImage.src = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAMgAAADICAYAAACtWK6eAAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAAFiUAABYlAUlSJPAAABUkSURBVHhe7d0HcFXF/gfwfY4ECb2LVCkClgCRIip9UKSIkKiINAUUGKLSLICCvQAiowNKHVDEEhREBKWIYIl0pCOEUAURARWQKL7//7v+7iMJuTf33nO2nHt+n5k7OXvyHu89nt+7e/bs/vY///1/gkXt559/Funp6dk+586d+98nMzMzW/v8+fMiLi5O5M+fX34C14GfhQsXFtWrVxdVq1aVP6tVqyYKFChA/2lMNw5IBLZs2SLWr18vfvzxx/+F4Y8//qDfqnPFFVfIoCAw1113nUhMTBQlS5ak3zKVOCBBnD17VmzYsEFs3LhR/PDDD2LTpk1awhAuhCUhIUHUqVNH1KtXT1x55ZX0G+YmDkgW6BG++eYb8e2338pg2BSIvCAwDRo0EDfccINo3LgxD8tc4vuAbN++XQYCn9WrV9Ndb8PwKxAUfMqUKUO/YZHyZUAOHDggFixYIEOBoVMsw4M/wtK0aVPRvn17ER8fT79h4fBVQDBsQjA+/fRTcebMGbrrHxUrVpQh6dChg7xmefNFQJYtWyaDgZ9MyF4kEJS6devSXZabmA7I3Llzxbx582TPwXLXqlUrkZycLG6++Wa6w7KKyYB89dVX4p133hFpaWl0h+WlY8eOolu3bqJWrVp0h0FMBWTr1q0yGHjGYJHDAz1Cgk+pUqXorr/FRECOHj0qg/H222/LpRzMGby5R0i6d+9Od/zL8wHBM8akSZPE4cOH6Q5zC1489u/fX/70K88G5NChQzIY8+fPpztMFYRkwIAB1PIXTwaEew39/NqbeCog3GuY57fexDMBWbt2rRg9erTYt28f3WGmNG/eXDz11FOidOnSdCd2eSIgixcvFsOGDaMWs8HVV18tRo0aJX/Gskvop7UwfcvhsM+2bdtESkqKfCkby6zuQQYNGiSWLl1KLWYr9CRYrhKLrA3IjTfeKH7//XdqMdvhwR0P8LHGyoBgKvHPP/+kFvOKHj16xNxw2LpnEMyQcDi8adasWXKmMZZY1YO0a9dO7N+/n1rMqzACwPsqLH70OmsCctddd8n94Sw2FCtWTK548Hp5IiuGWL169eJwxJiTJ0/K4fLOnTvpjjcZ70GGDh0qPv/8c2qxUIoUKSJn91CpBBub8CYbn2PHjsnPjh07xHfffSeLUfz222/07zLv448/lmWJvMhoQF555RW5h4Pl7c477xR9+/YV5cqVozvBISwffvih3HKM0qg2QEklL9bqMhaQmTNnirFjx1KLBYNeAzNDrVu3pjvh27Nnj+yhd+/eTXfMqVSpkli4cCG1vMNIQJYvXy4efvhharFgateuLadOL7vsMroTnXvvvVeWTzUNhSEwu+Ul2h/SUfj5hRdeoBYLBlOlH3zwgeNwwOzZs63Yx/H111+LF198kVreoD0gEydOlHvIWXBly5YVzzzzDLXcgT/PhinXd999V368QmtA5syZw4sPw4CCCRUqVKCWO/DnoVCcDdCLrFmzhlp20xaQvXv3irfeeotaLBg8d+CZQQVbAgJeeRbRFpA333xTHD9+nFosGByQky9fPmq566qrrpKFrG2AHgTDbdtpCQheFH322WfUYqEgICqhyrst0IvYPtRSHhC8qELvwcKDb3mVrr/+erqyg+1DLeUBwRQjl+cJn+pCCLYVWrB9qKU0IHiD66UpPRv4LSBg81BLaUDQe/Dmp8ioXjuFdVo2wj8rNlIWkHXr1onU1FRqsXCpfolqa0BwuBGO2LaNsoDgpSAL33333SdP2FU9i2XDmqxgcAqYbZQEZOXKlbzHIwzFixeXRQ42b94sBg8eLFfuqoYQ2uqTTz6RL5RtoiQg/M4jtJo1a4oxY8bILxJUAslJ1TALwyuUcLVVZmamDIlNXF/ujj0InTt3Fv/88w/dMQMFA3AQTPny5eXPggULym8nfEzV98Vy7379+ok6derQnexWrVoly6xiUSF6FLdhOtX29w440x3PruhdbeB6QF5//XUxefJkaukVODwfP0PVjMV2VAQZww2UzsRWVZXwhYH9LyVKlKA7F2CWD6FYtGiR3CobgL9D/G9xy08//SQXQdqywzAUDDtz61lNcDUg+D+7U6dO4uDBg3RHDyzCu+eee6J+wP3+++9lULBN1a1p6UsuuURukR04cCDdyQ5HOSAU+OzatYvuXoD9G9OnT6eWcyNGjLBu+BIMhqC2zIC6GpCPPvpI1mnVBVUzEAwUMnADpqZffvllRxVWLr/8chkKnBqbm02bNslQ4KDRU6dO0d3cYUj20ksviaJFi9Kd6HhhaJXTG2+8IZo1a0Ytc1wNSJ8+feS3sQ633HKLGDduHLXcFc23bUJCghgyZIhITEykO9lhnh/BiHR2Dwf9P//883JPd6QyMjLkF5aN7xfygiIVOIPENNcCgjH9HXfcQS212rZtK7/pVULQEfi8oJjCE088kesSDjzrIBSY30fPES2UzEFhPfRK8fHxdDc0DBenTJkinz28CA/r6GVNV0JxLSC6hlf4h1ZXwQf8w/3oo49SK7vevXuLRx55hFrZpaeny6luHBV35MgRuuscepHbb79dLlmvWLGiKFSoEP3mXyjbin3fmA3DT6/DVHibNm2oZYZrAUE4EBKV0EM9++yz1NIj6/gd32aPP/64nJXKDRbcYWiGYLj01xoSamRhKy1mpn755Rdx+vRp+k1saN++vfEiD64F5NZbb1W6rB1je0x9miiIjF4EQ5z69evTnezQW2BTWFpaGt1hbsAwa8mSJXJG0BRXAqLj+QPf4pjVsQW+sdFT4BNseUTlypXFNddcI6uUYOk//p54b0xkUGAw2MSHDq4E5P333xfPPfcctdyn46E8XDibD1XL8Tl79izdzQ7TzziSLLdpSgxD8TIVAWN5w3MenvdMcaXvQsFklfCuwzR88z/00EPi7rvvliuVg4UDleoRgGBz+Hh+QUhatGhBd1gophdXuhIQfKuqgmcbvAswDeu58iq8hp4O70LygnVGXbt2pRYLBRMfZ86coZZ+jgOCgzZVzrWbHH/mhAf1UHBCVriwXiwpKYlaLBSTLzodBwS1dlXCnL8tUNStUaNGciYNJyhhmrVq1aryQRzVQiL97+rWEplYh3Vrpjh+SMd4XFUxarxBxvRprMJ7C1sKudkMz3XhDF1VcNyD5LYS1S2qa0SZhj0qNlRdt53JHsTqIZbbBZzdgiXxJ06ckM9eeAeC1b/RjJPxZ9heWdAGurdPZGV1D2JrQPCtj+cNrCjG2ig8vPfs2ZN+Gz7sQWF582wPgj3Ewd4HuMHWgAQT6Vo0LmwRHqyKNjXV6ygg586doys1THatwWDFbDA4EerXX3+lVmhY1BgLK251MbXywFFAVFdN9FpAtm7dKp588sk8i7N9+eWXXNA7QqYK3nEPEqFQAQGU8unSpYtcJo/FiVnheQ3Lt7Fk5cCBA3SXhcPU2TJW9yAqJwCiFc4DI/ZnYPUxVji3atVKriVr2LChfHPOxbyj48khluoeBEvEbetFIl1Wg7Bs2bJF6WSGH2BK3ASrAwIYstgC42Ane8tZ9P7++2+60stRQHTs9LKpIgcKIXih8Fos8mRA3DjkPi94V7Bx40ZqmYPeY+7cudRiunkyIHFxcXSllg1HKXDvYZYnA6KrgAKKIph8qca9h3ncg+QBRdB0TArkBud2oPAz9n8wM/766y+60sv6Z5AAPKyrLAwRCnpKnACFt994Ccj04x4kDKgkMmHCBGqphwqFWQtMY/cg6vbaVoLIDzzZg5go4jZ16lTx2GOPUUudGTNmiAEDBsgg5KyMHriHsCA0TD1P9iCgc5gVgId2lVswsY7q1Vdfpda/bez/yHm0HIZb2BKM4ZeJLws/4YBE6IsvvhApKSnZTmVyChXdUagsZ48BWOqAnqt79+5y1W4AXpbiuDTsBUGld6aGqYA4LtqguiZvOJyeMIVTZrGXA8844cJOQhx7kLPCOgqdoXBc1hAx57DYc9q0adTSx3FAcGYFyv3bINwzCgF7yZcvXy4/Ts4ORy/2wAMPUOsClGPFKUknT56kO8wJFO4zsQPTcUBQilNlZcVo4Zkg6ym3+KbHyuDAB9s43YI/H8Ms9KY5jR07VhZgzgqH4KBiCz44DRh/fzb+Hdpm9erV2g/UcRwQFCvw4hFfKqDnwuRBrVq16M6/cIgOzhrEMWw4EAYHAOXcb49nKRwpZ+MeGFtgydG1115LLT0cBwTjcByVxS5AlZOhQ4de9G2HEj951cEaP368q6fbxhIcnqTrmL8Ax7NYVapUoSsWgAd+PAvNmjWL7vwrnCJxgwYNkuWE2MVMPOs6DggOiWEXO3/+vDxjD5MYK1asoLvhwVQyuxh2mOrGAVEM33rBDgINBjNwl156KbVYgJvvvMLFAdGgWrVqdBUerHGrUaMGtVgAemW8INbJcUAwZYnDFllw0VR/MVXmxnaYCdTJcUCAe5HQwq22GICaWbx7MXeqj/vLyZWARLvEwy8QkHXr1lErb1hmz3KHNXE6exEOiCYjR46kq9BQudH04fm203kevSsBSUhIoCsWDJa3dOrU6aJypFnhATSScw79Cj2Irmc0x2/SA1Bik8fN4enfv7881xDTuViLhWJ0eFeyYMEC+lewvARbJOo21wKCN8BLly6lFmNqYREqViygoIZKrgyxgJ9DmE4oIq6jFBMHhHkWdnGqLgruWkCwEI/3ZTOdMjIyIj72LlKuBQSaNGlCV4zpgWGWyv3qrgbkpptuoivG9MAx5Cp7EVcDkpiYSFeM6ZOamqrsFFxXA4IiathnzZhO27dvl7WbVXA1IFC/fn26YkwfVNyMZL1buFwPCA+zmCkIidtcDwge1EuXLk0txvTBGTI56wA45XpAUH+qRYsW1GJML9QBcLMMlesBAQ4IM+nBBx8UmZmZ1HJGSUBwPEDNmjWpxZhe2OKME8HcoCQgwL0IMwlTv25sPFMWkJYtW9IVY2YsXLiQrqKnLCC1a9eWtWoZMwXH56HcqxPKAgJcQpN5ndKAJCUl8dITZpTT2tFKA4LjyRASxkzA3n+nL61d25MeDKbccBwATnRiTIdSpUqJvn37iq5du9Kd6CntQQCHfHbu3JlajKlTqVIlGQqc6OVGOEB5DwI47gy9CDbaM+YUakGjlwj8xDAKL6dV1GfTEhCYPHmyPP2VMSdwmvHw4cOppZ7yIVYAHtZ5lS9zKjk5ma700BaQkiVLyhNxGYsWThPW/dpAW0AA3SMepBiLBk4I1k1rQFAmskuXLtRiLDLhHILqNq0BAfQiWKfFWCTy5cun/Yx00B4QHE7JvQiLFCrhFytWjFr6aA8I4MUhF3dgkUBATDASEMBQi7FwmRhegbGAYEaCa/mycJkacRgLCPTs2ZOuGAsO7z8qVKhALb2MBqRRo0aid+/e1GIsdybPnjEaEMCy5Fq1alGLsYuZnNAxHpCCBQvKkDAWDA48NcV4QAB713UvQmPegSXtplgREEAvgocxxnLCvg9TrAkIwsFDLZab06dP05V+1gQEMMziUkEsp2PHjtGVflYFBHjal+V08uRJutLPuoBgzQ0/sLOsTD6bWhcQ4CooLKBGjRqifPny1NLPyoDgzSmv9mXQr18/ujLDyoBAs2bN6Ir5Ud26dcW4ceOMT9poK/sTqd27d4tOnTpRi8W61q1byw1RxYsXl6u8ERAbWNuDVK9eXR4IyvwhPj5e3HbbbSIlJcWacIC1AQGs9mX+MH/+fHH//ffLjXSpqal01zyrA4IZDOYvW7ZsEU8//bSsobZp0ya6a47VATG5D4CZtW3bNtGnTx959rlJVgekaNGiXGjOx3B0RlpaGrXMsDogULFiRbpifoSexCTrA4INVcy/TB8nbn1AChUqRFfMb8qVK2f8pGTuQZi1Ro4caXwmk3sQZqUhQ4aIpk2bUssc6wPC/KdDhw6iV69e1DKLA8KsUqBAAflG3RYcEGaVbt26yXV4tuCAMKvYVpOAA8KsUbhwYeuqbFofkF27dtEVi3U2lqC1PiB79uyhK8b0szogZ86cERkZGdRiTD+rA8LDK385d+4cXdnD6oDs3buXrpgfmCwQF4zVAdm8eTNdMT84deoUXdnD2oCkp6fLfcrMPzggEZg3b57IzMykFvMD7CC1jZUBOXr0qAwI8xcOSJimTZsmTpw4QS3mFygcZxvrAoLnjjlz5lCL+Um9evXoyh5WBQTlRsePH08t5jc2Hp5kVUAQjuPHj1OL+UlCQoL82MaagEycOFGsXLmSWsxvBg4cSFd2sSIgq1atEpMmTaIW85vhw4eLxo0bU8suVhx/gILFqMnK/APlfBo2bCgLlNs4tAowHpClS5eKQYMGUYuZgnMAq1SpIipXrqxkuhV/Po5SC/z0CuMBGTNmjJg1axa1mC758+eXBxS1bdtWBgMH17CLGQ8Ieg/0IkwPBAHBwAfBYKEZf0i3cYFarEpKSpKH0+BLicMRHqvegzB1EIrRo0eLMmXK0B0WDuMBqVatGl0xFRCI5cuXW1WMzUuMB6RBgwZ0xdyGv9tly5aJ0qVL0x0WKeMBad68OY+HFUA4pk+fTi0WLeMBiYuLk8f/MvdgVexrr71GLeaEFQ/pAwYMEP3796cWc6JEiRJixIgRokiRInSHOWFFQIBD4o7BgweLmjVrUos5ZU1AIBASfqsbna5du4qOHTtSi7nBisWKOR08eFDuKnzvvfe4cEOY8NwxZcoUuYSEucfKgATs3LlThgRvf1lo2E/TpEkTajG3WB2QgPXr18seZfHixXSHZdWmTRu56JO5zxMBCcDGKgQFP9kFM2fOFImJidRibvJUQALQkyAo6Fn8Ljk5WYwaNYpazG2eDEgAnk0WLVokVq9eTXf8Z8aMGaJ+/frUYm7zdEACNmzYIJYsWSLXHR0+fJjuxj5sV506dSq1mAoxEZCAs2fPyqDgs2LFCrobuzC0whCLqRNTAckKh+8gKNitiIJ0sQbL2FG/GAdfMnViNiBZYeiFoCAwNp5iFI0ePXqIYcOGUYup4ouABBw6dEikpaXJZ5aNGzeKffv20W+8Z/bs2VaXy4kVvgpITjt27JBTxQgMPjh2wQtatmwpJkyYQC2mkq8DkhMCs2bNGrF27VoZHBvPzMMzB94BoX4VU48DEkIgMPv375e9y5EjR+TH1NklqGHVrl070bRpU7rDVOOARAErjAOBwc+s19GECMv7sW8cM1NZf5YtWzZbm+kmxP8B65khCA2jcQoAAAAASUVORK5CYII="chart.setOption({series: [{type: 'wordCloud',// 要绘制的“云”的形状。// shape: 'circle',// 保持maskImage的纵横比keepAspect: true,// 其中白色区域将被排除绘制文本。maskImage: maskImage,// 用于定位词云。left: 'center',top: 'center',// width: '80%',height: '100%',right: null,bottom: null,// 将映射到的文本大小范围。默认为最小 12px 和最大 60px 大小。sizeRange: [12, 60],// 文本旋转范围和步长。文本将在 [-90, 90] 范围内通过 rotationStep 45 随机旋转rotationRange: [-90, 90],rotationStep: 45,// 用于标记画布可用性的网格大小(以像素为单位),网格尺寸越大,单词之间的差距越大。gridSize: 8,// 设置为 true 以允许在画布之外部分绘制单词。drawOutOfBound: false,// 是否执行布局动画。注意当有很多单词时禁用它会导致 UI 阻塞。layoutAnimation: true,// Global text styletextStyle: {fontFamily: 'sans-serif',fontWeight: 'normal',// Color can be a callback function or a color stringcolor: function () {// Random colorreturn 'rgb(' + [Math.round(Math.random() * 160),Math.round(Math.random() * 160),Math.round(Math.random() * 160)].join(',') + ')';}},emphasis: {focus: 'self',textStyle: {shadowBlur: 10,shadowColor: '#333'}},// Data is an array. Each array item must have name and value property.data: [{ "name": "拍照", "value": 9595 },{ "name": "外观", "value": 8495 },{ "name": "运行", "value": 8408 },{ "name": "屏幕", "value": 7887 },{ "name": "流畅", "value": 5993 },{ "name": "外形", "value": 5215 },{ "name": "音效", "value": 4798 },{ "name": "好看", "value": 4550 },{ "name": "性价比", "value": 4427 },{ "name": "手感", "value": 4095 },{ "name": "充电", "value": 4051 },{ "name": "清晰", "value": 3626 },{ "name": "待机时间", "value": 3129 },{ "name": "物流", "value": 2468 },{ "name": "系统", "value": 2459 },{ "name": "颜色", "value": 2305 },{ "name": "漂亮", "value": 2245 },{ "name": "颜值", "value": 2188 },{ "name": "价格", "value": 2184 },{ "name": "像素", "value": 2001 },{ "name": "性能", "value": 1694 },{ "name": "特色", "value": 1626 },{ "name": "很漂亮", "value": 1543 },{ "name": "质量", "value": 1495 },{ "name": "音质", "value": 1485 },{ "name": "游戏", "value": 1340 },{ "name": "玩游戏", "value": 1336 },{ "name": "打游戏", "value": 1320 },{ "name": "快递", "value": 1299 },{ "name": "电池", "value": 1297 },{ "name": "骁龙", "value": 1273 },{ "name": "870", "value": 1195 },{ "name": "配置", "value": 1189 },{ "name": "功能", "value": 1172 },{ "name": "包装", "value": 1139 },{ "name": "续航", "value": 1040 },{ "name": "处理器", "value": 1039 },{ "name": "发货", "value": 995 },{ "name": "内存", "value": 982 },{ "name": "曲面", "value": 957 },{ "name": "888", "value": 957 },{ "name": "质感", "value": 945 },{ "name": "发热", "value": 928 },{ "name": "活动", "value": 873 },{ "name": "耳机", "value": 856 },{ "name": "大气", "value": 836 },{ "name": "客服", "value": 820 },{ "name": "价位", "value": 752 },{ "name": "轻薄", "value": 712 },{ "name": "声音", "value": 702 },{ "name": "不卡", "value": 691 },{ "name": "实惠", "value": 677 },{ "name": "做工", "value": 672 },{ "name": "摄像头", "value": 646 },{ "name": "显示", "value": 637 },{ "name": "品牌", "value": 631 },{ "name": "时尚", "value": 591 },{ "name": "618", "value": 588 },{ "name": "设计", "value": 580 },{ "name": "视频", "value": 572 },{ "name": "便宜", "value": 567 },{ "name": "256", "value": 566 },{ "name": "耐用", "value": 564 },{ "name": "优惠", "value": 564 },{ "name": "相机", "value": 556 },{ "name": "扬声器", "value": 556 },{ "name": "服务", "value": 552 },{ "name": "指纹", "value": 545 },{ "name": "王者", "value": 531 },{ "name": "双十", "value": 518 },{ "name": "不卡顿", "value": 515 },{ "name": "卡顿", "value": 512 },{ "name": "时间", "value": 511 },{ "name": "妈妈", "value": 492 },{ "name": "送货", "value": 471 },{ "name": "正品", "value": 468 },{ "name": "充电器", "value": 467 },{ "name": "一亿", "value": 460 },{ "name": "到货", "value": 449 },{ "name": "老婆", "value": 447 },{ "name": "大小", "value": 447 },{ "name": "细腻", "value": 439 },{ "name": "照片", "value": 437 },{ "name": "划算", "value": 430 },{ "name": "色彩", "value": 422 },{ "name": "屏幕显示", "value": 416 },{ "name": "顺畅", "value": 410 },{ "name": "机身", "value": 403 },{ "name": "照相", "value": 396 },{ "name": "黑色", "value": 391 },{ "name": "蓝色", "value": 375 },{ "name": "防抖", "value": 371 },{ "name": "耗电", "value": 371 },{ "name": "刷新率", "value": 366 },{ "name": "精致", "value": 359 },{ "name": "白色", "value": 356 },{ "name": "自营", "value": 353 },{ "name": "高端", "value": 348 },{ "name": "待机", "value": 343 },{ "name": "旗舰", "value": 340 },{ "name": "美观", "value": 340 },{ "name": "不卡", "value": 339 },{ "name": "电量", "value": 338 },{ "name": "灵敏", "value": 331 },{ "name": "自带", "value": 330 },{ "name": "外放", "value": 329 },{ "name": "软件", "value": 324 },{ "name": "顺滑", "value": 323 },{ "name": "外观设计", "value": 318 },{ "name": "服务态度", "value": 315 },{ "name": "开机", "value": 312 },{ "name": "音乐", "value": 306 },{ "name": "家人", "value": 300 },{ "name": "国货", "value": 297 },{ "name": "上档次", "value": 296 },{ "name": "芯片", "value": 295 },{ "name": "5G", "value": 293 },{ "name": "国产", "value": 281 },{ "name": "分辨率", "value": 279 },{ "name": "重量", "value": 276 },{ "name": "高刷", "value": 271 },{ "name": "背面", "value": 267 },{ "name": "美颜", "value": 267 },{ "name": "丝滑", "value": 266 },{ "name": "老爸", "value": 266 },{ "name": "品质", "value": 261 },{ "name": "信号", "value": 261 },{ "name": "评论", "value": 259 },{ "name": "后盖", "value": 258 },{ "name": "120hz", "value": 258 },{ "name": "实用", "value": 257 },{ "name": "态度", "value": 257 },{ "name": "丝滑", "value": 256 },{ "name": "小哥", "value": 255 },{ "name": "画质", "value": 254 },{ "name": "老人", "value": 254 },{ "name": "解锁", "value": 249 },{ "name": "画面", "value": 242 },{ "name": "散热", "value": 239 },{ "name": "稳定", "value": 236 },{ "name": "家里", "value": 235 },{ "name": "老公", "value": 235 },{ "name": "光学", "value": 233 },{ "name": "老妈", "value": 230 },{ "name": "升级", "value": 230 },{ "name": "款式", "value": 224 },{ "name": "音响", "value": 222 },{ "name": "清晰度", "value": 218 },{ "name": "无线", "value": 215 },{ "name": "图片", "value": 214 },{ "name": "牌子", "value": 213 },{ "name": "反应速度", "value": 207 },{ "name": "夜景", "value": 206 },{ "name": "爸爸", "value": 201 },{ "name": "配色", "value": 198 },{ "name": "机型", "value": 196 },{ "name": "孩子", "value": 191 },{ "name": "材质", "value": 186 },{ "name": "礼物", "value": 184 },{ "name": "镜头", "value": 179 },{ "name": "大方", "value": 177 },{ "name": "磨砂", "value": 170 },{ "name": "直屏", "value": 164 },{ "name": "价钱", "value": 160 },{ "name": "实体店", "value": 155 },{ "name": "边框", "value": 155 },{ "name": "版本", "value": 155 },{ "name": "玻璃", "value": 152 },{ "name": "电池容量", "value": 152 },{ "name": "赠品", "value": 151 },{ "name": "同价位", "value": 151 },{ "name": "贴膜", "value": 148 },{ "name": "售后", "value": 148 },{ "name": "亮度", "value": 147 },{ "name": "国产手机", "value": 146 },{ "name": "女生", "value": 146 },{ "name": "媳妇", "value": 143 },{ "name": "力度", "value": 143 },{ "name": "降价", "value": 142 },{ "name": "同事", "value": 140 },{ "name": "细节", "value": 137 },{ "name": "后置", "value": 136 },{ "name": "学生", "value": 135 },{ "name": "尺寸", "value": 133 },{ "name": "粉丝", "value": 132 },{ "name": "立体", "value": 131 },{ "name": "网速", "value": 131 },{ "name": "实物", "value": 129 },{ "name": "网络", "value": 129 },{ "name": "素质", "value": 128 },{ "name": "电影", "value": 127 },{ "name": "技术", "value": 121 },{ "name": "弟弟", "value": 120 },{ "name": "喇叭", "value": 120 },{ "name": "前置", "value": 119 },{ "name": "女朋友", "value": 116 },{ "name": "眼睛", "value": 114 },{ "name": "触感", "value": 113 },{ "name": "父母", "value": 112 },{ "name": "硬件", "value": 110 },{ "name": "备用机", "value": 106 },{ "name": "儿子", "value": 105 },{ "name": "观感", "value": 104 },{ "name": "原装", "value": 103 },{ "name": "骁龙", "value": 103 },{ "name": "音量", "value": 103 },{ "name": "刷屏", "value": 101 },{ "name": "后壳", "value": 99 },{ "name": "人性化", "value": 97 },{ "name": "年轻人", "value": 96 },{ "name": "工艺", "value": 95 },{ "name": "官方", "value": 95 },{ "name": "价格便宜", "value": 95 },{ "name": "金属", "value": 93 },{ "name": "功耗", "value": 92 },{ "name": "温度", "value": 92 },{ "name": "平台", "value": 92 },{ "name": "橙色", "value": 91 },{ "name": "外壳", "value": 90 },{ "name": "广告", "value": 88 },{ "name": "屏下", "value": 88 },{ "name": "角度", "value": 87 },{ "name": "火龙", "value": 87 },{ "name": "幻境", "value": 87 },{ "name": "神速", "value": 86 },{ "name": "女孩子", "value": 86 },{ "name": "科技", "value": 86 },{ "name": "风格", "value": 86 },{ "name": "界面", "value": 85 },{ "name": "盒子", "value": 85 },{ "name": "塑料", "value": 83 },{ "name": "音响效果", "value": 82 },{ "name": "通话", "value": 80 },{ "name": "新款", "value": 79 },{ "name": "厚度", "value": 78 },{ "name": "包装盒", "value": 77 },{ "name": "造型", "value": 76 },{ "name": "空间", "value": 75 },{ "name": "长辈", "value": 74 },{ "name": "绿色", "value": 72 },{ "name": "钢化", "value": 71 },{ "name": "水桶", "value": 71 },{ "name": "微距", "value": 70 },{ "name": "光线", "value": 68 },{ "name": "原神", "value": 68 },{ "name": "热情", "value": 66 },{ "name": "妹妹", "value": 66 },{ "name": "运存", "value": 66 },{ "name": "渐变色", "value": 65 },{ "name": "父亲", "value": 65 },{ "name": "档次", "value": 64 },{ "name": "现货", "value": 64 },{ "name": "容量", "value": 63 },{ "name": "主打", "value": 62 },{ "name": "样式", "value": 62 },{ "name": "系统优化", "value": 62 },{ "name": "原生", "value": 62 },{ "name": "同学", "value": 61 },{ "name": "英寸", "value": 60 },{ "name": "老人家", "value": 60 },{ "name": "拍照片", "value": 59 },{ "name": "经典", "value": 59 },{ "name": "扫码", "value": 59 },{ "name": "音箱", "value": 58 },{ "name": "配件", "value": 57 },{ "name": "触屏", "value": 56 },{ "name": "女儿", "value": 56 },{ "name": "柔性", "value": 56 },{ "name": "情怀", "value": 56 },{ "name": "亮眼", "value": 55 },{ "name": "全家", "value": 55 },{ "name": "动画", "value": 55 },{ "name": "秒杀", "value": 55 },{ "name": "官网", "value": 54 },{ "name": "按键", "value": 54 },{ "name": "参数", "value": 52 },{ "name": "优惠券", "value": 52 },{ "name": "无线耳机", "value": 51 },{ "name": "杂音", "value": 51 },{ "name": "单手操作", "value": 51 },{ "name": "短板", "value": 51 },{ "name": "代言", "value": 50 },{ "name": "素皮", "value": 50 },{ "name": "麒麟", "value": 50 },{ "name": "银色", "value": 49 },{ "name": "直播间", "value": 49 },{ "name": "新品", "value": 49 },{ "name": "圆润", "value": 49 },{ "name": "分量", "value": 49 },{ "name": "礼品", "value": 49 },{ "name": "模组", "value": 49 },{ "name": "饱和度", "value": 48 }]}]})}</script>
</body></html>
- comments - 词频.txt
- 词云依赖包
3.3 词频统计优化
从上面的词频统计结果可以看到,去停用词后直接进行词频统计,得到的结果混杂了许多不属于手机特征的词语(下文称非特征词),包括词频位于前三的“手机”、“不错”、“速度”,在笔者看来,这些词语均属于非特征词。
例如“手机”,虽然它是一个名词,但其并不是描述手机特征的词语,它代表手机本身;例如“不错”,它是一个形容词,不在手机特征范畴;又如“速度”一词,它可以指物流速度,也可以指系统流畅度,这类模棱两可的词语我们也是不需要的,原因是在出现这些词语的地方,正确的句法里应会存在着一个更合适的具体的特征词。例如我们可以在拆分短句后的原始评论中搜索“速度”,以下是原始评论中最前面的两条包含“速度”的短句:
“宝贝已经收到了,试用了一段时间,运行平稳,速度还不错!”
“运行速度:完美”
可以看到,两条短句都包含了更合适的具体的特征词——“运行”,所以我们可以保留“运行”而不是使用泛指的“速度”。
对于上面提及的三个词语以及没有罗列出来的非特征词,可以采取不同的处理方式。查看3.2词频统计步骤得出的前300个高频词,可以发现本身为名词但并不是特征词的“手机”,以及代表泛指的“速度”这两类词在统计出来的前300个高频词中数量并不多,前300个高频词中的非特征词里更多的是类似“不错”、“喜欢”等词性为形容词和动词的词语,所以我们对去除停用词后的短句进一步筛选出名词进行词频统计,便可以去除大部分非特征词。
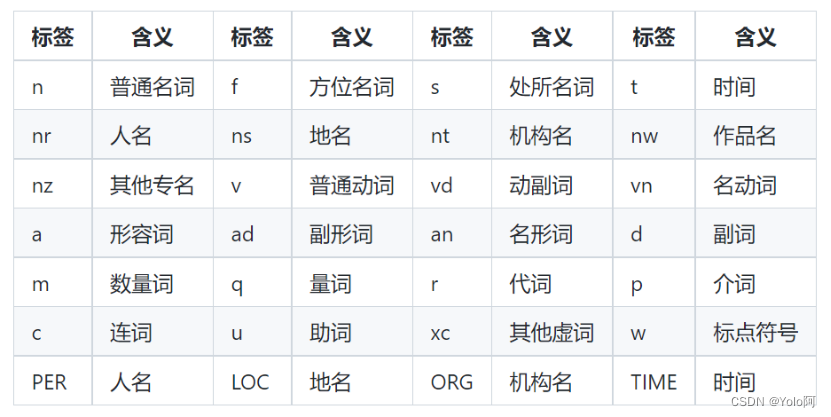
为了筛选出名词,我们需要进行词性标注,词性标注即确定句子中各个词的词性。Python里的jieba库的分词模块同样提供了词性标注功能,该模块可以标注出24个词性标签和4个专名类别标签,如下图所示:
前面提到,去除非名词处理并不能完全清除非特征词,仍会存在一部分像“手机”、“速度”等词性为名词的非特征词,为使结果更加准确,通过人工筛选的方式清除其余的非特征词。另外,jieba的词性标注功能也有一定的误差,例如将名词标注为其它词性,为了使结果更加准确,对3.2词频统计结果和3.3词频统计优化结果进行整合,最终得到数量在前292位的高频特征词(下文称之为高频词)。💥
去除非名词后的的结果:comments - 词频1.txt

代码可以这样写(Python):💢
import jieba
import jieba.posseg as pseg# 加载字典
jieba.load_userdict("E:\\封存\论文\处理过程\project\prehandler_py\dict.txt")# 读取停用词
def stopwordslist(filepath):stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]return stopwordscounts = {}
def seg_sentence(sentence):sentence_seged = pseg.cut(sentence.strip()) # 分词stopwords = stopwordslist('E:\\封存\论文\处理过程\stopwords\stopwords.txt') # 加载停用词的路径outstr = ''for word in sentence_seged: # 每个词if word.word not in stopwords:outstr += word.wordoutstr += " "if len(word.word) == 1 or word.flag != 'n':continueelse:counts[word.word] = counts.get(word.word, 0) + 1 # 返回指定键的值,如果值不在字典中返回default值return outstrinputs = open('comments - 拆分短句2.txt', 'r', encoding='utf-8')
outputs = open('comments - 分词、去停用词.txt', 'w', encoding='utf-8')
output_count = open('comments - 词频1.txt', 'w', encoding='utf-8')for line in inputs:line_seg = seg_sentence(line) # 返回每行outputs.write(line_seg + '\n')items = list(counts.items()) # 字典转列表
items.sort(key = lambda x : x[1], reverse = True) # 降序排列N = 300
for i in range(N):word, count = items[i]output_count.write("{0:<10} {1:>5}".format(word, count) + '\n') # 格式化outputs.close()
inputs.close()然后,通过整合最终得出手机的前292个高频词:comments - 词频整合

再次绘制词云图:🔥

可以看到,词频统计优化后的结果基本上属于手机的特征词,也可以看出消费者对“拍照”、“外观”、“运行”、“屏幕”等产品特征最为关注,这也符合现实生活中的情况。
4 特征词聚类
从上个步骤的词云图可以看出,虽然经过优化后的词频统计得到的结果有明显改善,但仔细观察优化后的版本,前10的特征词里处于第二位的“外观”和第六位的“外形”以及第八位的“好看”,本质上都是描述手机这一个产品的外部特征,即消费者在使用这三个词语评价的时候,表达的都是对同一个产品特征的评价。同样,处于第三位的“运行”和第五位的“流畅”也是表达对系统这一产品特征的评价。
既然统计出来的292个高频词里存在表达意思相同的特征词,那么下一步,我们需要对这292个词语进行分类处理。
显然,手动分类的方式繁琐且不现实,我们可以使用K-means聚类算法实现分类。在本例中,我们希望将292个特征词经过聚类变成若干个特征集合,例如将“外观”、“外形”、“好看”都分到外观这一集合去。
K-means聚类算法是一种通过不断迭代找出最优解的聚类分析算法,K-means聚类需要指定聚类个数K和输入一组数据点,我们可以通过计算轮廓系数获得最佳聚类个数,而文本作为一种非结构化的数据信息,并不能被直接计算,因此我们需要将词转化为词向量,以获得数据点。
自然语言理解转化为机器学习的第一步通常都是将文本信息数学化,通过word2vec我们可以获得某词语的低维实数向量,如:[0.278,0.320,0.197,0.534,0.164,…],向量的每个维度都代表了该词的一个潜在特征,而该特征捕获了有用的句法及语义信息。
我们可以使用使用分词后的评论训练词向量模型——训练集.model,然后从词向量模型中提取292个高频词的向量,来计算最佳聚类个数和进行聚类。
训练词向量模型代码:👽
from gensim.models import word2vec
import logging
import os# 模型训练,生成词向量模型
def model_train(train_file_name, save_model_file):logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) # 日志sentences = word2vec.Text8Corpus(train_file_name) # 加载语料model = word2vec.Word2Vec(sentences, vector_size=100, min_count=5, sg=1) # 训练skip-gram模型,默认window=5,参数参考https://radimrehurek.com/gensim/models/word2vec.html#gensim.models.word2vec.Word2Vecmodel.save(save_model_file) # 保存模型model.wv.save_word2vec_format(save_model_name + ".bin", binary=True) # 以二进制类型保存模型以便重用save_model_name = '训练集.model'if not os.path.exists(save_model_name): # 判断文件是否存在model_train('comments - 分词.txt', save_model_name) # 须注意文件必须先另存为utf-8编码格式
else:print('此训练模型已经存在,不用再次训练。')可以从训练集中输出“手机”一词的词向量:😵
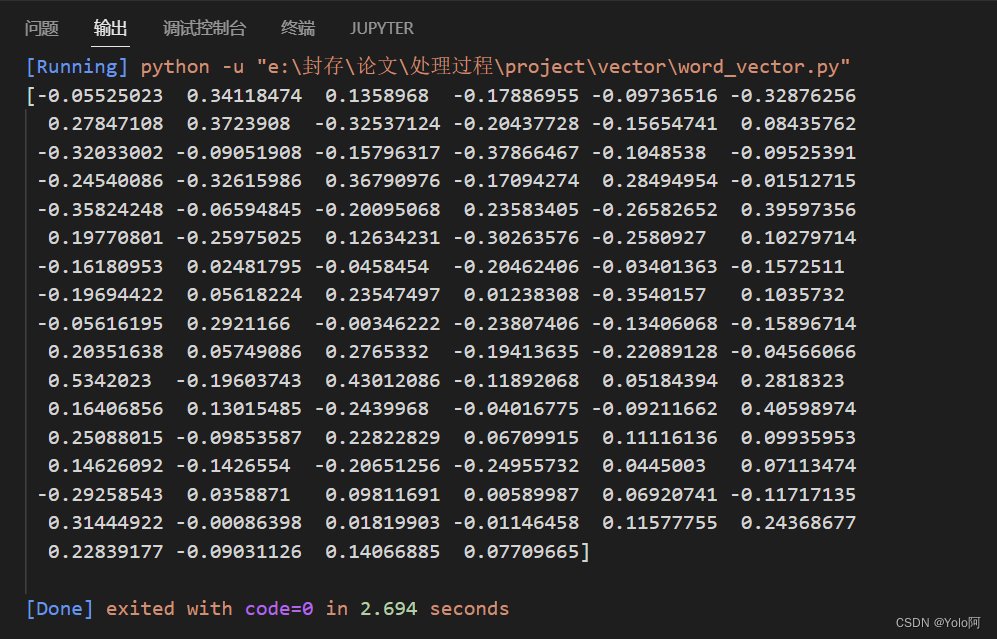
代码是这样写的:💓
from gensim.models import word2vecsave_model_name = '训练集.model'# 加载已训练好的模型
model_1 = word2vec.Word2Vec.load(save_model_name)# 返回词向量
print(model_1.wv.get_vector('手机'))- 训练集.model
4.1 K值计算
得到词向量模型后,我们可以从词向量模型中提取292个高频词的向量,然后计算最佳聚类个数。轮廓系数可以评价聚类效果的好坏,Python的sklearn模块给出了轮廓系数的求解方法,其实现步骤是:事先给定一个聚类簇数区间[2,40](即把292个特征词依次分为2类至40类),然后分别计算这个区间内每个簇数的轮廓系数,结果如下所示:
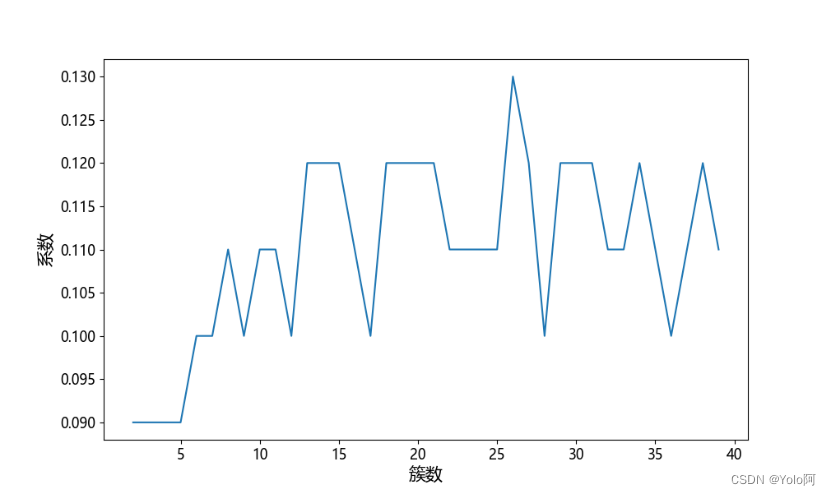
轮廓系数越接近1,表明聚类效果越好,所以K值(聚类个数)我们定为26。
代码可以这样写(Python):
from gensim.models import word2vec
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as pltsave_model_name = '训练集.model'# 加载已训练好的模型
model_1 = word2vec.Word2Vec.load(save_model_name)# 获取指定关键词的词向量
f = open(r"E:\封存\论文\处理过程\project\vector\key.txt", encoding = 'utf-8') # 之前提取的292个高频词line = f.readline()
keys = [] # 关键字数组while line:keys.append(line.strip('\n'))line = f.readline()f.close()wordvector = [] # 词向量数组for key in keys:wordvector.append(model_1.wv.get_vector(key))# 轮廓系数确定簇数,最佳值为1,最差值为-1,接近0的值表示重叠的群集
def silhouette_score_show(data_vec=None, name=None):k = range(2, 40)score_list = []for i in k:model = KMeans(n_clusters=i).fit(data_vec)y_pre = model.labels_score = round(silhouette_score(data_vec, y_pre), 2)score_list.append(score)plt.figure(figsize=(12, 8))plt.plot(list(k), score_list)plt.xticks(fontsize=12)plt.yticks(fontsize=12)plt.xlabel('簇数', fontsize=15)plt.ylabel('系数', fontsize=15)plt.savefig(f'{name}轮廓系数.jpg')plt.show()silhouette_score_show(wordvector, 'word2vec')- key.txt
4.2 聚类
接着,根据292个高频词的词向量模型进行聚类,打印结果如下:
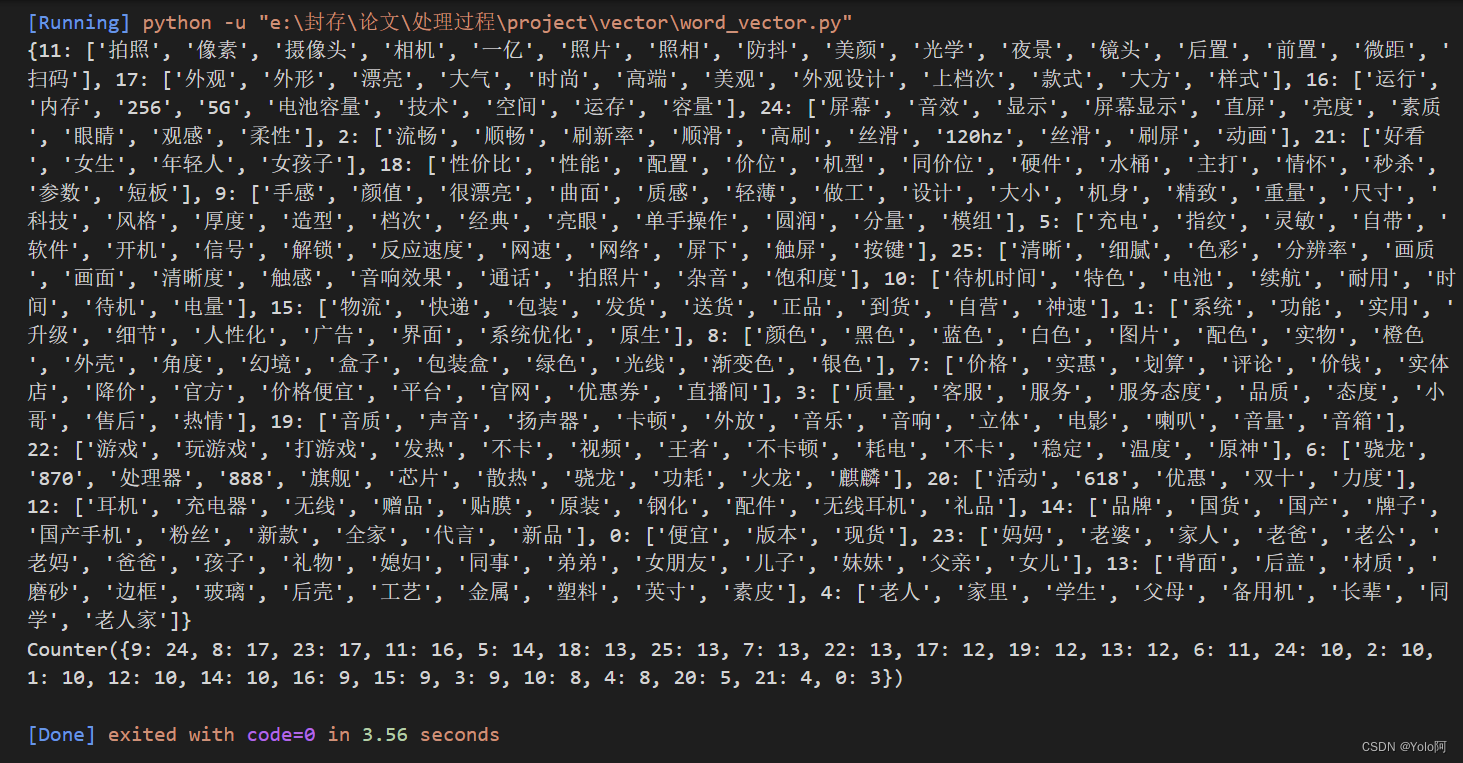
整理后可以得到这样的结果:🎵
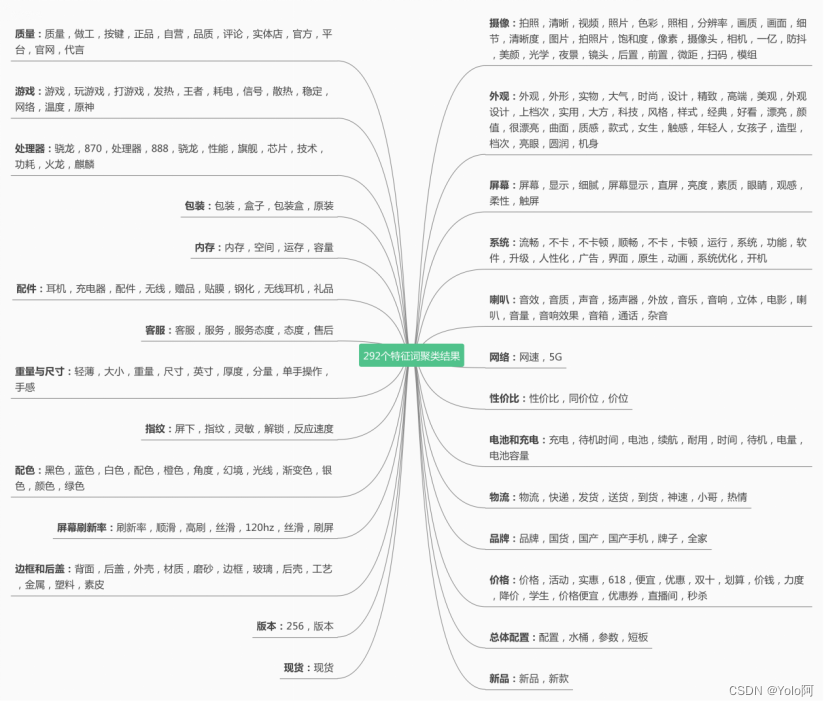
代码是这样写的:🔥
from gensim.models import word2vec
from sklearn.cluster import KMeans
from collections import Countersave_model_name = '训练集.model'# 加载已训练好的模型
model_1 = word2vec.Word2Vec.load(save_model_name)# 获取指定关键词的词向量
f = open(r"E:\封存\论文\处理过程\project\vector\key.txt", encoding = 'utf-8') # 之前提取的292个关键词line = f.readline()
keys = [] # 关键字数组while line:keys.append(line.strip('\n'))line = f.readline()f.close()wordvector = [] # 词向量数组for key in keys:wordvector.append(model_1.wv.get_vector(key))# 聚类
clf = KMeans(n_clusters=26).fit(wordvector)
labels = clf.labels_# 把是一类的放入到一个集合
classCollects = {}
for i in range(len(keys)):if labels[i] in classCollects.keys():classCollects[labels[i]].append(keys[i])else:classCollects[labels[i]]=[keys[i]]print(classCollects)# 统计数量
center_dict = Counter(labels)
print(center_dict)至此,我们得到了手机的27个特征词,可以统计出每个特征词的词频:(值等于每个特征词所包含的高频词的词频之和)👯
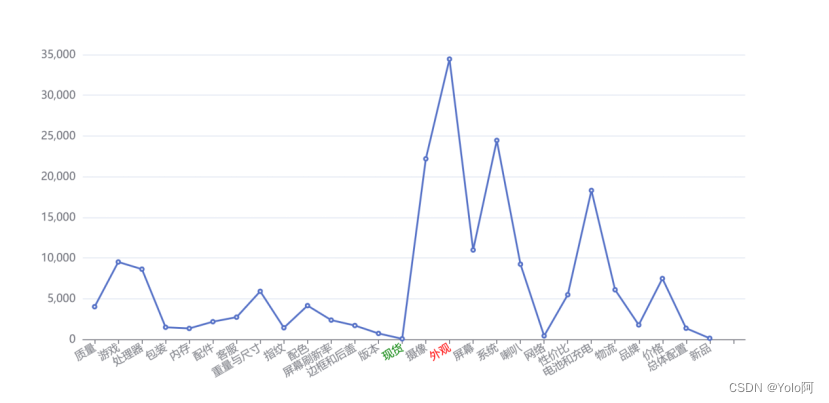
5 情感分析
通过聚类我们得到了手机的27个特征词,那么接下来,我们可以计算27个特征词的情感得分。进行情感分析,我们可以使用Python的snowNLP模块,snowNLP是一个针对中文文本写的自然语言处理库,其自带了针对电商平台评价数据训练好的模型,所以我们可以直接调用SnowNLP的接口计算短句的情感得分,进而得出短句所包含的高频词的情感得分。(短句的情感得分作为短句中所包含高频词的情感得分)
先计算每一个短句的情感得分:⛄️
from snownlp import SnowNLPf = open("comments - 拆分短句2.txt", encoding = 'utf-8')
outputs = open('comments - 情感', 'w', encoding='utf-8')line = f.readline()while line:# 情感得分try:emo = SnowNLP(line.strip()).sentimentsexcept: print('异常')outputs.write(str(emo) + ' ' + line.strip() + '\n')line = f.readline()f.close()
outputs.close()
print('write down.')结果像这样:score.txt

我们的目的是计算27个特征词的情感得分,而特征词是由292个高频词聚类得到的,所以我们首先需要获得每个高频词的情感得分,具体步骤为:(不知道大家能不能看懂🐣,可能会有点绕哈)
- 对于特征词中的每一个高频词,其情感得分为:检索每一条短句,如果短句包含该高频词,那么将这些短句的情感得分平均值作为该高频词的情感得分;
- 将特征词所包含的每一个高频词的情感得分平均值,作为该特征词的情感得分;
代码可以这样写(JS):
// 引入fs模块
let fs = require('fs')let arr1 = [] // ["0.998506036016588 宝贝已经收到了,试用了一段时间,运行平稳,速度还不错!", ...]
let arr2 = [] // ["0.998506036016588", "宝贝已经收到了,试用了一段时间,运行平稳,速度还不错!"]
let arr3 = [] // [["0.998506036016588", "宝贝已经收到了,试用了一段时间,运行平稳,速度还不错!"], [], ...]// 同步读取
let res = fs.readFileSync('./score.txt')
arr1 = res.toString().split('\r\n')for (let item of arr1) {arr2 = item.split(/\s/) // 只有一个空格if (arr2.length > 2) { // 有多个空格let str1 = arr2[0]let str2 = ''let arr4 = []for (let index in arr2) {if (Number(index)) {arr4.push(arr2[index])str2 = arr4.join(' ')}}arr2 = [str1, str2]}arr3.push(arr2) // 得到二维数组
}let obj1 = {"质量": ["质量", "做工", "按键", "正品", "自营", "品质", "评论", "实体店", "官方", "平台", "官网", "代言"],"游戏": ["游戏", "玩游戏", "打游戏", "发热", "王者", "耗电", "信号", "散热", "稳定", "网络", "温度", "原神"],"处理器": ["骁龙", "870", "处理器", "888", "骁龙", "性能", "旗舰", "芯片", "技术", "功耗", "火龙", "麒麟"],"包装": ["包装", "盒子", "包装盒", "原装"],"内存": ["内存", "空间", "运存", "容量"],"配件": ["耳机", "充电器", "配件", "无线", "赠品", "贴膜", "钢化", "无线耳机", "礼品"],"客服": ["客服", "服务", "服务态度", "态度", "售后"],"重量与尺寸": ["轻薄", "大小", "重量", "尺寸", "英寸", "厚度", "分量", "单手操作", "手感"],"指纹": ["屏下", "指纹", "灵敏", "解锁", "反应速度"],"配色": ["黑色", "蓝色", "白色", "配色", "橙色", "角度", "幻境", "光线", "渐变色", "银色", "颜色", "绿色"],"屏幕刷新率": ["刷新率", "顺滑", "高刷", "丝滑", "120hz", "丝滑", "刷屏"],"边框和后盖": ["背面", "后盖", "外壳", "材质", "磨砂", "边框", "玻璃", "后壳", "工艺", "金属", "塑料", "素皮"],"版本": ["256", "版本"],"现货": ["现货"],"摄像": ["拍照", "清晰", "视频", "照片", "色彩", "照相", "分辨率", "画质", "画面", "细节", "清晰度", "图片", "拍照片", "饱和度", "像素", "摄像头", "相机", "一亿", "防抖", "美颜", "光学", "夜景", "镜头", "后置", "前置", "微距", "扫码", "模组"],"外观": ["外观", "外形", "实物", "大气", "时尚", "设计", "精致", "高端", "美观", "外观设计", "上档次", "实用", "大方", "科技", "风格", "样式", "经典", "好看", "漂亮", "颜值", "很漂亮", "曲面", "质感", "款式", "女生", "触感", "年轻人", "女孩子", "造型", "档次", "亮眼", "圆润", "机身"],"屏幕": ["屏幕", "显示", "细腻", "屏幕显示", "直屏", "亮度", "素质", "眼睛", "观感", "柔性", "触屏"],"系统": ["流畅", "不卡", "不卡顿", "顺畅", "不卡", "卡顿", "运行", "系统", "功能", "软件", "升级", "人性化", "广告", "界面", "原生", "动画", "系统优化", "开机"],"喇叭": ["音效", "音质", "声音", "扬声器", "外放", "音乐", "音响", "立体", "电影", "喇叭", "音量", "音响效果", "音箱", "通话", "杂音"],"网络": ["网速", "5G"],"性价比": ["性价比", "同价位", "价位"],"电池和充电": ["充电", "待机时间", "电池", "续航", "耐用", "时间", "待机", "电量", "电池容量"],"物流": ["物流", "快递", "发货", "送货", "到货", "神速", "小哥", "热情"],"品牌": ["品牌", "国货", "国产", "国产手机", "牌子", "全家"],"价格": ["价格", "活动", "实惠", "618", "便宜", "优惠", "双十", "划算", "价钱", "力度", "降价", "学生", "价格便宜", "优惠券", "直播间", "秒杀"],"总体配置": ["配置", "水桶", "参数", "短板"],"新品": ["新品", "新款"]
}// [["0.998506036016588", "宝贝已经收到了,试用了一段时间,运行平稳,速度还不错!"], [], ...]let obj2 = []// 每一个特征词
for (let key in obj1) {let value = obj1[key]let classScore = 0let classN = 0// item:特征词中的每一个高频词for (let item of value) {let score = 0let n = 0// 遍历arr3for (let item1 of arr3) {if (item1[1].indexOf(item) > -1) {score += Number(item1[0])n++}}if (n > 0) {classScore += score / n // 每一个高频词的情感得分classN++}}obj2[key] = classScore / classN // 每一个特征词的情感得分
}console.log(obj2)获得每个特征词的情感得分:🐝
{'质量': 0.8001988613911016,'游戏': 0.8328068700046466,'处理器': 0.9206259082705203,'包装': 0.7446243653468196,'内存': 0.8606755206176194,'配件': 0.7304562836583399,'客服': 0.7413850463524174,'重量与尺寸': 0.8684763363457315,'指纹': 0.8014712886190194,'配色': 0.8997966312328575,'屏幕刷新率': 0.8689830665013788,'边框和后盖': 0.8395039787132342,'版本': 0.8198596845192971,'现货': 0.6576323267151287,'摄像': 0.8694447377114252,'外观': 0.9623818798921722,'屏幕': 0.8378220399511975,'系统': 0.8730660909832209,'喇叭': 0.859654212822756,'网络': 0.8525110175919286,'性价比': 0.9570735256053896,'电池和充电': 0.8121310500793762,'物流': 0.7835370259175152,'品牌': 0.8819576886088969,'价格': 0.821030357019408,'总体配置': 0.8459965298429362,'新品': 0.9029555229440966
}
至此,我们基本上完成了如标题所示的需求类型,当然我们也可以继续扩展,例如进行基于KANO模型的需求分析,感兴趣的朋友们可以研究下哦。🌸
附:
Python爬虫系列教程